
- 1微信小程序获取手机号(Java后端)_微信小程序 getphonenumber
- 2树莓派 默认波特率_树莓派初次使用的基本配置.md
- 3图解微信小程序---scroll_view实现首页排行榜布局
- 4MarkDown编辑器在线
- 5LoRa无线通信技术介绍(一)调制技术
- 651单片机红外遥控小车_51单片机智能小车红外遥控器
- 7力扣第210题“课程表 II”
- 8经典论文复现|手把手带你复现ICCV 2017经典论文—PyraNet
- 9决策树学生成绩python_基于Python数据分析之pandas统计分析
- 10Xilinx FPGA中的基础逻辑单元--CLB/Block Memory/DSP/Transceivers/IO_fpga中的单元
C语言期末习题(结构体开始)
赞
踩
C语言期末习题汇总(超级硬核系列)
结构体
题目1: 结构体的基本概念
如有以下代码:
struct student
{
int num;
char name[32];
float score;
}stu;
- 1
- 2
- 3
- 4
- 5
- 6
则下面的叙述不正确的是:( )
A.struct 是结构体类型的关键字
B.struct student 是用户定义的结构体类型
C.num, score 都是结构体成员名
D.stu 是用户定义的结构体类型名
解析
struct student
{
int num;
char name[32];
float score;
}stu;//stu是变量
- 1
- 2
- 3
- 4
- 5
- 6
答案 :D
题目2:结构体成员的访问
下面程序的输出结果是:( )
struct stu { int num; char name[10]; int age; }; void fun(struct stu *p) { printf("%s\n",(*p).name); return; } int main() { struct stu students[3] = {{9801,"zhang",20}, {9802,"wang",19}, {9803,"zhao",18} }; fun(students + 1); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
A.zhang
B.zhao
C.wang
D.18
解析
(*p).name 是访问结构体,fun(students+1)意思是访问结构体的第二个成员,不管结构体的实例是什么——访问其成员其实就是加成员的偏移量。
答案 :C
题目3:结构体成员的访问
下面程序要求输出结构体中成员a的数据,以下不能填入横线处的内容是( )
#include < stdio.h >
