
- 1【STM32】配置中断-实例&思路_按键中断的设置流程
- 2Linux - 进程的概念、状态、僵尸进程、孤儿进程及进程优先级
- 3Python实现对MsSqlServer数据库定时自动备份、压缩、上传到minio_python如何自动备份数据库bak文件
- 4DGCNN (Dynamic Graph CNN for Learning on Point Clouds,动态图卷积网络)
- 5SpringBoot之拦截器的配置_拦截器只拦截 restcontroller
- 6机器学习训练算法十二(模型训练算法-Python实验)_python 算法练习
- 7昇思基础课程打卡(SPONGE课前学习)1.快速入门
- 8如何外网访问登录员工管理系统平台_hr 网络安全 应用
- 9【并发编程篇】读锁readLock()和写锁writeLock()
- 10OpenHarmony开发记录-Websocket封装_openharmony websocket
Windows上搭建Kafka运行环境_windows创建kafka3.6.1scram证书--bootstrap server
赞
踩
1.安装JDK
1.1 安装文件 http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html 下载Server JRE
1.2 添加环境变量
1.2.1 添加JAVA_HOME环境变量
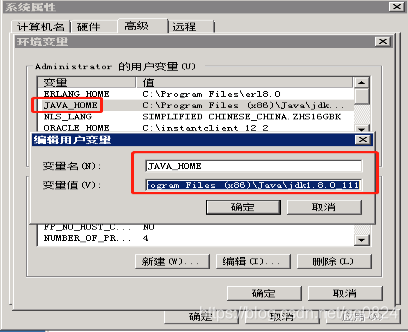
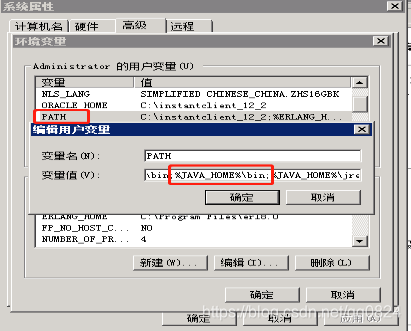
1.2.2 Path环境变量:在现有的值后面添加";%JAVA_HOME%\bin"
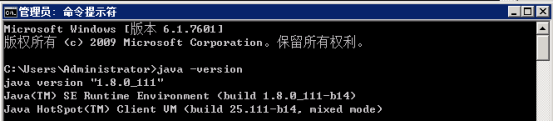
1.3 打开cmd运行 "java -version" 查看当前系统Java的版本
2.安装运行Zookeeper
Kafka的运行依赖于Zookeeper,所以在运行Kafka之前我们需要安装并运行Zookeeper
2.1 下载安装文件 http://zookeeper.apache.org/releases.html
2.2 解压文件(本文解压到C:\kafka\zookeeper-3.4.11)
2.3 打开C:\kafka\zookeeper-3.4.11\conf,把zoo_sample.cfg重命名成zoo.cfg
2.4 从文本编辑器里打开zoo.cfg
2.5 修改数据存储目录dataDir值:dataDir=C:/kafka/zookeeper-3.4.11/data
注意:该目录不需要手动创建,启动zookeeper服务时会自动创建,路径要么是"/"分割,要么是转义字符"\\",这样会生成正确的路径(层级,子目录)。
2.6 添加环境变量
2.6.1 ZOOKEEPER_HOME环境变量
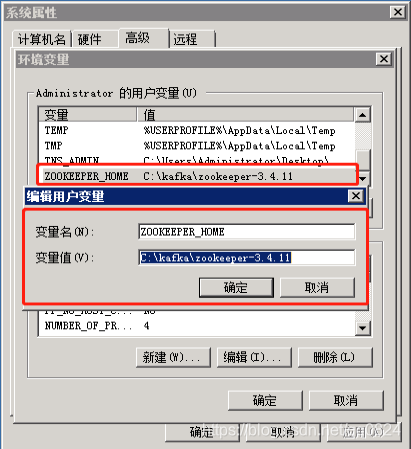
2.6.2 Path环境变量:在现有的值后面添加 ";%ZOOKEEPER_HOME%\bin;"
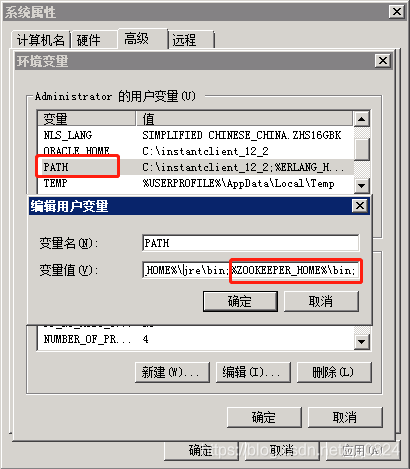
2.7 运行Zookeeper:打开cmd然后执行命令zkserver
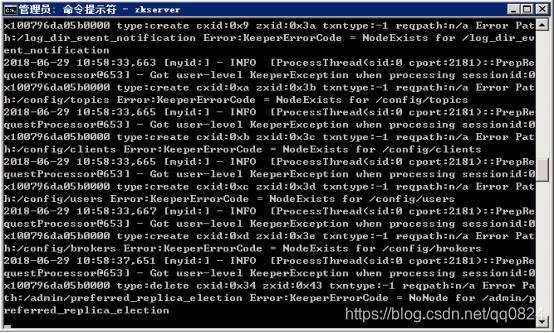
注意:不要关了这个窗口
3.安装运行Kafka
3.1 下载安装文件:http://kafka.apache.org/downloads.html
3.2 解压文件(本文解压到 C:\kafka\kafka_2.12-1.1.0)
3.3 打开 C:\kafka\kafka_2.12-1.1.0\config目录,从文本编辑器里打开 server.properties
3.4 修改数据存储目录log.dirs值
log.dirs=C:/kafka/kafka_2.12-1.1.0/kafka-logs
