- 1Redis --- 高级篇_redis高级
- 2YOLOX可视化训练工具(webyolox)_yolo训练工具
- 3sql语句大全
- 4百度地图api接口获得密钥_百度地图api的访问密钥是什么
- 5OKR大决战:英特尔的总市值只有英伟达的一个零头_英伟达英特尔市值
- 6C# Web控件与数据感应之属性统一设置
- 7解决git报错 “remote: Please remove the file from history and try again.”
- 8敏捷迭代就是小瀑布吗?为什么创业团队更敏捷?_敏捷是瀑布的微型
- 9微调Llama2自我认知_自我认知数据集
- 10【信道估计】基于最小二乘法LS+最小均方误差MMSE+线性最小均方误差法LMMSE OFDM信道估计附Matlab代码_mmse lmmse
深度学习(三十八)初识DL在自然语言序列标注中的应用-未完待续_掌握有序列dl的应用有哪些
赞
踩
初识DL在自然语言中的应用
原文地址:
作者:
一、自然语言序列标注
虽然之前自己对于HMM、CRF、Word2vec、Attention机制、Encode-Decode等,在自然语言领域的应用已经比较熟悉了,看过的文献、教程、算法等也很多,但是感觉都只是纸上谈兵,自己从没有好好写过代码。因为自己一直是搞计算机视觉、图像领域,最近看了一些深度学习计算机视觉领域相关最新的文献后,总是觉得学到的知识不是很多;故而决定从今日开始正式踏足自然语言领域,开始NLP学习征程……
目前我看了很多经典文献:《Natural Language Processing (almost) from Scratch》、《Learning Character-level Representations for Part-of-Speech Tagging》、《End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF》、《Bidirectional LSTM-CRF Models for Sequence Tagging》 等 ,利用深度学习RNN、CNN、LSTM等网络模型做序列标注,主要包含以下几个特点:
对于自然语言来说,序列标注定义:给定一个句子X={x1,x2,……xn},我们的目标是求解输出序列Y={y1,y2,……yn},其中x1,x2……表示句子每个字。
以中文分词为例
(1)中文分词:目标是要把一个句子的每个字,标注成S、B、M、E,以下面的句子为例:
X={“ 人们 常 说 生活 是 一 部 教科书 , 而 血 与 火 的 战争}”
Y={S BE S S B E S S S BME S S S S S S B E}
对于分词任务来说,我们的任务就是要给上面的每个字打上类别标签:S、B、M、E,也就是说属于4分类问题,神经网络在设计的时候,网络的最后一层就是4个神经元的softmax输出。
(2)命名实体识别:目标是要把句子的每个字标注成:BA、MA、EA、BO、MO、EO、BP、MP、EP、O等,
其中BA代表这个汉字是地址首字,MA代表这个汉字是地址中间字,EA代表这个汉字是地址的尾字;BO代表这个汉字是机构名的首字,MO代表这个汉字是机构名称的中间字,EO代表这个汉字是机构名的尾字;BP代表这个汉字是人名首字,MP代表这个汉字是人名中间字,EP代表这个汉字是人名尾字,而O代表这个汉字不属于命名实体。具体的类别根据需求而定,比如你还要识别时间、一些特定的名词类别等,那么就加入新的类别标签。
除此之外,词性标注、语义角色识别,甚至连关键词提取等都可以看成是序列标注问题,比如关键词提取的目标可以看成对每个词做一个二分类:关键词、非关键词。因为序列标注都可以用同样一个框架,搞定任务。所以后面为了简单起见,我将用上面的分词例子为例,进行讲解。
(1)最普通的方案:
既然序列标注可以看成是对每个文字进行分类,最简单的方法是:把每个文字表示成一个索引向量(专业名词又称之为One-hot Representation),要预测该文字的标签的时候,就用这个向量作为输入。比如我们要分类上面句子中的文字"常",假设"常"在字典中的索引号为1020,字典的字数共10000。那么我们可以把常用数值表示x=(0,0,……1,……0),x是一个10000维的向量,除了第1020维的数值为1之外,其它的全部为0。用x向量作为神经网络的输入层,网络设计成三层MLP结构。神经网络的输出为4个神经元softmax层,对应于"常"分别属于S、B、M、E标签的概率,
OK,这是对于我等,只专注于计算机机视觉与深度学习,然而却完全没有接触过NLP的解决方案。首先上面的方案,不是不可行,而是精度非常非常低罢了(达到精度30%应该还是有的,哈哈,毕竟四个类别没有任何信息,等概率也可以到达25%精度)
虽然上面讲的方案很低级,然而后面我将以这个方案作为基础思路,对上面的方案存在的问题进行讲解,然后对方案做一步一步的改进,直到最后我们设计、训练出来的网络,可以与现有的世界最牛逼的序列标注算法相匹敌.
