
热门标签
热门文章
- 1使用朴素贝叶斯模型进行测试数据预测推理(R语言)_使用多项事件模型朴素贝叶斯分类对测试集进行预测
- 2C++程序:输出字符菱形_c++输出菱形*号代码解析
- 3华为测试岗实习生面试回顾_华为的测试岗位面试
- 4uniapp项目使用vue3_请确认您的项目模板是否支持vue3:根目录缺少 index.html
- 53dMax建筑demo制作_3d建模demo
- 6Leetcode SQL 50题刷题攻略(上篇)_leetcode怎么刷sql
- 7Arthas运用且与Docker结合_arthas 加入到dockerfile
- 8Android中的类装载器DexClassLoader,我的Android春季历程
- 9云计算、雾计算、边缘计算、海计算介绍
- 10猫头虎 最新 Linux 系统查看服务器温度的方法大全_linux 查看温度
当前位置: article > 正文
sparksql join方式
作者:爱喝兽奶帝天荒 | 2024-07-15 15:09:12
赞
踩
sparksql join
简介
Spark的几种join方式
- Broadcast Hash Join:适合一张很小的表和一张大表进行Join
- Shuffle Hash Join:适合一张小表(比上一个大一点)和一张大表进行Join
- Sort Merge Join:适合两张大表进行Join
- Cartesian Hash Join: 笛卡尔连接方式,性能很差
- NestedLoopJoin : 性能很差
对应以下几个类,Spark会根据CBO和AQE来决定使用哪种join方式
Broadcast Hash Join
这种方式的好处是可以不用shuffle,可以直接使用广播变量,但是有条件
- 被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的信息,默认是10M;
- 基表不能被广播,比如left outer join时,左边的表就是基表,此时就只能广播右表。

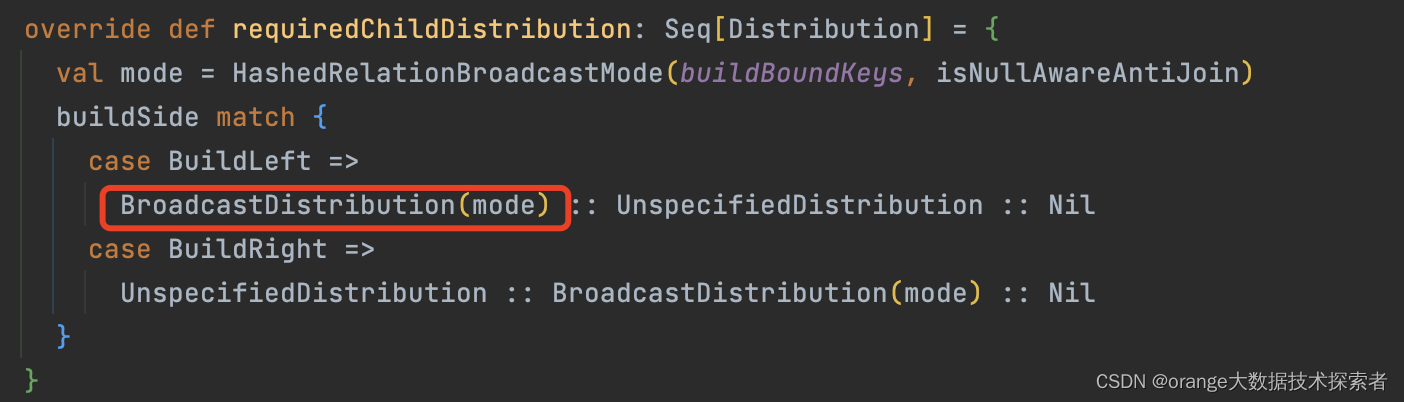
过程
- Table B是较小的表,黑色表示将其广播到每个executor节点上,Table A的每个partition会通过block manager取到Table A的数据。
- 根据每条记录的Join Key取到Table B中相对应的记录,根据Join Type进行操作
Shuffle Hash Join
当右表比较大时,在把右表Broadcast就会有压力
其原理如下图:

