
热门标签
热门文章
- 1关于GPT的API_gtp api
- 2mac os x 直接读写NTFS
- 3力扣日记8.18&8.21【链表篇】环形链表、环形链表II
- 4数据结构算法与解析(STL版含源码)_数据结构是不是stl源码
- 5适用于Java开发人员的微服务:持续集成和持续交付
- 62024计算机工程与图像处理国际会议(ICCEIP 2024)_2024 ieee international conference on image proces
- 7Redis入门教程_根据提示,打开命令行,启动 redis 客户端并创建一些值: 使用默认配置后台启动 redi
- 819.4-STM32接收数据-状态显示在屏幕 openMV寻迹与小车控制 Openmv+STM32F103C8T6视觉巡线小车_stm32巡线openmv
- 9群晖NAS设置IPV6公网访问_nas ipv6
- 10PyCharm 2024新版图文安装教程(python环境搭建+PyCharm安装+运行测试+汉化+背景图设置)_pycharm2024安装教程
当前位置: article > 正文
11.QLoRA微调ChatGLM3-6B_qlora glm
作者:爱喝兽奶帝天荒 | 2024-07-17 02:03:31
赞
踩
qlora glm
实战 QLoRA 微调 ChatGLM3-6B 大模型
实战 PEFT 库 QLoRA ChatGLM3-6B

微调数据集 AdvertiseGen
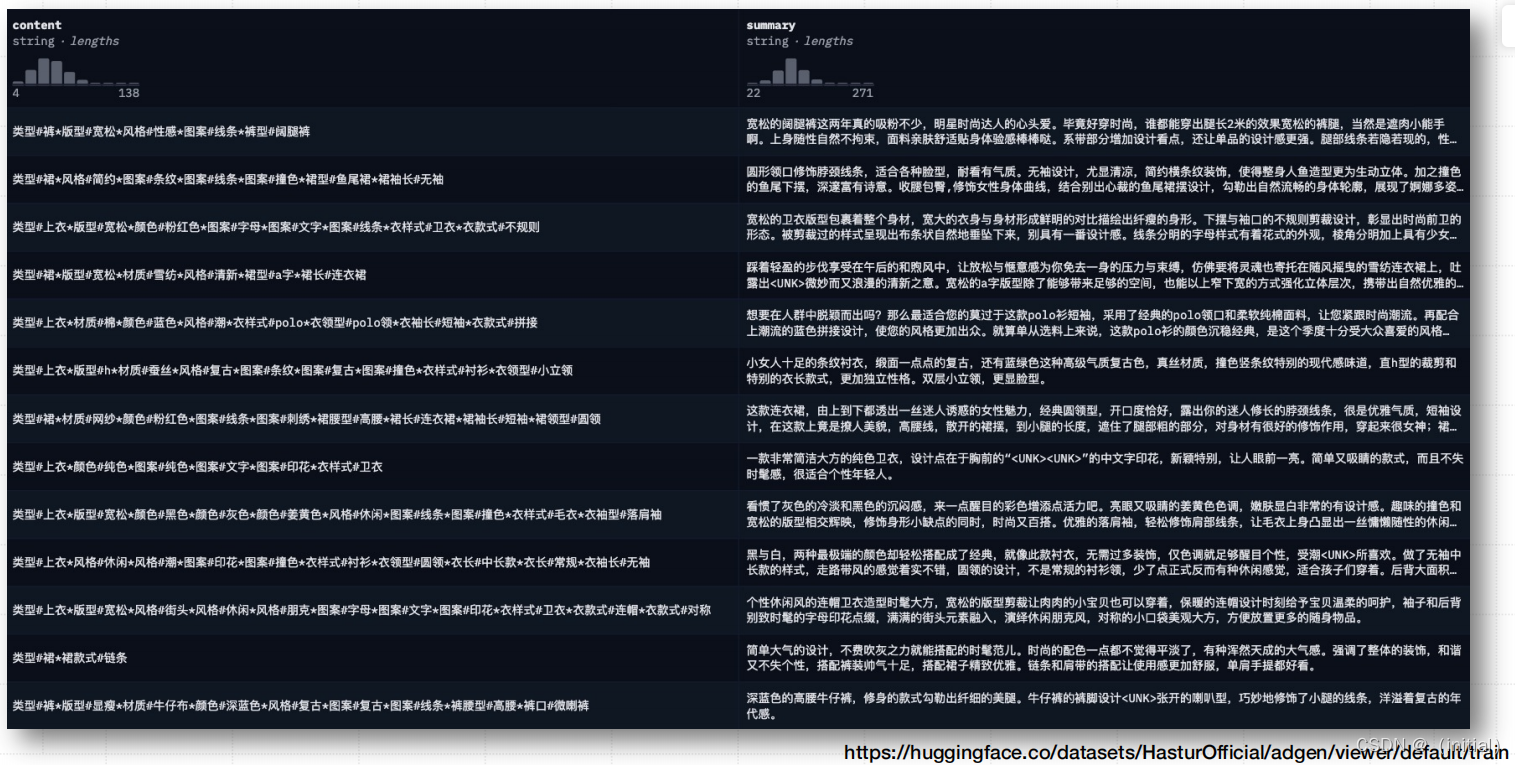
AdvertiseGen 数据集获取
使用ChatGLM3-6b Tokenizer处理数据
关于ig nore_label_id 的设置:
在许多自然语言处理和机器学习框架中, ig nore_label_id 被设置为-100 是一种常见的约定。 这个特殊的值用千标记在计算损失函数时应该被忽略的目标标签。 让我们详细了解一下这个选择的原因:
- 损失函数忽略特定值:训练语言模型时, 损失函数(例如交叉嫡损失)通常只计算对千模型预测重要或关键的标签的损失。 在某些况下, 你可能不希望某些标签对损失计算产生影晌。 例如, 在序列到序列的模型中, 输入部分的标签通常被设置为一个忽略值, 因为只有输出部分的标签对千训练是重要的。
- 为何选择-100: 这个具体的值是基千实现细节选择的。 在 PyTorch 的交叉嫡损失函数中, 可以指定一个ig nore_index 参数。 当损失函数看到这个索引值时, 它就会忽略对应的输出标签。 使用-100 作为默认值是因为它是一个不太可能出现在标签中的数字(特别是在处理分类间题时, 标签通常是从0开始的正整数)。
- 标准化和通用性:由于这种做法在多个库和框架中被采纳, -100 作为忽略标签的默认值已经变得相对标准化, 这有助于维护代码的通用性和可读性。
总的来说, 将ig nore_label_id 设置为-100 是一种在计算损失时排除特定标签影晌的便捷方式。 这在处理特定类型的自然语言处理任务时非常有用, 尤其是在涉及序列生成或修改的任务中。
自定义模型新增Adapter
当新的热门transformer网络架构(新模型)发布时, Huggingface社区会尽力快速将它们添加到PEFT 中。
具体来说, 在初始化相应的微调配置类(例如 LoraConfig)时, 我们需要显式指定在哪些层新增适配器(Adapter), 并将其设置正确。
ref: https
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/837403
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

