
- 1一款高仿 Eyepetizer | 开眼短视频的 MVVM 开源项目
- 2【论文阅读】联邦学习DLG攻击_NeurIPS2019_Deep Leakage from Gradients_深度梯度泄露,模型逆向攻击_联邦学习dgl攻击
- 3一次性可以导入多少首歌曲到NoteBurner Spotify Music Converter中?
- 4mysql utf8mb4 java_更改MySQL数据库的编码为utf8mb4
- 5Python什么是闭包、闭包特征、定义闭包传入一个数求和并输出,定义一个装饰器:打印函数运行花费的时间,定义一个类:要求:包含一个对象属性,且用_(单下划线)命名的定义一个类方法(装饰器)_python闭包和类
- 6简单存 Bean 对象 -- 五大类注解以及 Bean 方法注解_java bean注解
- 7数据可视化之matplotlib实战:plt.xlim() ylim()函数 设置x轴y轴范围坐标
- 8spring boot实现短信验证码功能_springboot 短信验证码 测试环境
- 9YOLOv8全面分析_yolov8模型介绍
- 10vscode+gitee+picgo实现稳定图床_vscode picgo
Python环境下基于关系网络的滚动轴承故障诊断方法_轴承故障诊断无样本学习方法
赞
踩
少样本学习最初是为了模拟小孩子的大脑而设计的,因为小孩子他们能够通过一个或几个事例来认识某样新事物。少样本学习的主要目标是通过先验知识或经验的迭代训练,使模型在少样本的情况下也能有很好的表现。根据上述条件,可以将少样本学习定义为是一种机器学习问题(由E,T,P三个条件指定),其中,T可代指某种分类任务,P可代指准确率等任务的评估标准,E可代指任务相关的数据集,其中包含任务T的监督信息且仅包含有限数量的实例。一般来说,现阶段的少样本研究方法可以分为三大类:(1)基于数据的,它使用先验知识来增强模型的效果。(2)基于模型的,它使用先验知识来减小假设空间的大小。(3)基于算法的,它使用先验知识改变在给定假设空间中的最佳搜索策略的方法。
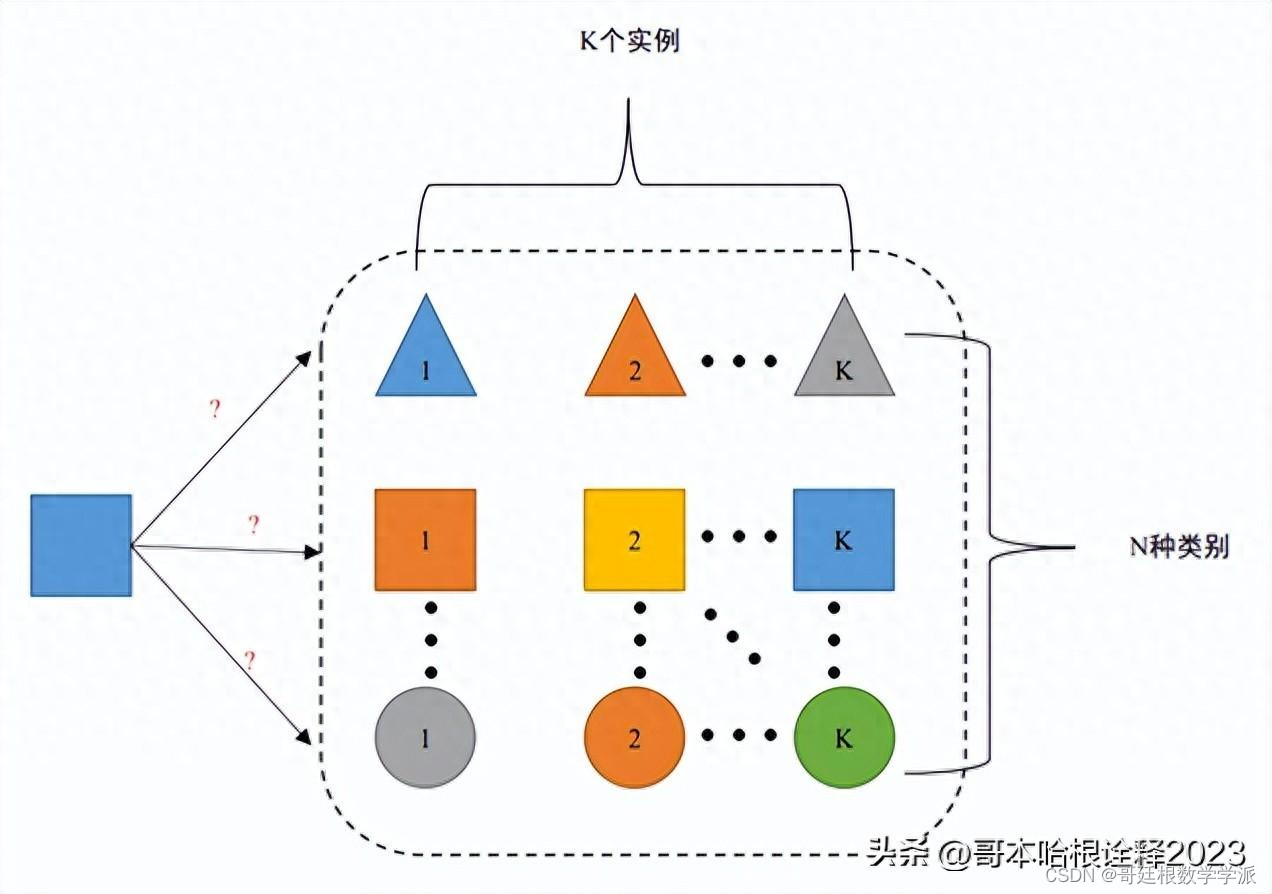
少样本学习有一个常用定义,如果支持集包含N个故障类别,且每个类别中有K个故障实例,则称此少样本学习任务为N-wayK-shot任务。
基于数据的技术
基于数据的这一类技术旨在使用先验知识来增强训练数据,从而丰富监督信息,通过增强后的数据集可以获得更可靠的经验风险最小化的最佳假设。根据不同的增强方法,这一技术可以分为三种策略:(1)在目标数据集中增加数据,是将单个样本训练成多个不同的样本,使原有数据集中的样本变得多样[。(2)从弱标记、无标记数据集中选择目标标签的样本。(3)从相似数据集中转换数据,对少样本训练数据进行增强。
基于模型的技术
基于模型的方法又可以进一步分为四种类型:多任务学习、度量学习、使用外部存储器学习、生成模型。

基于算法的技术
使用先验知识来帮忙获取参数主要有两种方式:(1)提供一个效果良好的初始化参数。(2)直接学习一个优化器来输出搜索步骤。根据 先验知识对搜索策略的影响,基于算法的技术可分为三类。
先验知识对搜索策略的影响,基于算法的技术可分为三类。
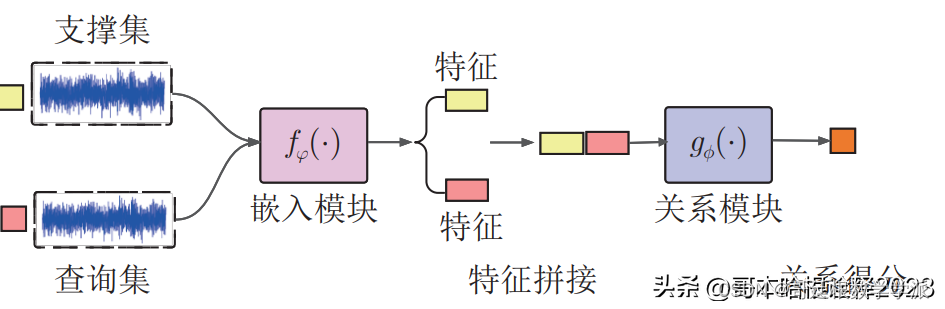
关系网络(RelationNetwork)具有与关系推理相适应的结构,能够较好地把握其中的关键。人工智能行为的一个基本概念就是能够对实体之间的关系进行推理。关系网络最初用于小样本条件下的图像分类, 与传统深度神经网络需要大量样本训练不同, 该网络能在少量训练样本情况下, 取得较好的图像分类结果。关系网络 包含嵌入模块和关系模块, 是一种端到端的结构。嵌入模块用来提取输入样本的特征; 关系模块用来度量两个特征之间的相似性, 得到关系得分。