struct S
{
int a;
int b;
};
int main( )
{
struct S a, *p=&a;
a.a = 99;
printf( "%d\n", __________);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
A.a.a
B.*p.a
C.p->a
D.(*p).a
解析
指针->成员
结构体变量. 成员
答案 :B
题目4:结构体对齐原则(超级重要)
在VS2013下,默认对齐数为8字节,这个结构体所占的空间大小是( )字节
typedef struct{
int a;
char b;
short c;
short d;
}AA_t;
- 1
- 2
- 3
- 4
- 5
- 6
A.16
B.9
C.12
D.8
解析
这个题目需要我们去画出内存图
图例1:


步骤一:首先标出所有类型的数的字节大小
步骤二:与默认对齐数进行对比,判断所占空间大小
步骤三:从0开始,开始计算,根据对齐原则,得到上述结果

题目5:结构体对齐原则
在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是( )
struct A
{
int a;
short b;
int c;
char d;
};
struct B
{
int a;
short b;
char c;
int d;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
A.16,16
B.13,12
C.16,12
D.11,16
解析

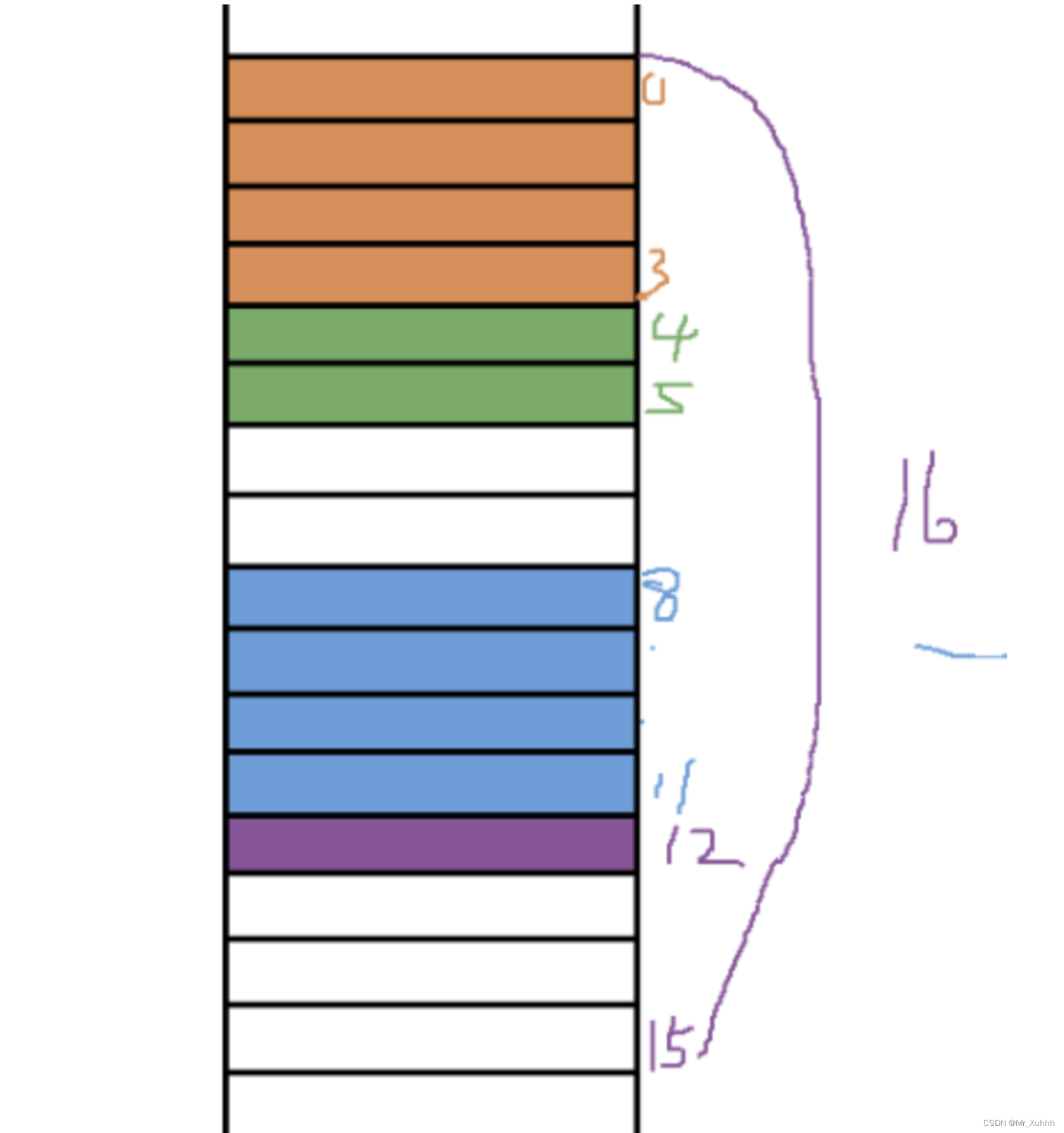

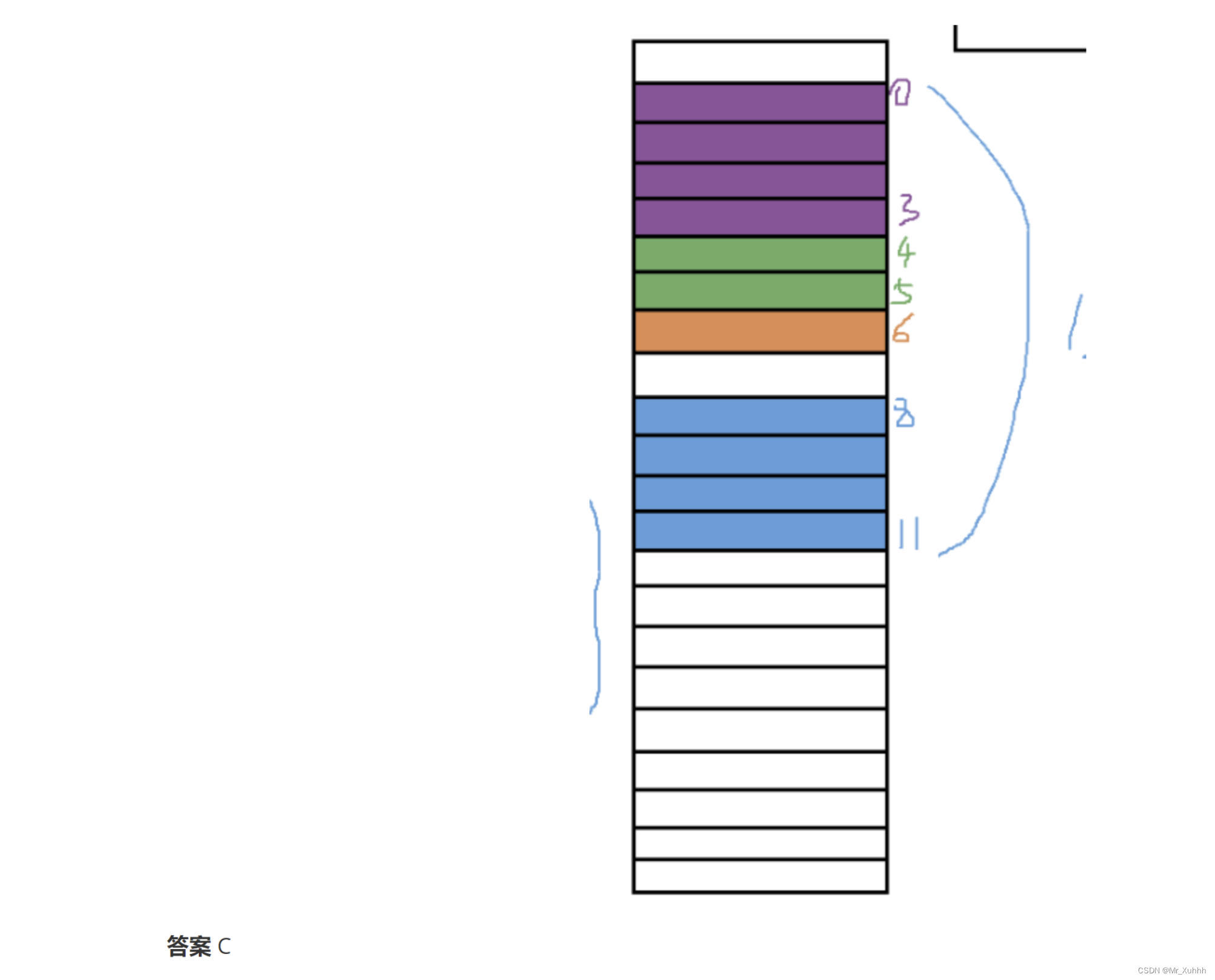
题目6:结构体对齐原则
下面代码的结果是:( )
#pragma pack(4)/*编译选项,表示4字节对齐 平台:VS2013。语言:C语言*/ //假设long 是4个字节 int main(int argc, char* argv[]) { struct tagTest1 { short a; char d; long b; long c; }; struct tagTest2 { long b; short c; char d; long a; }; struct tagTest3 { short c; long b; char d; long a; }; struct tagTest1 stT1; struct tagTest2 stT2; struct tagTest3 stT3; printf("%d %d %d", sizeof(stT1), sizeof(stT2), sizeof(stT3)); return 0; } #pragma pack()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