(2)第一次改进-上下文窗口
一般来说,我们在设计神经网络的时候,网络的输入层,不仅仅是一个文字,而是采用上下文窗口.可能以前我们遇到深度学习一般是思路是:输入层为xi,输入就是yi。xi表示一个句子中的某个文字,图片示例,一一映射:
然而一般对于自然语言来说,我们一般很难通过一个字,判断这个字的标签,比如上面"常",如果是单独的一个文字,我们根本无法确定其标签,其具体标签还得看"常"在该句子中的上下文信息,对于上面的分词例子,"常"在该句子中的分类标签是S;.然而对于下面的句子:
"我经常独自一人吃饭"
中"常"的标签就应该是B.
因此让神经网络的输入层为单个文字:"常",进行预测类别标签,显然是不合理的.一般来说我们会采用上下文窗口(这个就像图像处理的卷积窗口感受野一样)神经网络的输入应该是:
(2)第二次改进-字向量
(3)第三次改进-序列标签约束MLP+CRF
(5)第五次改进-RNN、LSTM+CRF
(6)第六次改进双向LSTM+CRF
(7)第七次改进双向LSTM+CNN+CRF
(4)细节改进-字向量无监督预训练
二、采用上下文窗口+词向量-简单MLP中文分词尝试
作为自己学习NLP的第一站,当然是先用最简单的网络做最简单的任务,练练手再说。
神经网络的输入:
“ 人们 常 说 生活 是 一 部 教科书 , 而 血 与 火 的 战争…… ”。
S BE S S B E S S S BME S S S S S S B E
神经网络的输出:
下面是我用简单的MLP,进行中文分词的源码测试,因此记录一下自己的第一个自然语言程序:
- #coding=utf-8
- from collections import OrderedDict
- import os
- import random
- import numpy
- import theano
- from theano import tensor as T
- from Preprocess.LoadData import Segment,write
- import numpy as np
-
-
-
- # 打乱样本数据
- def shuffle(lol, seed):
- for l in lol:
- random.seed(seed)
- random.shuffle(l)
-
-
- #输入一个长句,我们根据窗口获取每个win内的数据,作为一个样本。或者也可以称之为作为RNN的某一时刻的输入
- def contextwin(l, win):
-
- assert (win % 2) == 1
- assert win >= 1
- l = list(l)
-
- lpadded = win // 2 * [-1] + l + win // 2 * [-1]#在一个句子的末尾、开头,可能win size内不知,我们用-1 padding
- out = [lpadded[i:(i + win)] for i in range(len(l))]
-
- assert len(out) == len(l)
- return out
-
-
-
-
- # 输出结果,用于脚本conlleval.pl的精度测试,该脚本需要自己下载,在windows下调用命令为:perl conlleval.pl < filename
- def conlleval(p, g, w, filename):
- out = ''
- for sl, sp, sw in zip(g, p, w):
- out += 'BOS O O\n'
- for wl, wp, w in zip(sl, sp, sw):
- out += w + ' ' + wl + ' ' + wp + '\n'
- out += 'EOS O O\n\n'
-
- f = open(filename, 'w')
- f.writelines(out)
- f.close()
-
-
-
-
- class RNNSLU(object):
- def __init__(self, nh, nc, ne, de, cs):
- '''
- nh ::隐藏层神经元个数
- nc ::输出层标签分类类别
- ne :: 单词的个数
- de :: 词向量的维度
- cs :: 上下文窗口
- '''
- #词向量实际为(ne, de),外加1行,是为了边界标签-1而设定的
- self.emb = theano.shared(name='embeddings',value=0.2 * numpy.random.uniform(-1.0, 1.0,(ne+1, de)).astype(theano.config.floatX))#词向量空间
- self.wx = theano.shared(name='wx',value=0.2 * numpy.random.uniform(-1.0, 1.0,(de * cs, nh)).astype(theano.config.floatX))#输入数据到隐藏层的权重矩阵
- self.wh = theano.shared(name='wh', value=0.2 * numpy.random.uniform(-1.0, 1.0,(nh, nh)).astype(theano.config.floatX))#上一时刻隐藏到本时刻隐藏层循环递归的权值矩阵
- self.w = theano.shared(name='w',value=0.2 * numpy.random.uniform(-1.0, 1.0,(nh, nc)).astype(theano.config.floatX))#隐藏层到输出层的权值矩阵
- self.bh = theano.shared(name='bh', value=numpy.zeros(nh,dtype=theano.config.floatX))#隐藏层偏置参数
- self.b = theano.shared(name='b',value=numpy.zeros(nc,dtype=theano.config.floatX))#输出层偏置参数
-
- self.h0 = theano.shared(name='h0',value=numpy.zeros(nh,dtype=theano.config.floatX))
-
-