 鉴于此,提出一种基于关系网络的滚动轴承故障诊断方法,运行环境为Python,可能采用的数据集如下:
鉴于此,提出一种基于关系网络的滚动轴承故障诊断方法,运行环境为Python,可能采用的数据集如下:

数据集A-D由西储大学CWRU轴承数据集而来,数据集E-F由KAt数据集而来,主代码如下:
- import numpy as np
- import scipy.io as sio
- import os
- import Relation_Network as RN
- import random
-
-
- def get_data(datapath, is_normalization=False, is_fft=False):
- data = sio.loadmat(datapath)
-
- try:
- trainX = data['trainX'].astype(np.float32)
- testX = data['testX'].astype(np.float32)
- trainY = data['trainY']
- testY = data['testY']
- if trainY.shape[0]>1:
- trainY = np.argmax(trainY, axis=1)
- testY = np.argmax(testY, axis=1)
- else:
- trainY = trainY-1
- testY = testY-1
- except:
- X = data['X'].astype(np.float32)
- Y = np.argmax(data['Y'], axis=1)
- trainX, testX, train_indices, test_indices = utils.split_train_test(X, test_ratio=0.5)
- trainY, testY = Y[train_indices], Y[test_indices]
-
- if is_fft:
- trainX = np.absolute(np.fft.fft(trainX, axis=1)).astype(np.float32)
- testX = np.absolute(np.fft.fft(testX, axis=1)).astype(np.float32)
-
- if is_normalization:
- trainX, mu, sigma = utils.zscore(trainX, dim=0)
- testX = utils.normalize(testX, mu, sigma)
- return trainX, trainY, testX, testY
-
-
- def get_sample_data(X, Y, num=10, classes=None):
- if classes is None: classes = len(np.unique(Y))
-
- Xs, Ys = [], [],
- for i in range(classes):
- idx = np.where(Y==i)
- idx = random.sample(list(idx[0]), num)
-
- Xs.extend(X[idx])
- Ys.extend(Y[idx])
- return np.array(Xs), np.array(Ys)
-