A.12 12 16
B.11 11 11
C.12 11 16
D.11 11 16
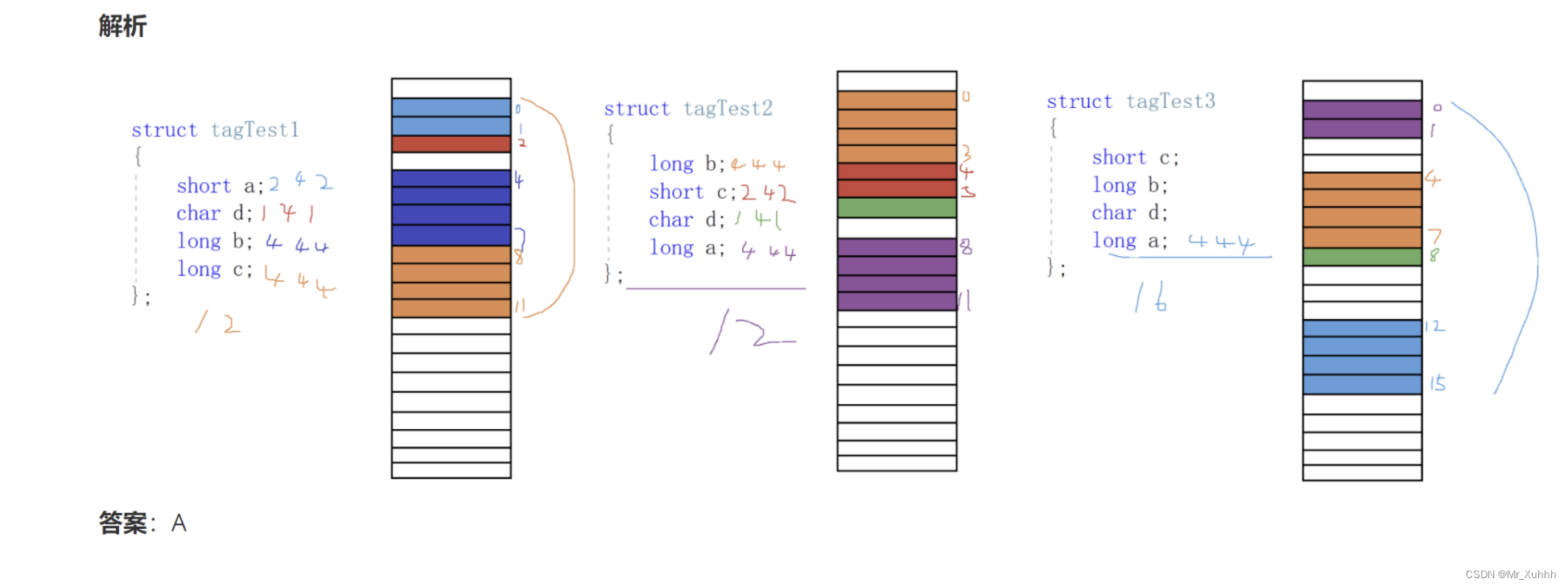
题目7:位段大小的计算
有如下宏定义和结构定义
#define MAX_SIZE A+B
struct _Record_Struct
{
unsigned char Env_Alarm_ID : 4;
unsigned char Para1 : 2;
unsigned char state;
unsigned char avail : 1;
}*Env_Alarm_Record;
struct _Record_Struct *pointer = (struct _Record_Struct*)malloc(sizeof(struct _Record_Struct) * MAX_SIZE);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
当A=2, B=3时,pointer分配( )个字节的空间。
A.20
B.15
C.11
D.9
解析
#define MAX_SIZE 2+3
struct _Record_Struct
{
unsigned char Env_Alarm_ID : 4;//1个字节是八个比特位,这个位段是占4个比特位
unsigned char Para1 : 2;//这个是占2个比特位
//上面两个一共占了6个比特位,占了1个字节
unsigned char state;//没有进行表识,说明了它独占1个字节
unsigned char avail : 1;//这也占了一个字节
}*Env_Alarm_Record;
struct _Record_Struct *pointer = (struct _Record_Struct*)malloc(sizeof(struct _Record_Struct) * 2+3);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
答案:D
题目8:位段大小的计算+大小端字节序存储+结构体访问
下面代码的结果是( )
