
- 1Vue3源码学习之路-实现runtime-core_vue runtime-core
- 2【OD统一考试( C&D 卷)】分披萨(200 分),JAVA 解答_分披萨 华为od
- 3web音频采集与播放
- 4值得细读的8个视觉大模型生成式预训练方法_视觉大模型预训练
- 5未来十年,IT行业依然凭借高薪魅力跻身就业前列_it行业未来十年
- 6钉钉对接全网AI,最好的智能管家方案。详细步骤,喂饭教程。_linkai接入
- 7spark远程debug_spark-shell debug调试
- 8虚拟机VM利用U盘重装系统_虚拟机u盘启动装系统
- 9Docker:官方拉取限制问题_docker被墙
- 10Elasticsearch:Open Crawler 发布技术预览版_open crawler elastic
python进行批量图片文字识别_python 识别
赞
踩
一、概述
ocr技术是当下比较热门的技术,利用它可以方便的对图片上的文字进行扫描识别,本文使用python+百度api实现图片的文字识别。
二、环境准备:
1. python环境的准备
1.1 首先需要到python官网下载最新版本的python,点击python下载。下载完成后进行安装,程序会自动进行环境变量配置。
安装配置完成后,运行python -v 若出现版本则表示安装成功。
- >python --version
- Python 3.9.6
1.2 安装百度api库。python安装完成后,运行以下命令安装百度api库
pip install baidu-aip2. 百度云api的注册
接下来需要进行百度api的注册申请,点击百度ai进入官网
进入官网后,点击右上角控制台
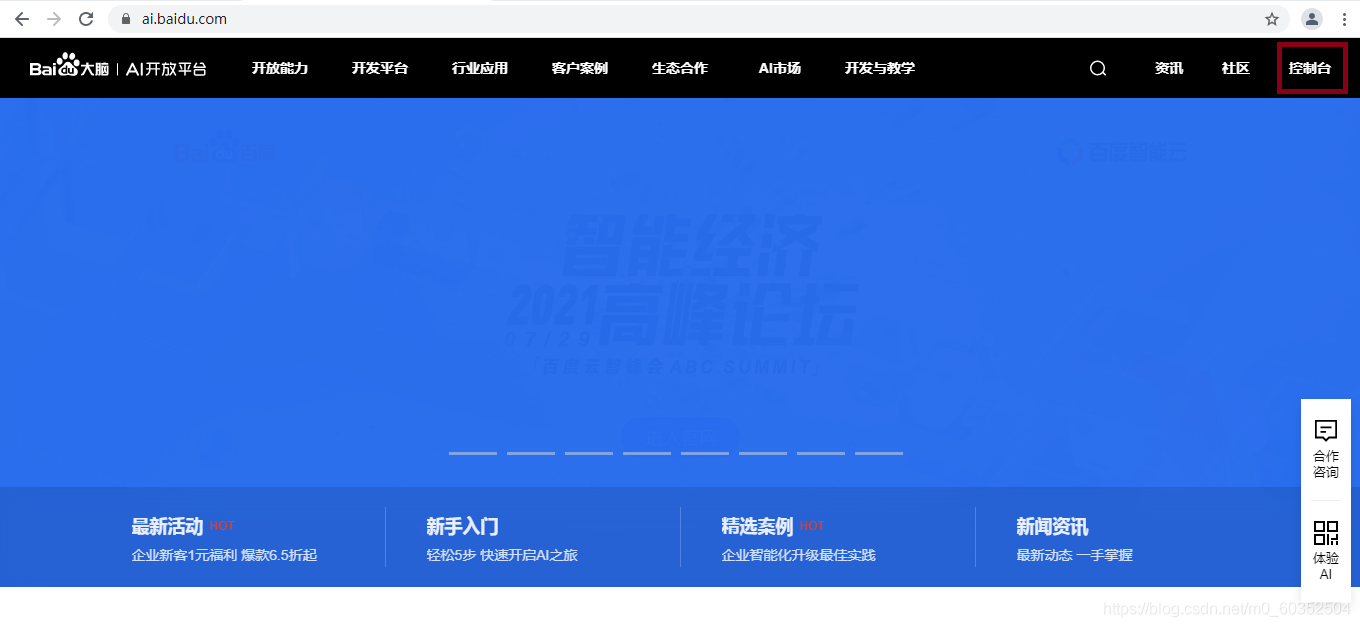
进行账号登陆,登陆完成后出现控制台界面,点击左侧产品服务——人工智能——文字识别。