- # ---------------------------------------------
- # few-shot learning with relation network
- # ---------------------------------------------
- datasets = ['dataA', 'dataB', 'dataC', 'dataD', 'dataE', 'dataF']
- datapath = 'datasets/'
- for i in [3]:
- utils.setup_seed(seed=0)
- data = datasets[i]
- save_result = f'./results/{data}'
-
- #utils.setup_seed(seed=0)
- trainX, trainY, testX, testY = get_data(datapath+data, is_fft=True)
- trainX, trainY = get_sample_data(trainX, trainY, num=5, classes=10) # randomly select a small number of training data
-
-
- ### Define Nets
- EM = RN.embedding_module(in_size=trainX.shape[1])
- RM = RN.relation_module(in_size=1024)
- #EM = RN.embedding_module2()
- #RM = RN.relation_module2()
-
- ### Train Nets
- model = RN.Relation_net(trainX, trainY, n_epoch=200, is_normalization=True)
- model = model.train(EM, RM)
-
- ### ensemble model with update
- out = model.test(testX)
-
- result = {}
- result['prediction'] = out['prediction']
- result['relation'] = out['relation']
- result['loss'] = model.loss
- result['true_label'] = testY
-
-
- if not os.path.exists(save_result): os.makedirs(save_result)
- sio.savemat(f'{save_result}/result-{model.n_support}shot.mat', result)

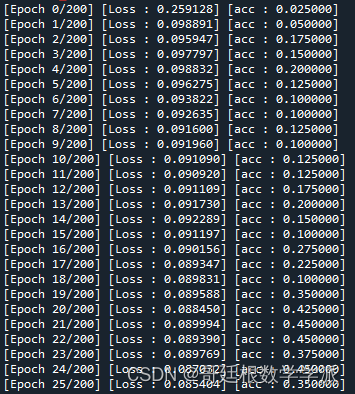
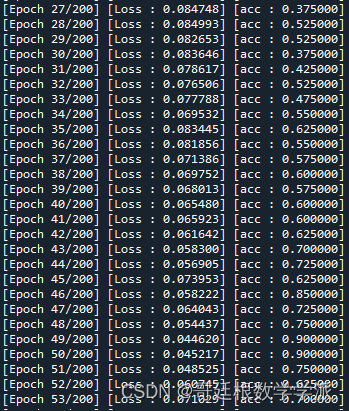
结果如下:
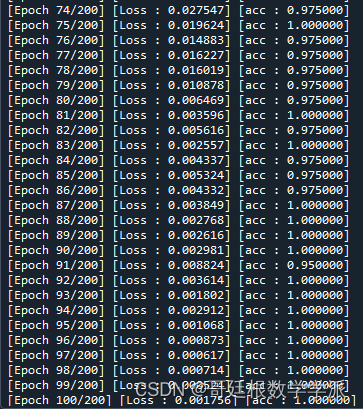
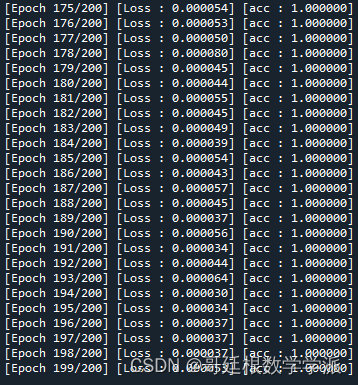
完整代码可由知乎学术咨询获得:
工学博士,担任《Mechanical System and Signal Processing》审稿专家,担任《中国电机工程学报》优秀审稿专家,《控制与决策》,《系统工程与电子技术》,《电力系统保护与控制》,《宇航学报》等EI期刊审稿专家。
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。