int main() { unsigned char puc[4]; struct tagPIM { unsigned char ucPim1; unsigned char ucData0 : 1; unsigned char ucData1 : 2; unsigned char ucData2 : 3; }*pstPimData; pstPimData = (struct tagPIM*)puc; memset(puc,0,4); pstPimData->ucPim1 = 2; pstPimData->ucData0 = 3; pstPimData->ucData1 = 4; pstPimData->ucData2 = 5; printf("%02x %02x %02x %02x\n",puc[0], puc[1], puc[2], puc[3]); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
A.02 03 04 05
B.02 29 00 00
C.02 25 00 00
D.02 29 04 00
解析

枚举
题目1:枚举类型的存储类型
以下关于枚举的说法,哪个是正确的?()
A.枚举类型可以具有浮点数作为枚举值。
B.枚举类型在内存中存储为整数。
C.枚举类型可以包含字符串作为枚举值。
D.枚举类型不能作为函数的参数传递。
解析:
枚举类型在内存中存储为整数,浮点数和整数都不可以,正确答案为B。
D枚举类型能作为函数的参数传递
例子如下:
#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> enum COLOR { RED, BLACK }co; void Func(enum COLOR x) { } int main() { Func(RED); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
题目2:枚举的计数方式
下面代码的结果是:( )
enum ENUM_A
{
X1,
Y1,
Z1 = 255,
A1,
B1,
};
enum ENUM_A enumA = Y1;
enum ENUM_A enumB = B1;
printf("%d %d\n", enumA, enumB);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
A.1, 4
B.1, 257
C.2, 257
D.2, 5
解析:
因为枚举没有特意说明,默认是从零开始,所以X1是0,Y1是1,但是Z1是已经定义好255,所以默认是从255开始计数,所以B1=257
答案为B
题目3:枚举常量和#define定义常量的区别
关于枚举常量和#define 定义常量,下面哪个表述是不严谨的?()
A.可读性更好:枚举符号提供了有意义的标识符,可以更清晰地表达代码的意图。相比之下,#define定义的符号只是简单的文本替换,不具备语义上的含义。
B.和#define定义的标识符比较枚举有类型检查,更加严谨