点击创建应用,并在相应页面填写好相关信息,然后点击立即创建。
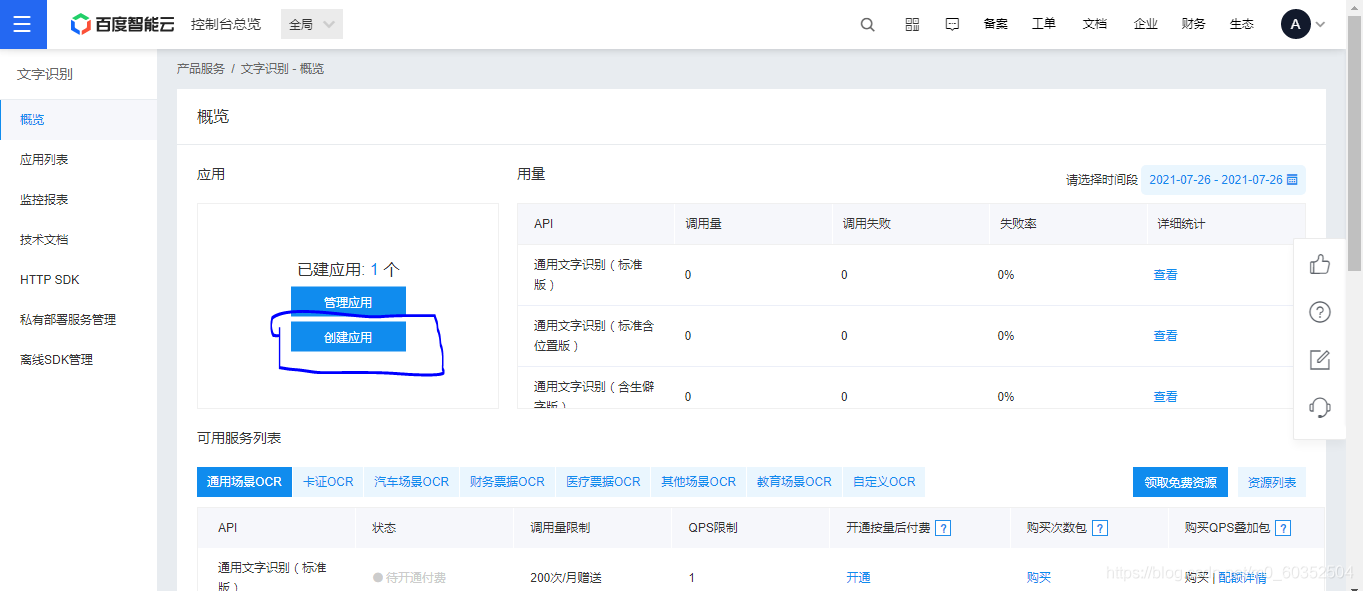
创建完成后回到控制台点击管理应用。

刚刚创建好的文字识别应用就会出现在应用列表中,其中的APP_ID,API_KEY,SECRET_KEY需要记住,这三项是我们需要用到的。

三、实现:
1. 首先要在当前文件夹下建立一个text目录,用于存放识别出的文本文件。对文件夹内的所有图片进行识别,需要用到os.walk(path)函数来遍历目录,并寻找所有后缀为jpg格式的图片。walk()方法语法格式为
os.walk(top, topdown = True, onerror = None, followlinks = False)
代码如下:
- for path,dir,file in os.walk(path):
- break
- pic=[]
- for i in file:
- if(".jpg" in i):
- pic.append(i)
由于walk函数递归查找目录,我们只在当前目录下寻找图片,因此在第一次循环结束就直接break,当前目录下所有图片名保存在pic变量里
2. 使用百度api来进行图片识别
- APP_ID = 'aaa'
- API_KEY = 'bbb'
- SECRET_KEY = 'ccc'
- client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
- dic_result=client.basicAccurate(image)
其中"aaa","bbb","ccc"是之前申请百度api中得到的APP_ID,API_KEY,SECRET_KEY三个对应值。识别结果保存在dic_result变量中。其中basicAccurate(image)为高精度识别函数,如果使用低精度识别,请使用accurate(image)函数
3. 项目代码如下:
- import os
- from aip import AipOcr
- APP_ID = 'aaa'
- API_KEY = 'bbb'
- SECRET_KEY = 'ccc'
- client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
-
-
- path="./"
- for path,dir,file in os.walk(path):
- break
- pic=[]
- for i in file:
- if(".jpg" in i):
- pic.append(i)
-
-
- def i2t(picname):
- with open(picname,'rb') as fp:
- image=fp.read()
- dic_result=client.basicAccurate(image)
- res=dic_result['words_result']
- result=''
- for m in res:
- result+=str(m['words'])
-
- fp2=open('./text/a.txt','a')
-
-
- fp2.write(result)
- fp2.close()
-
-
- n=1
- for j in pic:
- print("picture%d %s...\n" %(n,j))
- i2t(j)
- n=n+1

四、运行效果
程序扫描了目录下的2张照片,并将扫描内容存入text文件夹下的文本文档。识别过程如下:
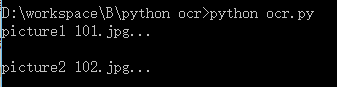


程序扫描出的文字

五、总结:
1. python实现的是命令行界面的识别过程,比较简单,可以考虑做成图形界面。
2. 在写入中文文档时若报错,可将文件打开格式设置为”utf-8“
fp2=open('./text/a.txt','a',encoding='utf-8')