- self.params = [self.emb, self.wx, self.wh, self.w,self.bh, self.b]#所有待学习的参数
-
- idxs = T.itensor3()
- x = self.emb[idxs].reshape((idxs.shape[0],idxs.shape[1],de*idxs.shape[2]))
- y_sentence = T.imatrix('y_sentence') # 训练样本标签,二维的(batch,sentence)
-
-
-
- s_temp=self.forward(x)
-
- p_y =T.nnet.softmax(T.reshape(s_temp,(s_temp.shape[0]*s_temp.shape[1],-1)))
- p_y=T.reshape(p_y,s_temp.shape)
- #h,p_y=step(x, self.h0)#p_y为三维矩阵,表示每个样本的值
-
- loss=self.nll_multiclass(p_y,y_sentence)+0.0*((self.wx**2).sum()+(self.wh**2).sum()+(self.w**2).sum())
-
- lr = T.scalar('lr')#学习率,一会儿作为输入参数
-
- #神经网络的输出
- sentence_gradients = T.grad(loss, self.params)
-
-
-
-
-
- sentence_updates = OrderedDict((p, p - lr*g) for p, g in zip(self.params, sentence_gradients))
- self.sentence_train = theano.function(inputs=[idxs,y_sentence,lr],outputs=loss,updates=sentence_updates)
- #词向量归一化,因为我们希望训练出来的向量是一个归一化向量
- self.normalize = theano.function(inputs=[],updates={self.emb:self.emb /T.sqrt((self.emb**2).sum(axis=1)).dimshuffle(0, 'x')})
-
- #构造预测函数、训练函数,输入数据idxs每一行是一个样本(也就是一个窗口内的序列索引)
- y_pred = T.argmax(p_y,axis=-1)
- self.classify = theano.function(inputs=[idxs,y_sentence], outputs=[loss,y_pred])
- #这边没有采用RNN,而是直接采用MLP进行中文分词
- def forward(self,x):
- x_t=x#.dimshuffle((1,0,2))
- def step(x_t, h_tm1):
- h_t = T.nnet.sigmoid(T.dot(x_t, self.wx) + self.bh)#通过ht-1、x计算隐藏层
- s_temp=T.dot(h_t, self.w) + self.b#由于softmax不支持三维矩阵操作,所以这边需要对其进行reshape成2D,计算完毕后再reshape成3D
- return h_t, s_temp
- #[h,s_temp], _ = theano.scan(step,sequences=x_t,outputs_info=[T.ones(shape=(x_t.shape[1],self.h0.shape[0])) * self.h0, None])
- [h,s_temp]=step(x_t,self.h0)#s_temp#.dimshuffle((1,0,2))
- return s_temp
- def backward(self,x):
- x_t=x#.dimshuffle((1,0,2))
- def step(x_t, h_tm1):
- h_t = T.nnet.tanh(T.dot(x_t, self.wx) + T.dot(h_tm1, self.wh) + self.bh)#通过ht-1、x计算隐藏层
- s_temp=T.dot(h_t, self.w) + self.b#由于softmax不支持三维矩阵操作,所以这边需要对其进行reshape成2D,计算完毕后再reshape成3D
- return h_t, s_temp
- [h,s_temp], _ = theano.scan(step,sequences=x_t,outputs_info=[T.ones(shape=(x_t.shape[1],self.h0.shape[0])) * self.h0, None],go_backwards = True)
- s_temp=s_temp#.dimshuffle((1,0,2))
- return s_temp
- #训练
- def train(self, x, y,learning_rate):
- loss=self.sentence_train(x, y, learning_rate)
- self.normalize()
- return loss
- def nll_multiclass(self,p_y_given_x, y):
- p_y =p_y_given_x
- p_y_m = T.reshape(p_y, (p_y.shape[0] * p_y.shape[1], -1))
- y_f = y.flatten(ndim=1)
- return -T.mean(T.log(p_y_m)[T.arange(p_y_m.shape[0]), y_f])
-
- #保存、加载训练模型
- def save(self, folder):
- for param in self.params:
- numpy.save(os.path.join(folder,
- param.name + '.npy'), param.get_value())
- def load(self, folder):
- for param in self.params:
- param.set_value(numpy.load(os.path.join(folder,