C.枚举常量是遵循作用域规则的,枚举声明在函数内,只能在函数内使用,#define定义的符号没有作用域概念,会在整个代码中进行文本替换
D.#define没有类型检查,使用更加方便,更加推荐使用
解析:
答案为D,没有谁好谁坏之分,相对来说
联合体
题目1:联合体大小计算
下面代码的结果是:( )
#include <stdio.h>
union Un
{
short s[7];
int n;
};
int main()
{
printf("%d\n", sizeof(union Un));
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
A.14
B.4
C.16
D.18
解析:
联合的⼤⼩⾄少是最⼤成员的⼤⼩。
当最⼤成员⼤⼩不是最⼤对⻬数的整数倍的时候,就要对⻬到最⼤对⻬数的整数倍。
这个题目中最大成员的大小是short s[7],14个字节,然后可以排除B,接着还要满足条件2,int 类型是4个字节大小,VS默认的对齐数是8,会跟VS进行大小的比较,取较小数作为最大对齐数,所以4是最大对齐数,但是14不是4的整数倍,所以答案是16,选择C
题目2:结构体大小计算+大小端字节序存储
在X86下,小端字节序存储,有下列程序
#include<stdio.h>
int main()
{
union
{
short k;
char i[2];
}*s, a;
s = &a;
s->i[0] = 0x39;
s->i[1] = 0x38;
printf("%x\n", a.k);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出结果是( )
A.3839
B.3938
C.380039
D.不确定
题干中涉及到大小端字节序存储,要画出内存图来进行判断
如下:

对联合体进行计算,根据计算规则,大小至少是最大成员的大小,且满足是最大对齐数的整数倍,所以结果是2,按照从零开始画出内存图,根据上面的代码可以清楚的看出0里面存放的是0x39,1里面存放的是0x38,也要注意规定低地址和高地址,小段字节序存储会和我们的常识发生相反的认识,所以最后的答案是3839,答案是A
⼤⼩端字节序和字节序判断
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
看调试结果:
在a中的 0x11223344 这个数字是按照字节为单位,倒着存储的。
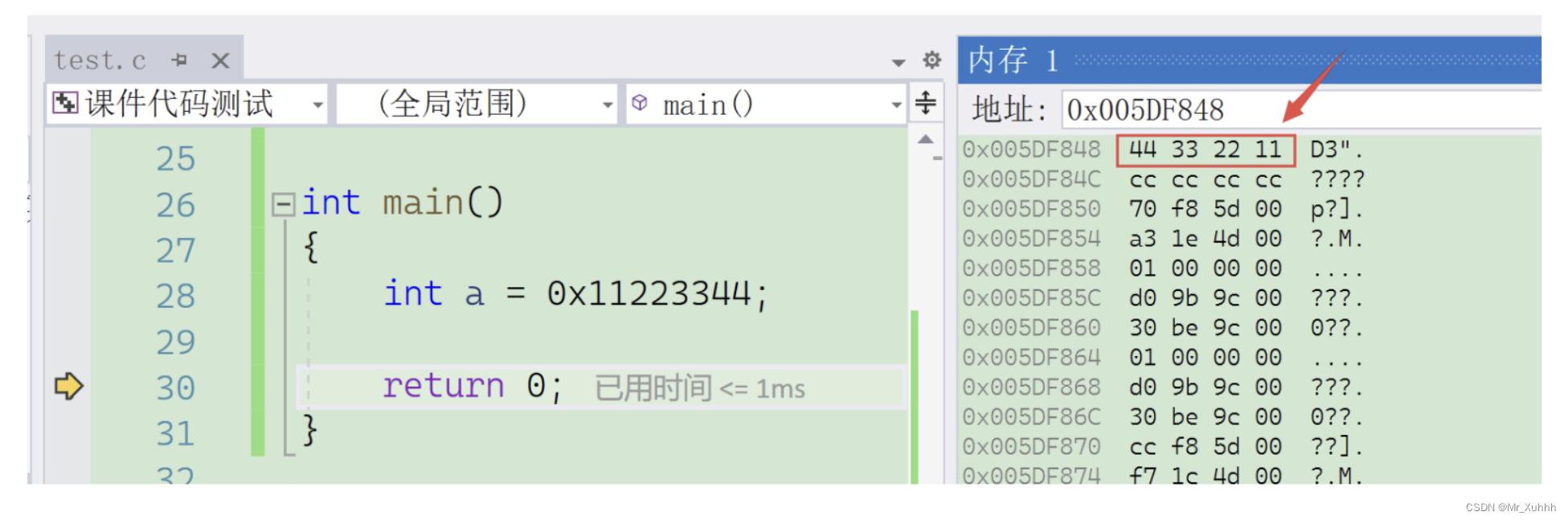
这就是一个小段字节序存储
题目3:使用联合体判断大小段
使用联合体的知识,写一个函数判断当前机器是大端还是小端,如果是小端返回1,如果是大端返回0.
