
- 1BERT微调—关系分类任务_实体关系分类任务
- 2html网页制作——【制作浪漫气球520告白相册】 HTML5七夕情人节表白网页源码 HTML+CSS+JavaScript_用网页写出520
- 3nacos持久化&集群部署_nacos vue
- 4Kubernetes基础篇-01- Kubernetes的发展史以及架构说明_kubernetes历史版本
- 5青云1000------华为昇腾310_青云1000开发板
- 6Hadoop中HDFS、Hive 和 HBase三者之间的关系_hive hdfs关系
- 7引擎开发_ 碰撞检测_GJK 算法详细介绍_sat gjk
- 8利用 Python 自动抓取微博热搜,并定时发送至邮箱_python爬取微博热搜并发送邮件
- 9Git clone出现问题以及解决办法_用git克隆github项目遇到的问题及解决方案
- 10redisson的锁的类型_Redisson分布式锁实现
书写数字识别(C++ 、 KNN 、openCV)_c++ opencv 识别数字
赞
踩
目录
前言
前段时间在工作中用到一些图像处理的内容,功能不算太难,但却是我第一次使用opencv库、第一次用c++写工程(老c了)、第一次接触KNN算法,还是很有纪念意义的,所以今天在这里记录一下,也算是重新巩固一遍做过的内容。
说到图像处理大家肯定都会想到opencv,没错!作为一个专门为图像处理而生的库,它的功能确实强大,里边集成了大量的图像处理相关的类、API以及算法,日常的图像处理操作几乎都可以在库里边找到相应的函数来实现(有兴趣的话完全可以自己写一个p图APP,哈哈)。
什么是KNN?
KNN(K-Nearest Neighbor,KNN)算法又叫做“最近相邻算法”,是著名的模式识别统计学方法,在机器学习分类算法中占有相当大的地位。它是一个理论上比较成熟的方法。既是最简单的机器学习算法之一,也是基于实例的学习方法中最基本的,又是最好的文本分类算法之一。这个解释是不是很官方?!莫慌!!!其实在我看来,其奥义就是“少数服从多数”。具体算法理论以及过程这里不再细说(主要是我也看不太懂,但不影响使用哈哈),网上官方的解释很多,想深入了解的话可以多去看看相关的资料。
下边引用了链接的解释(自己理解的哈),如下图所示,判断绿点处应该属于哪一类?是蓝色方块还是红色三角?这时就需要考虑到一个权值的问题。如果K=3(假设临近绿点的对象一共有三个),那么红色三角形有两个,蓝色的方块只有一个,此时红色占比为2/3,如果这时处理的是一个图像的话,绿点处就归到红色三角形那一类中了;如果K=5,这个时候蓝色的方块又比红色的三角形多一个,所以绿点处的会被归于蓝色方块那一类中。由此可以看出,K值的取值会对你的识别率有很大的影响。K值太大易引起欠拟合,太小容易过拟合,需交叉验证确定K值(别问,问就是好像懂了,也好想没懂)关于K值选取。
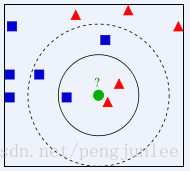
个人理解是:K值越小就越逼真于原图,但是对于那种区域特征重合比较多的图像就不太容易分辨(这个是我在开发过程中发现的,比如在识别1和7的时候,虽然看起来两个数字差别是很大的,但是在手写的过程中,1都会稍微往右偏一点,就会和7的下半部分特征重合度增高,原本写的是1,但是识别出来就会是7),这个时候你就可以加大K值,但是对于那种特征比较明显的数字,那样又会降低它本来的准确率。个人建议多实验几次,选取识别率最高的那个作为K值,还有就是,K一定要取奇数!!!。(看了很多例程确实没有取偶数的,自己想一下当在一定的范围内,如果两类的数量相同怎么办?)这个时候估计有人会杠,那如果就算是取了奇数,但是是三个类怎么办?他们也有数量相等的可能。是的!所以在进行KNN运算之前,最重要的一步是一定要对样本特征进行归一化处理(可以理解为只有0和1),在项目中体现为把所有图像都转换为灰度图像来进行处理。以上理解仅是个人观点哈,从开发过程中来看,好像确实是这样的,如果不对的话,欢迎大家提出来共同探讨。