- param.name + '.npy')))
- #为了采用batch训练,需要保证每个句子长度相同,因此这里采用均匀切分,不过有一个缺陷那就是有可能某个词刚好被切开
- def convert2batch(dic,filename_list,win,length=3):
- x=[]
- y=[]
- for f in filename_list:
- xt,yt=dic.encode_index(f)#创建训练数据的索引序列
- x=x+xt
- y=y+yt
-
-
-
- train_batchxs=[]
- train_batchys=[]
-
-
-
-
- train_seqx=[x[i:i+length] for i in range(len(x)) if i%length==0]
- train_seqy=[y[i:i+length] for i in range(len(y)) if i%length==0]
- for x,y in zip(train_seqx,train_seqy):
- if len(x)!=length or len(y)!=length:
- continue
- s=contextwin(x,win)
- train_batchxs.append(s)
- train_batchys.append(y)
-
- #每个句子的长度不同,不能直接转换
- return np.asarray(train_batchxs,dtype=np.int32),np.asarray(train_batchys,dtype=np.int32)
-
-
- #RNN分词
- def segment_train(dic,filename):
- trainx,trainy=convert2batch(dic,filename,5,1000)
-
- #计算相关参数
- vocsize = len(dic.word2index)#计算词的个数
- print vocsize
- nclasses =len(dic.label2index)#标签数为B、M、E、S
- winsize=5#窗口大小
- ndim=50#词向量维度
- nhidden=200#隐藏层的神经元个数
- learn_rate=0.5#梯度下降学习率
-
- #构建RNN,开始训练
- rnn = RNNSLU(nh=nhidden,nc=nclasses,ne=vocsize,de=ndim,cs=winsize)
-
- batch_size=64
- n_train_batch=trainx.shape[0]/batch_size
- rnn.load('model/')
- epoch=0
- while epoch<0:
- shuffle([trainx,trainy], 345)
- loss=0
- for i in range(n_train_batch):
- batx=trainx[i*batch_size:(i+1)*batch_size]
- baty=trainy[i*batch_size:(i+1)*batch_size]
- decay_lr=learn_rate*0.5**(epoch/50)
- loss+=rnn.train(batx,baty,decay_lr)
- print 'epoch:',epoch,'\tloss:',loss/n_train_batch
- epoch+=1
- if epoch%50==0:
- rnn.save('model/')
- #rnn.save('model/')
- return rnn
- def segment_test(model,dic,test_file):
- #model.load('model/')#加载训练参数
- x,y=dic.encode_index(test_file)#创建训练数据的索引序列
- xjieba,yjieba=dic.encode_index('Data/msr/msr_test_jieba_result.txt')#创建训练数据的索引序列
- test_batchxs=[]
- test_batchys=[]
- s=contextwin(x,5)
- test_batchxs.append(s)
- test_batchys.append(y)
-
-
- loss,pre=model.classify(np.asarray(test_batchxs),np.asarray(test_batchys).transpose((1,0)))
- print 'loss:',loss
- print pre.shape
-
-
- #测试集的输出标签
- print pre.shape
- predictions_label=dic.decode_index(pre[0],is_label=True)
- groudtrue_label=dic.decode_index(y,is_label=True)
- words_test=dic.decode_index(x)
-
-
- for k,(w,i,j) in enumerate(zip(words_test,groudtrue_label,predictions_label)):
- print w,i,j
-
-
- print 'save'
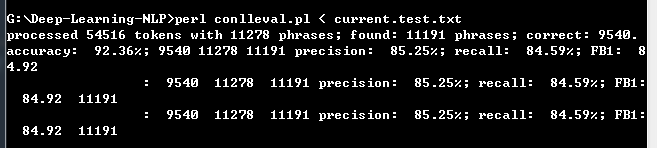
- conlleval(predictions_label,groudtrue_label,words_test, 'current.test.txt')
-
- filelist=['Data/msr/msr_training.utf8','Data/msr/pku_training.utf8','Data/msr/1.txt','Data/msr/1998.txt']
- #filelist=['Data/msr/msr_training.utf8']
- dic=Segment(filelist)#创建词典
- print len(dic.word2index)
- model=segment_train(dic,filelist)
- segment_test(model,dic,'Data/msr/msr_test_gold.utf8')