引入:
int main()
{
int a=1;
//0x 00 00 00 01
//在内存中的存储方式
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7

此图为大小端字节序存储的图
如果说我们要判断哪个是大端,哪个是小端,我们只需要看其第一位就好了,00就是大端,01就是小端
根据我们之前所学的知识:
可以写出以下编程:
int main()
{
int a=1;
if(*(char*)&a==1)//我们只需要知道第一个字节大小,强制类型转化为char*,然后对其解引用判断值是否为1,进而判断大小端
{
printf("小端\n");
}
else
{
printf("大端\n");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
接下来是考虑联合体方面了
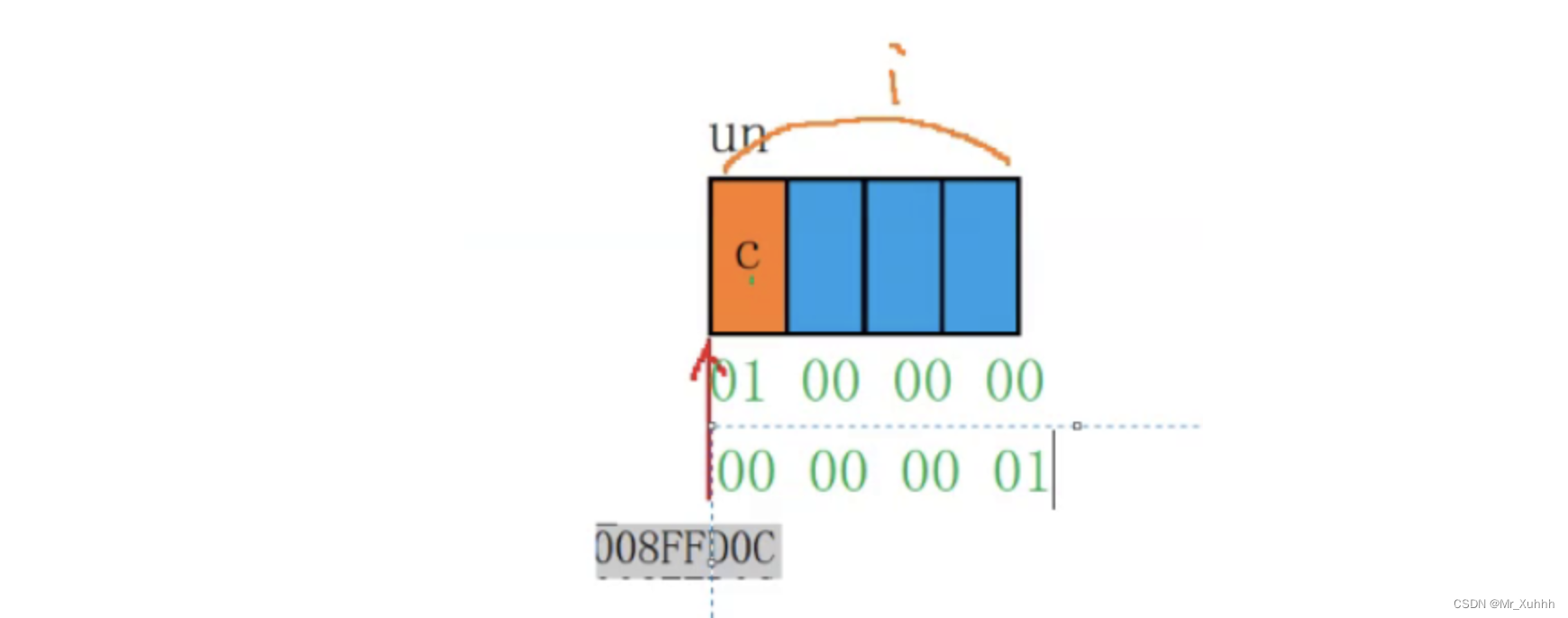
01开头的是小端,00开头的是大端
union Un { char c; int i; }; int main() { union Un un={0}; un.i=1;//根据结构体计算原则来看的 if(un,c==1) { printf("小端\n"); } else { printf("大端\n"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;//返回1是⼩端,返回0是⼤端
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
动态内存管理
题目1:对malloc函数的理解
关于动态内存函数的说法错误的是:( )
A.malloc函数向内存申请一块连续的空间,并返回起始地址
B.malloc申请空间失败,返回NULL指针
C.malloc可以向内存申请0字节的空间
D.malloc申请的内存空间,不进行释放也不会对程序有影响
解析:
答案为D,那么free函数的意义在哪里呢,而且释放完成之后还要对其置空
题目2:对malloc,calloc,realloc函数的理解
关于动态内存相关函数说法错误的是:( )
A.malloc函数和calloc函数的功能是相似的,都是申请一块连续的空间。
B.malloc函数申请的空间不初始化,calloc函数申请的空间会被初始化为0
C.realloc函数可以调整动态申请内存的大小,可大可小
D.free函数不可以释放realloc调整后的空间
解析:
A &B.calloc函数的参数有两个,并且它的初始值为0,而malloc函数的为随机值
D:只要是动态内存相关函数申请的空间,都要用free函数释放空间,所以答案为D
题目3:空间分布
动态申请的内存在内存的那个区域?( )
A.栈区
B.堆区
C.静态区