opencv中的类
opencv库中的类有很多,在这里提一下手写数字识别时可能用到的类,具体内容还是自行百度比较好(你们懂得),在这里仅是提供一个方向,其实在开发的过程中根据各自的项目需求,往往需要了解大量的类以及API(下边借鉴了这位作者的整理opencv常用类)。
mat类:
1.使用Mat()构造函数
Mat是Opencv中的通用矩阵类型,我们通常将它作为图片的容器,它包含了矩阵头(包含矩阵尺寸,储存方法,储存地址等信息)和指向储存所有点值的指针。其创建方法如下:
对于二维多通道的Mat类型,我们通常可以用如下形式来构建:
Mat test(2,3,CV_8UC3,Scalar(0,22,23));
前两个参数给出了矩阵的行列信息,第三个参数给出了矩阵的通道数目以及位深,最后一个参数则是给元素赋初值(可以暂时忽略,后续赋值)
2.使用create()成员函数
利用Mat类的成员函数来进行Mat类的初始化,使用方法如下:
- Mat test;
- test.create(4,4,CV_BUC2);
具体参数的含义我就不说了吧...
3.使用函数初始化特定矩阵
这种方法和Matlab中创建数组的方法一致,可以用于建立全零、全一、对角阵,使用方法如下:
- Mat E=Mat::eye(4,4,CV_64F);
- Mat O=Mat::ones(2,2,CV_32F);
- Mat Z=Mat::zeros(3,3,CV_8UC1);
4.小矩阵直接赋值
当所需矩阵较小时,可以通过”<<"运算符对其直接初始化赋值,使用方法如下:
Mat C=(Mat_<double>(3,3)<<0,1,2,3,4,5,6,7,8);
5.通过已有矩阵赋值
通过clone()函数对已有的矩阵或者数组进行深复制(不是新建信息头,相当于克隆,这个用的很多),将其赋值给待初始化的数组,类似于c++中的深拷贝。
- //通过已有数组赋值
- float b[4]={5,6,7,8};
- Mat c = Mat(2,2,CV_32F,b).clone();
- //抽取矩阵某一行赋值
- Mat C = (Mat_<double>(3, 3) << 0, 1, 2, 3, 4, 5, 6, 7, 8);
- Mat RowClone = C.row(1).clone();
-
矩阵创建完后需要对矩阵进行访问,以利用矩阵的值进行相应的操作。元素的访问方式有很多,用的最多的就是类名直接访问吧(.at()),另外就是通过指针进行访问(.ptr()),具体用法不在赘述。mat类是图像处理过程中必用的一大类,细节性的知识很多,这里就等着大家去深挖了。
point类:
Point类常常是用与描述二维坐标系下点的位置,其使用方式如下:
- Point point1= Point(1,2);
- Pointe point2;
- point2.x=2;
- point2.y=1;
point类用的也是比较多的,用法有很多,经常与vector类联系,后期手写轨迹的处理都是需要通过point类来进行操作的。
size类:
Size类是一个常用于描述图片尺寸的二元素数组,实质上也就是一个模板列,其成员变量包括width和height,都需要为int。常用初始化如下:
- Size size(600,800) //Size(width,height)
size类也是在开发过程中经常用到的,视窗和图像的大小参数都是可以通过size类来进行调节的。
除了这些常用类外还有一些常用的API也是需要掌握的,比如文件操作、c++的常用类、回调函数、windowsAPI等,其实这方面我也是小白,就不献丑了,各位还是多看看大佬的文章比较好。
生成训练图片
下边的代码是github上一位大佬写的,我只不过是根据自己的工作需要把工程改了一下而已,忘记链接是什么了,小编在这里先拿来跟大家分享一下,如有侵权,请私信我删除,谢谢!
