
- 1如何把AI聊天模型接入QQ_给qq接入ai
- 2文件上传下载容易引发的安全问题及如何预防_上传文件安全性考虑
- 3本地连接虚拟机中Redis出现的问题(远程连接redis)_本地连不上虚拟机的redis
- 4【案例分析】基于IMDb数据集的印度电影信息剖析_imdb电影信息
- 5已成功与服务器建立连接,但是在登录过程中发生错误。(provider: SSL提供程序,error:0-证书链是由不受信任的颁发机构颁发的。)_已成功与服务器建立连接,但是在登录过程中发生错误。 (provider: ssl 提供程序, e
- 6Android:双非大二3轮技术面+HR面(1),三面蚂蚁核心金融部_mateapp hr面
- 7第三章-AllData数据中台-开源团队_alldatadc
- 8如何下载视频号的视频文件?_视频号下载文件报错
- 9由maven sources.jar逆向成可运行的java工程_reverse-m2-sources
- 10面试?跳槽?涨薪?这些你必须先了解:互联网大厂的薪资和职级一览!_腾讯产品职级
简易搜索引擎原理与基于Hadoop MapReduce的搜索引擎实现_hadoop 搜索引擎
赞
踩
摘要
本文介绍简单搜索引擎的原理,并基于Hadoop完成针对同济新闻网的搜索引擎构建。
本文所述搜索引擎较为简单,无法达到商用级别,但仍可管中窥豹,学习其基本原理,并锻炼编写 Map Reduce 程序的能力。
阅读目标
了解搜索引擎工作原理,并编写简单的搜索引擎。
搜索引擎原理
搜索引擎长什么样
搜索引擎这个词,大家一定不陌生。百度,必应,或是谷歌,它们早已陪伴在我们身边。当我们想要知道一些问题的答案,只需要将关键词输入给搜索引擎,或者写一个句子给它,它将把问题的答案告诉我们。
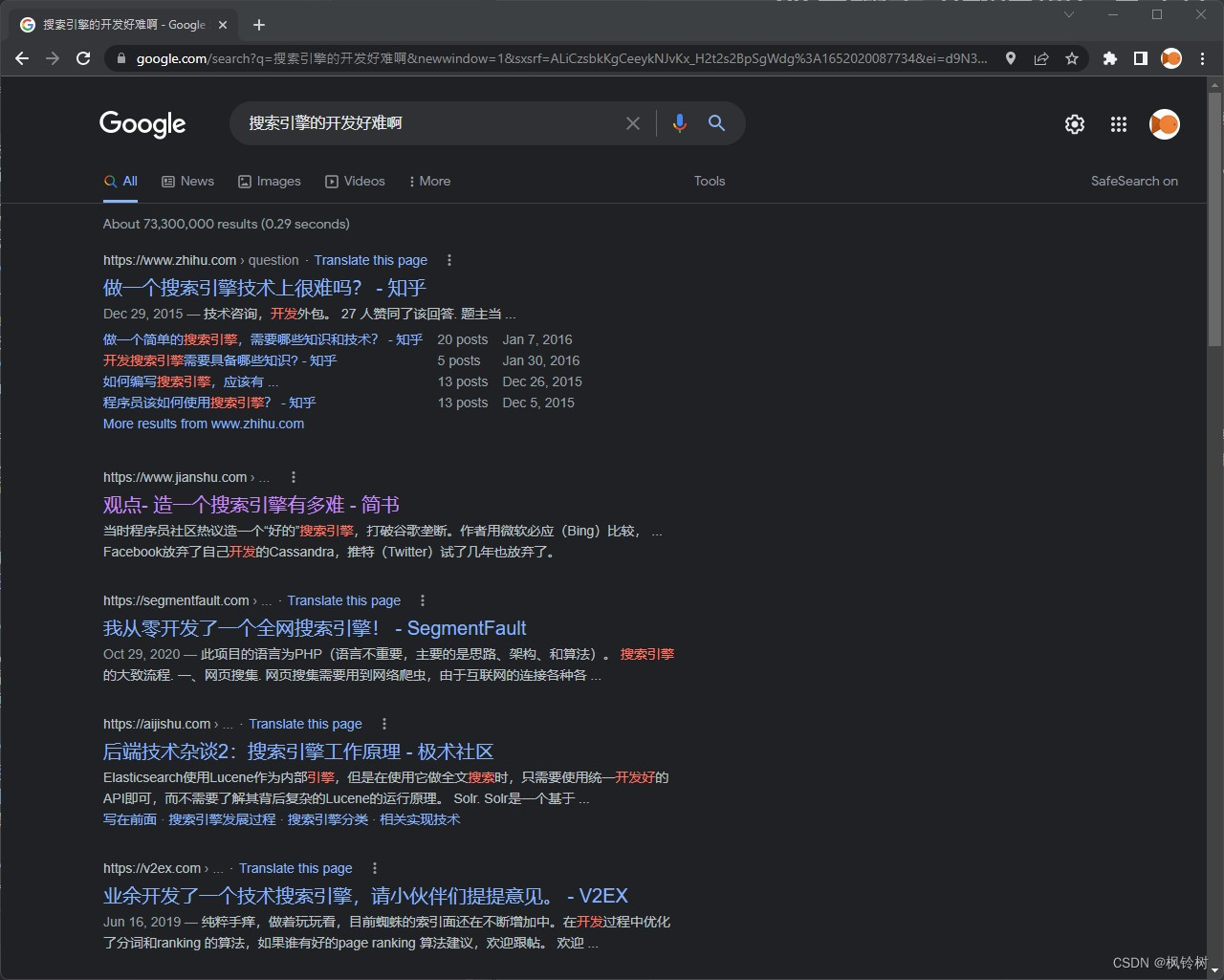
如图所示,当我们搜索一段内容,搜索引擎告诉我们一些结果。
不难发现,这些结果是有序的。我们能感受到,越靠上的结果确实是我们越感兴趣的。
我们可能做不到那么精准的排序算法,但是仍然可以做一个简单一些的。
此外,不难发现,我们的输入被切分成多个词,正如图中标红的所示。
结果是从哪里来的
搜索引擎将结果递交给我们。那么,结果从哪里来?
当然,它可以根据我们输入的搜索词,借助爬虫技术从互联网获取数据,然后将结果交给我们。但如果真是这样,当我们输入完搜索内容并按下回车,可能要去泡一碗葛粉细细品味后,才能得到搜索结果。
因此,搜索引擎需要将互联网上的大量数据存储在本地,并根据我们的输入内容从中寻找内容,并呈现过我们。
这些数据从哪里来?还是需要爬虫。只不过,爬虫本身和搜索过程是分离的。爬虫爬取到互联网上的大量数据,通过一些流程处理成可以供搜索引擎读取的数据。之后,每当我们按下回车,搜索引擎从处理过的数据里寻找我们需要的内容,并呈现。
后文中,我们将以一个简单的设计模型讲解搜索引擎原理。它会与专业的商用搜索引擎有所差异,但不影响基础知识的学习。
原始数据如何存储
搜索引擎后台需要存储互联网上的大量数据。如何存储是个问题。为方便处理,我们可以令文件中的每一行代表一个页面的信息。这些信息包括但不限于:
- 链接地址
- 标题
- 时间
- 内容
它们之间以特殊方式分隔。为了方便,我们使用 \u0007 分隔它们。
不难意识到,我们需要将内容中的所有换行替换成其他字符,例如空格。
此外,我们需要保证原始内容中没有 \u0007。我们的例子中假设该结论成立。聪明的读者可以设计更完善的版本。
它就像这样(其中,\u0007 用
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