多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能,如:log.dirs=C:/kafka/kafka_2.12-1.1.0/kafka-logs-1,C:/kafka/kafka_2.12-1.1.0/kafka-logs-2,C:/kafka/kafka_2.12-1.1.0/kafka-logs-3
注意:以上目录不需要手动创建,启动kafka服务时会自动创建,路径要么是"/"分割,要么是转义字符"\\",这样会生成正确的路径(层级,子目录)。
3.5 修改IP地址和端口号(默认9092),IP地址配置为127.0.0.1只对本机有效
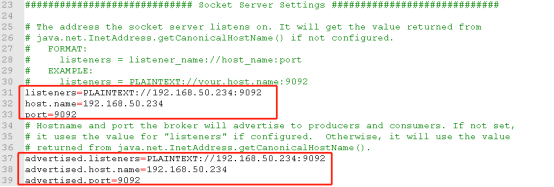
3.6 修改Zookeeper集群地址
zookeeper.connect=192.168.50.234:2181
3.7 其他参数参数:
| 参数 | 参数说明 |
| num.network.threads=4 | 处理消息的最大线程数,一般情况下数量为cpu核数 |
| num.io.threads=8 | 处理磁盘IO的线程数,数值为cpu核数2倍 |
| queued.max.requests=5000 | 等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,应该是一种自我保护机制。 |
| socket.send.buffer.bytes=1024000 | service的发送缓冲区大小,单位是字节 |
| socket.receive.buffer.bytes=1024000 | service的接受缓冲区大小,单位是字节 |
| log.flush.interval.messages=10000 | 每当producer写入10000条消息时,刷数据到磁盘 |
| log.flush.interval.ms=1000 | 每间隔1秒钟时间,刷数据到磁盘,单位为毫秒 |
| log.cleanup.policy=delete | 日志清理策略选择有:delete和compact,主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖 |
| log.cleaner.enable=true | 是否开启日志清理 |
| log.retention.hours=168 | 当kafka broker被写入海量消息后,会生成很多数据文件,占用大量磁盘空间,kafka默认是保留7天,建议根据磁盘情况配置,避免磁盘撑爆。 |
| log.retention.minutes=2 | 保留2分钟 |
| zookeeper.connect=192.168.50.234:2181 | zookeeper集群的地址,可以是多个,多个之间用逗号分割,如: hostname1:port1,hostname2:port2,hostname3:port3 |
| zookeeper.connection.timeout.ms=6000 | Zookeeper的连接超时时间,单位为毫秒 |
| offsets.topic.replication.factor=3 |
|
| transaction.state.log.replication.factor=3 |
|
| auto.leader.rebalance.enable=true |
|
我的server.properties文件配置参数如下:
- # Licensed to the Apache Software Foundation (ASF) under one or more
- # contributor license agreements. See the NOTICE file distributed with
- # this work for additional information regarding copyright ownership.