- #include <iostream>
- #include <opencv2\opencv.hpp>
-
- using namespace std;
- using namespace cv;
-
- Point clickPoint;
- Mat matHandWriting;
- bool cc = true;
- void on_Mouse(int event, int x, int y, int flags, void*);
-
- int main(int argc, char** argv)
- {
- matHandWriting.create(80, 80, CV_8UC1);
- matHandWriting = Scalar::all(0);
- //共输入100个样本
- int intName[100];
- for (int i = 0; i < 100; i++)
- {
- intName[i] = i;
- }
-
- namedWindow("win", WINDOW_NORMAL);
- resizeWindow("win", 80, 80);
- setMouseCallback("win", on_Mouse, 0);
- //把样本命名为count.png保存
- int count = 0;
- while (count < 100)
- {
- stringstream ss;
- ss << intName[count];
- string stringName;
- ss >> stringName;
- imshow("win", matHandWriting);
- int key = waitKey(0);
- if (key == 32 && cc) //第一次空格键按下保存
- {
- cc = false;
- imwrite(stringName+".png", matHandWriting);
- cout << count << " ";
- count++;
- }
- else if (key == 32 && !cc) //第二次空格键按下清除,开始进行下次录入
- {
- cc = true;
- matHandWriting = Scalar::all(0);
- imshow("win", matHandWriting);
- }
- else if (key == 27) //esc退出
- {
- break;
- }
- }
-
- return 0;
- }
- //读取鼠标状态
- void on_Mouse(int event, int x, int y, int flags, void*)
- {
- // 如果鼠标不在窗口中则返回
- if (x < 0 || x >= matHandWriting.cols || y < 0 || y >= matHandWriting.rows)
- return;
-
- // 如果鼠标左键被按下,获取鼠标当前位置;当鼠标左键按下并且移动时,绘制白线;
- if (event == EVENT_LBUTTONDOWN)
- {
- clickPoint = Point(x, y);
- }
- else if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON))
- {
- Point point(x, y);
- line(matHandWriting, clickPoint, point, Scalar::all(255), 6, 8, 0);
- clickPoint = point;
- imshow("win", matHandWriting);
- }
- }

该部分实现的是录入样本并保存为图像文件,为后续训练使用。当然这个过程也可以根据需要录入更为完善的mnist数据集(主要是电脑吃不消。。)那样训练得到的特征量会更加具有普遍性。这里是我整理的mnist数据集、训练数据集的例程、手写识别例程。至于训练过程我就不细说了,工程里边注释的都很清楚,有兴趣的可以试一下(应该是可以用的,github找的,网上资源很多)。奥,对了,opencv用的是3.4.14版本的,这里有下载链接及库的添加教程(是不是很懂你们。。)
生成XML文件
话不多说,直接上代码
- #include <iostream>
- #include <opencv2\opencv.hpp>
-
- using namespace cv;
- using namespace std;
-
- int main()
- {
- Mat matClassificationInts; // 保存我们感兴趣的字符,0~9
- Mat matTrainingImagesAsFlattenedFloats; // 保存训练图片中所有单个字符ROI
-
- for (int i = 0; i < 10; i++) // 0-9十个数字
- {
- for (int j = 0; j < 10; j++) //每个数字训练十次(这里要和你录入的样本相对应)
- {
- matClassificationInts.push_back(i);
- }
- }
-
- int intName[100];
- for (int i = 0; i < 100; i++)
- {
- intName[i] = i;
- }
- //读取0-99.png,攻读取100次(如:0-9.png对应的是数字0,10-19.png对应数字1,依次...)