- 对两张表分别按照join keys进行重分区,即shuffle,目的是为了让有相同join keys值的记录分到对应的分区中
- 对对应分区中的数据进行hash join,此处先将小表分区构造为一张hash表,然后根据大表分区中记录的join keys值拿出来进行匹配
Sort Merge Join
上面介绍的两种实现对于一定大小的表比较适用,但当两个表都非常大时,显然无论适用哪种都会对计算内存造成很大压力。这是因为join时两者采取的都是hash join,是将一侧的数据完全加载到内存中,使用hash code取join keys值相等的记录进行连接。
当两个表都非常大时,SparkSQL采用了一种全新的方案来对表进行Join,即Sort Merge Join。这种实现方式不用将一侧数据全部加载后再进星hash join,但需要在join前将数据排序,如下图所示:

SortMergeJoinExec类,主要做几个事情
- shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理;
- sort阶段:对单个分区节点的两表数据,分别进行排序;
- merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出
Cartesian 和 NestedLoopJoin
Cartesian 和 NestedLoopJoin 性能很差,所以一般只有在写不等式join或者cross join的时候会选择这两种策略
Nested Loop Join适用于小表到大表的情况,Spark将迭代表A的每一行并在表B中查找匹配的行。这个过程将不断重复,直到表A的所有行都被处理,需要对表A中的每一行进行一次表B的全表扫描,所以大表表现很差
CartesianJoin 一般用来做笛卡尔积连接
为了避免性能问题,一般会把不等式join转为等式join处理
总结
虽然有上述5 个核心类 / join方式,但是其实对应 Nested-loop Join、Sort-Merge Join 和 Hash Join 3种 join 的思想
- Nested-loop Join 最为简单直接,将两个数据集加载到内存,并用内嵌遍历的方式来逐个比较两个数据集内的元素是否符合 Join 条件。Nested-loop Join 的时间效率以及空间效率都是最低的,可以使用:table.exec.disabled-operators:NestedLoopJoin 来禁用。
- Sort-Merge Join 分为 Sort 和 Merge 两个阶段:首先将两个数据集进行分别排序,然后再对两个有序数据集分别进行遍历和匹配,类似于归并排序的合并。(Sort-Merge Join 要求对两个数据集进行排序,但是如果两个输入是有序的数据集,则可以作为一种优化方案)。
- Hash Join 同样分为两个阶段:首先将一个数据集转换为 Hash Table,然后遍历另外一个数据集元素并与 Hash Table 内的元素进行匹配。
1 第一阶段和第一个数据集分别称为 build 阶段和 build table;
2 第二个阶段和第二个数据集分别称为 probe 阶段和 probe table。
Hash Join 效率较高但是对空间要求较大,通常是作为 Join 其中一个表为适合放入内存的小表的情况下的优化方案 (并不是不允许溢写磁盘)。
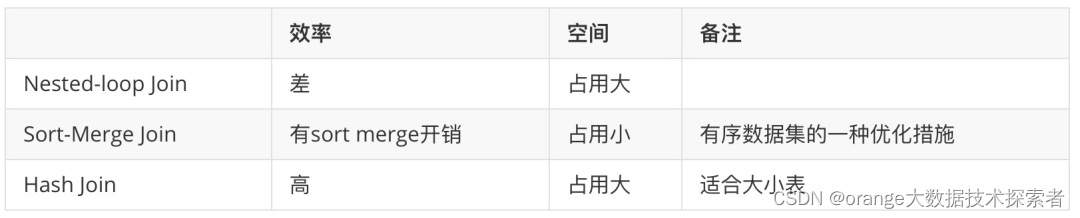
注意:Sort-Merge Join 和 Hash Join 只适用于 Equi-Join ( Join 条件均使用等于作为比较算子)。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/829958
推荐阅读
相关标签