- # The ASF licenses this file to You under the Apache License, Version 2.0
- # (the "License"); you may not use this file except in compliance with
- # the License. You may obtain a copy of the License at
- #
- # http://www.apache.org/licenses/LICENSE-2.0
- #
- # Unless required by applicable law or agreed to in writing, software
- # distributed under the License is distributed on an "AS IS" BASIS,
- # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- # See the License for the specific language governing permissions and
- # limitations under the License.
-
- # see kafka.server.KafkaConfig for additional details and defaults
-
- ############################# Server Basics #############################
-
- # The id of the broker. This must be set to a unique integer for each broker.
- broker.id=0
-
- ############################# Socket Server Settings #############################
-
- # The address the socket server listens on. It will get the value returned from
- # java.net.InetAddress.getCanonicalHostName() if not configured.
- # FORMAT:
- # listeners = listener_name://host_name:port
- # EXAMPLE:
- # listeners = PLAINTEXT://your.host.name:9092
- listeners=PLAINTEXT://192.168.50.234:9092
- host.name=192.168.50.234
- port=9092
- # Hostname and port the broker will advertise to producers and consumers. If not set,
- # it uses the value for "listeners" if configured. Otherwise, it will use the value
- # returned from java.net.InetAddress.getCanonicalHostName().
- advertised.listeners=PLAINTEXT://192.168.50.234:9092
- advertised.host.name=192.168.50.234
- advertised.port=9092
- # Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
- #listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
-
- # The number of threads that the server uses for receiving requests from the network and sending responses to the network
- num.network.threads=5
-
- # The number of threads that the server uses for processing requests, which may include disk I/O
- num.io.threads=8
- queued.max.requests=5000
- # The send buffer (SO_SNDBUF) used by the socket server
- socket.send.buffer.bytes=1024000
-
- # The receive buffer (SO_RCVBUF) used by the socket server
- socket.receive.buffer.bytes=1024000
-
- # The maximum size of a request that the socket server will accept (protection against OOM)
- socket.request.max.bytes=104857600
-
-
- ############################# Log Basics #############################
-
- # A comma separated list of directories under which to store log files
- log.dirs=C:/kafka/kafka_2.12-1.1.0/kafka-logs-1,C:/kafka/kafka_2.12-1.1.0/kafka-logs-2,C:/kafka/kafka_2.12-1.1.0/kafka-logs-3
-
- # The default number of log partitions per topic. More partitions allow greater
- # parallelism for consumption, but this will also result in more files across
- # the brokers.
- num.partitions=1
-
- # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
- # This value is recommended to be increased for installations with data dirs located in RAID array.
- num.recovery.threads.per.data.dir=1
-
- ############################# Internal Topic Settings #############################
- # The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
- # For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
- offsets.topic.replication.factor=3
- transaction.state.log.replication.factor=3
- transaction.state.log.min.isr=1
- auto.leader.rebalance.enable=true
- ############################# Log Flush Policy #############################
-
- # Messages are immediately written to the filesystem but by default we only fsync() to sync
- # the OS cache lazily. The following configurations control the flush of data to disk.
- # There are a few important trade-offs here:
- # 1. Durability: Unflushed data may be lost if you are not using replication.
- # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
- # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
- # The settings below allow one to configure the flush policy to flush data after a period of time or
- # every N messages (or both). This can be done globally and overridden on a per-topic basis.
-
- # The number of messages to accept before forcing a flush of data to disk
- log.flush.interval.messages=10000
-
- # The maximum amount of time a message can sit in a log before we force a flush
- log.flush.interval.ms=1000
-
- ############################# Log Retention Policy #############################
-
- # The following configurations control the disposal of log segments. The policy can
- # be set to delete segments after a period of time, or after a given size has accumulated.
- # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
- # from the end of the log.
-
- # The minimum age of a log file to be eligible for deletion due to age
- log.retention.hours=168
- #log.retention.minutes=2
- log.cleaner.enable=true
- log.cleanup.policy=delete
-
- # A size-based retention policy for logs. Segments are pruned from the log unless the remaining
- # segments drop below log.retention.bytes. Functions independently of log.retention.hours.
- #log.retention.bytes=1073741824
-
- # The maximum size of a log segment file. When this size is reached a new log segment will be created.
- log.segment.bytes=1073741824
-
- # The interval at which log segments are checked to see if they can be deleted according
- # to the retention policies
- log.retention.check.interval.ms=300000
-
- ############################# Zookeeper #############################
-
- # Zookeeper connection string (see zookeeper docs for details).
- # This is a comma separated host:port pairs, each corresponding to a zk
- # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
- # You can also append an optional chroot string to the urls to specify the
- # root directory for all kafka znodes.
- zookeeper.connect=192.168.50.234:2181
-
- # Timeout in ms for connecting to zookeeper
- zookeeper.connection.timeout.ms=6000
-
-
- ############################# Group Coordinator Settings #############################
-
- # The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
- # The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
- # The default value for this is 3 seconds.
- # We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
- # However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
- group.initial.rebalance.delay.ms=0

3.8 配置完后成,打开cmd,进入kafka文件目录:cd /d C:\kafka\kafka_2.12-1.1.0\
3.9 输入并执行以打开kafka:.\bin\windows\kafka-server-start.bat .\config\server.properties
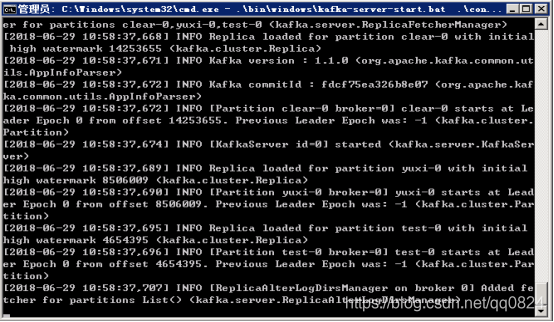
注意:不要关了这个窗口
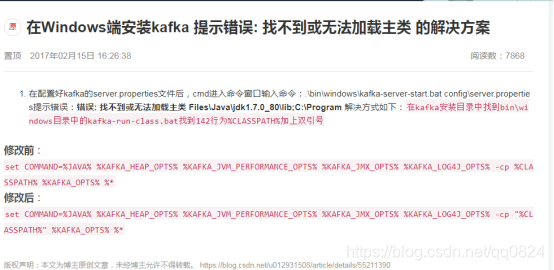
3.10 遇到的问题:启动kafka找不到或无法加载主类
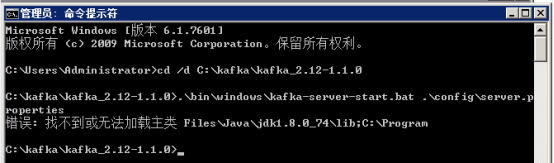
解决方案可参考 https://blog.csdn.net/u010775025/article/details/79208238
4.常用kafka命令
4.1 运行zkserver
zkserver
4.2 运行kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
4.3 创建topic
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
4.4 创建producer
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
4.5 创建consumer
.\bin\windows\kafka-console-consumer.bat --zookeeper localhost:2181 --topic test
4.6 查看创建的主题列表
bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
4.7 查看指定topic信息
bin\windows\kafka-topics.bat --zookeeper 127.0.0.1:2181 --describe --topic test
4.8 删除主题
bin\windows\kafka-topics.bat --zookeeper 127.0.0.1:2181 --delete --topic test
-- 删除topic,慎用,只会删除zookeeper中的元数据,消息文件须手动删除
bin\windows\kafka-topics.bat kafka.admin.DeleteTopicCommand --zookeeper 127.0.0.1:2181 --delete --topic test
4.9 查看topic某分区偏移量最大(小)值
.\bin\windows\kafka-run-class.bat kafka.tools.GetOffsetShell --topic luoluo --time -1 --broker-list localhost:9092 --partitions 0