- for (int i = 0; i < 100; i++)
- {
- stringstream ss;
- ss << intName[i];
- string stringName;
- ss >> stringName;
- Mat matROI = imread("numRecognize\\"+stringName+".png", 0);
- Mat matROICopy = matROI.clone();
- vector<vector<Point>> contours;
- vector<Vec4i> hierarchy;
- findContours(matROI, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
- Rect boundRect = boundingRect(contours[0]);
- Mat numImage = matROICopy(boundRect).clone();
- resize(numImage, numImage, Size(40, 40));
-
- /* 这里计算目标图像的HOG特征(方向梯度直方图特征)代替之前用的灰度特征 */
- HOGDescriptor *hog = new HOGDescriptor(Size(40, 40), Size(16, 16), Size(8, 8), Size(8, 8), 9);
- vector<float> descriptors;
- hog->compute(numImage, descriptors);
- Mat dst(1, (int)(descriptors.size()), CV_32FC1, descriptors.data());
-
- matTrainingImagesAsFlattenedFloats.push_back(dst);
- }
-
- // 保存分类文件为 classifications.xml
- FileStorage fsClassifications("classifications.xml", FileStorage::WRITE);
-
- if (fsClassifications.isOpened() == false) {
- cout << "ERROR: 无法打开训练分类文件classifications.xml\n\n";
- system("pause");
- return 0;
- }
-
- fsClassifications << "classifications" << matClassificationInts; // write classifications into classifications section of classifications file
- fsClassifications.release(); // close the classifications file
-
- // 保存训练图片文件为 images.xml
- FileStorage fsTrainingImages("images.xml", FileStorage::WRITE);
-
- if (fsTrainingImages.isOpened() == false) {
- cout << "ERROR: 无法打开训练图片文件images.xml\n\n";
- system("pause");
- return 0;
- }
-
- fsTrainingImages << "images" << matTrainingImagesAsFlattenedFloats; // write training images into images section of images file
- fsTrainingImages.release();
-
- cout << "成功生成xml文件!\n" << endl;
- //system("pause");
- return 0;
- }
当然,这个过程也不一定非要用自己录入样本,上边上传的资料里有比较全面的手写数据集,也可以直接用它来生成训练模型(好几万个样本,估计需要一点时间),好处是样本量足够大,准确率也会提高,资料里也有附带的把训练集生成xml文件的例程(我没有这样做,应该是差不多的)。
测试
生成训练模型之后,之前的那些函数都可以屏蔽掉了,测试函数所需要的就是生成的xml文件,下边是主函数的代码
- #include <iostream>
- #include <opencv.hpp>
- #include <opencv2\ml\ml.hpp>
-
- using namespace cv;
- using namespace std;
-
- Mat matHandWriting;
- Point clickPoint;
- bool boolRecognize = true;
-
- void on_Mouse(int event, int x, int y, int flags, void*);
-
- void helpText()
- {
- cout << "操作提示:" << endl;
- cout << "\t在窗口写数字,写完后按【空格键】识别,控制台输出识别结果" << endl;
- cout << "\t再次按【空格键】清除所写内容,然后进行下一次书写\n" << endl;
- cout << "识别结果:";
- }
-
- int main()
- {
- FileStorage fsClassifications("classifications.xml", FileStorage::READ); // 读取 classifications.xml 分类文件
-
- if (fsClassifications.isOpened() == false) {
- cout << "ERROR, 无法打开classifications.xml\n\n";
- system("pause");
- return 0;
- }
-
- Mat matClassificationInts;
- fsClassifications["classifications"] >> matClassificationInts; // 把 classifications.xml 中的 classifications 读取进Mat变量
- fsClassifications.release(); // 关闭文件
-
- FileStorage fsTrainingImages("images.xml", FileStorage::READ); // 打开训练图片文件
-
- if (fsTrainingImages.isOpened() == false) {
- cout << "ERROR, 无法打开images.xml\n\n";
- system("pause");
- return 0;
- }
-
- // 读取训练图片数据(从images.xml中)
- Mat matTrainingImagesAsFlattenedFloats; // we will read multiple images into this single image variable as though it is a vector
- fsTrainingImages["images"] >> matTrainingImagesAsFlattenedFloats; // 把 images.xml 中的 images 读取进Mat变量
- fsTrainingImages.release();
-
- // 训练
- Ptr<ml::KNearest> kNearest(ml::KNearest::create()); // 实例化 KNN 对象,邻近处理
-
- // 最终调用train函数,注意到两个参数都是Mat类型(单个Mat),尽管实际上他们都是多张图片或多个数
- kNearest->train(matTrainingImagesAsFlattenedFloats, ml::ROW_SAMPLE, matClassificationInts);
-
- // 测试
- matHandWriting.create(Size(160, 160), CV_8UC1);//创建图像
- matHandWriting = Scalar::all(0); //初始化窗口
- imshow("手写数字", matHandWriting);
- setMouseCallback("手写数字", on_Mouse, 0);//鼠标回调函数
-
- helpText();
- ///
- while (true)
- {
- int key = waitKey(0);
- if (key == 32 && boolRecognize)//空格键按下
- {
- boolRecognize = false;
-
- Mat matROICopy = matHandWriting.clone();//将所有matHandWriting拷贝到matROICopy
- vector<vector<Point>> contours;
- //是一个向量,并且是一个双重向量,
- //向量内每个元素保存了一组由连续的Point点构成的点的集合的向量,
- //每一组Point点集就是一个轮廓。 有多少轮廓,向量contours就有多少元素
- vector<Vec4i> hierarchy;
- /*
- 这是openCV里面找边界的程序里面的语句,
- contours被定义成二维浮点型向量,
- 这里面将来会存储找到的边界的(x,y)坐标。
- vector<Vec4i>hierarchy是定义的层级。这个在找边界findcontours的时候会自动生成,
- 这里只是给它开辟一个空间。
- */
- findContours(matHandWriting, contours, hierarchy, CV_RETR_TREE, CHAIN_APPROX_SIMPLE);
- // 多边形逼近轮廓 + 获取矩形和圆形边界框
- Rect boundRect = boundingRect(contours[0]);
- Mat numImage = matROICopy(boundRect).clone();
- resize(numImage, numImage, Size(40, 40));
-
- /* 这里计算目标图像的HOG特征(方向梯度直方图特征)代替之前用的灰度特征 */
- HOGDescriptor *hog = new HOGDescriptor(Size(40, 40), Size(16, 16), Size(8, 8), Size(8, 8), 9);
- vector<float> descriptors;
- hog->compute(numImage, descriptors);
- Mat matROIFlattenedFloat(1, (int)(descriptors.size()), CV_32FC1, descriptors.data());
-
- Mat matCurrentChar(0, 0, CV_32F); // findNearest的结果保存在这里
-
- // 最终调用 findNearest 函数
- kNearest->findNearest(matROIFlattenedFloat, 1, matCurrentChar);
-
- int intCurrentChar = (int)matCurrentChar.at<float>(0, 0);
- cout << intCurrentChar << " "; //显示识别结果
- }
- else if (key == 32 && !boolRecognize)//空格键再次按下
- {
- boolRecognize = true;
- matHandWriting = Scalar::all(0);
- imshow("手写数字", matHandWriting);
- }
- else if (key == 27) //esc退出
- break;
- }
-
- return 0;
- }
-
- void on_Mouse(int event, int x, int y, int flags, void*)
- {
- // 如果鼠标不在窗口中则返回
- if (x < 0 || x >= matHandWriting.cols || y < 0 || y >= matHandWriting.rows)
- return;
-
- // 如果鼠标左键被按下,获取鼠标当前位置;当鼠标左键按下并且移动时,绘制白线;
- if (event == EVENT_LBUTTONDOWN)
- {
- clickPoint = Point(x, y);
- }
- else if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON))
- {
- Point point(x, y);
- line(matHandWriting, clickPoint, point, Scalar::all(255), 12, 8, 0);
- clickPoint = point;
- imshow("手写数字", matHandWriting);
- }
- }
个人建议把生成图片、训练样本、测试函数放到一个源文件中去,需要做哪个步骤的时候就把另外的两个函数屏蔽掉,只执行要用的函数,这样会方便一点。这里提供的只是一个大致的思路,后期可以根据自己的需要来进行相应的改写,比如连接触摸屏或者别的一些能够获取坐标点的设备,再把坐标点连线,最后生成图片训练,效果和用鼠标画出来的线是一样的,之只不过这个过程中可能会用到一些其他的类。总之思路提供给大家了,后期的完善就看各位了。上传的资料里边的工程亲测可用(前提是环境一定要搭建好,我用的vs2019社区版)。
最后还是那句话,个人也是第一次接触图像处理相关的知识(不过是用到了一些皮毛而已),如果有不对的地方欢迎大家提出,不胜感激!