D.文字常量区
解析,答案为B
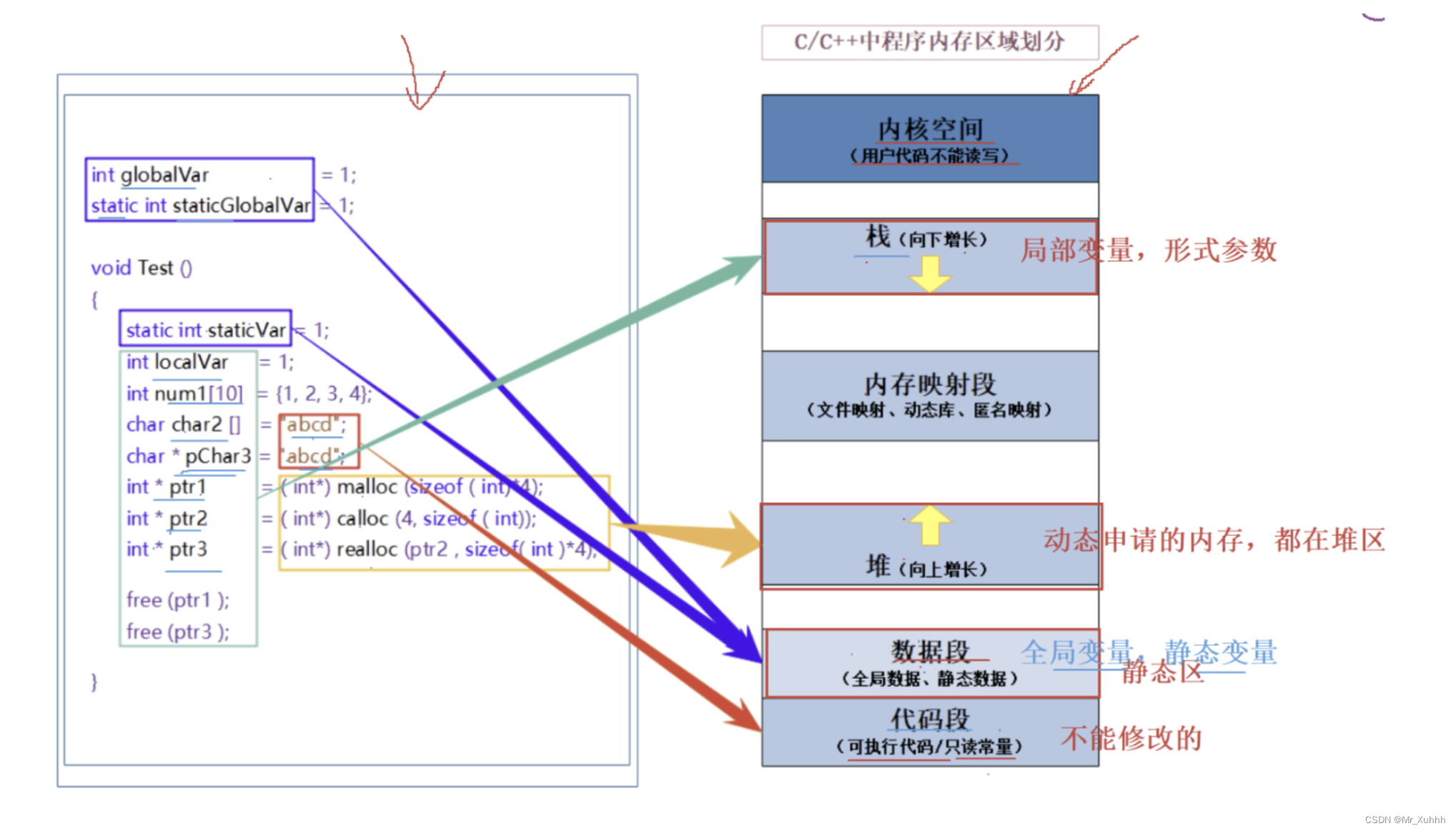
非常重要
题目4:动态内存管理的应用(校招常考,重点内容)
关于下面代码描述不正确的是:()
void GetMemory(char *p)
{
p = (char *)malloc(100);
}
void Test(void)
{
char *str = NULL;
GetMemory(str);
strcpy(str, "hello world");
printf(str);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
A.上面代码没问题
B.上面代码存在内存泄露
C.上面代码可能会崩溃,即使GetMemory函数返回,str依然为NULL
D.GetMemory函数无法把malloc开辟的100个字节带回来
解析:
答案为A,这是显而易见的,最简单的B选项,没有看到free函数释放空间,所以会存在内存泄露

它没有给str分配内存空间,所以CD都是对的,怎样进行修改呢?
#include <stdio.h> #include <string.h> #include <stdlib.h> void GetMemory(char** p)//二级指针,接受的是一级指针的地址 { *p = (char*)malloc(100);//对p进行解引用,开辟对应的空间 } void Test() { char* str = NULL; GetMemory(&str);//进行传址调用 strcpy(str, "hello world"); printf("%s\n",str); free(str); str == NULL;//对于动态内存相关函数都要free释放空间,并且置空 } int main() { Test(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果:

题目5:局部变量和动态内存管理函数的区别
关于下面代码描述正确的是( )
char *GetMemory(void)
{
char p[] = "hello world";
return p;
}
void Test(void)
{
char *str = NULL;
str = GetMemory();
printf(str);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
A.printf函数使用有问题
B.程序正常打印hello world
C.GetMemory函数返回的地址无法正常使用
D.程序存在内存泄露
解析:
局部变量有一个特点,出了作用域它开辟的内存就要被系统回收掉,所以呢虽然str能接收到return p返回的值,但是呢,此时可能打印出hello world 也可能不可能,因为它已经被操作系统回收了,也不存在内存泄露的问题,因为不是用的动态内存的相关的函数,所以答案是C
题目6:对动态内存管理错误的认识
以下哪个不是动态内存的错误( )
A.free参数为NULL
B.对非动态内存的free释放
C.对动态内存的多次释放
D.对动态内存的越界访问
解析:
答案为A
常见的动态内存管理的错误
1.对NULL指针的解引用操作
void test()
{
int *p = (int *)malloc(INT_MAX/4);
*p = 20;//如果p的值是NULL,就会有问题
free(p);
}
- 1
- 2
- 3
- 4
- 5
- 6
解决方法:
int main() { int* p = (int*)malloc(10*sizeof(int)); if (p == NULL)//先判断是不是空指针 { perror("malloc"); return 1; } //使用 int i = 0; for (i = 0; i < 10; i++) { p[i] = i;//*(p+i) } free(p); p = NULL; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.对动态开辟空间的越界访问
int main() { int* p = (int*)malloc(10 * sizeof(int)); if (p == NULL) { perror("malloc"); return 1; } //使用 int i = 0; for (i = 0; i < 40; i++)//只开辟了10个int 类型大小的空间,但是却要遍历40次,这就是越界访问了 { p[i] = i;//*(p+i) } free(p); p = NULL; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.对⾮动态开辟内存使⽤free释放
void test()
{
int a = 10;
int *p = &a;
free(p);//ok?
}
- 1
- 2
- 3
- 4
- 5
- 6
肯定不OK,百分之百会报错
4.使⽤free释放⼀块动态开辟内存的⼀部分
int main() { int* p = (int*)malloc(10 * sizeof(int)); if (p == NULL) { perror("malloc"); return 1; } //使用 int i = 0; for (i = 0; i <5; i++) { *p = i; p++;//p不再指向动态内存的起始位置 } free(p); p = NULL; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
如下图:
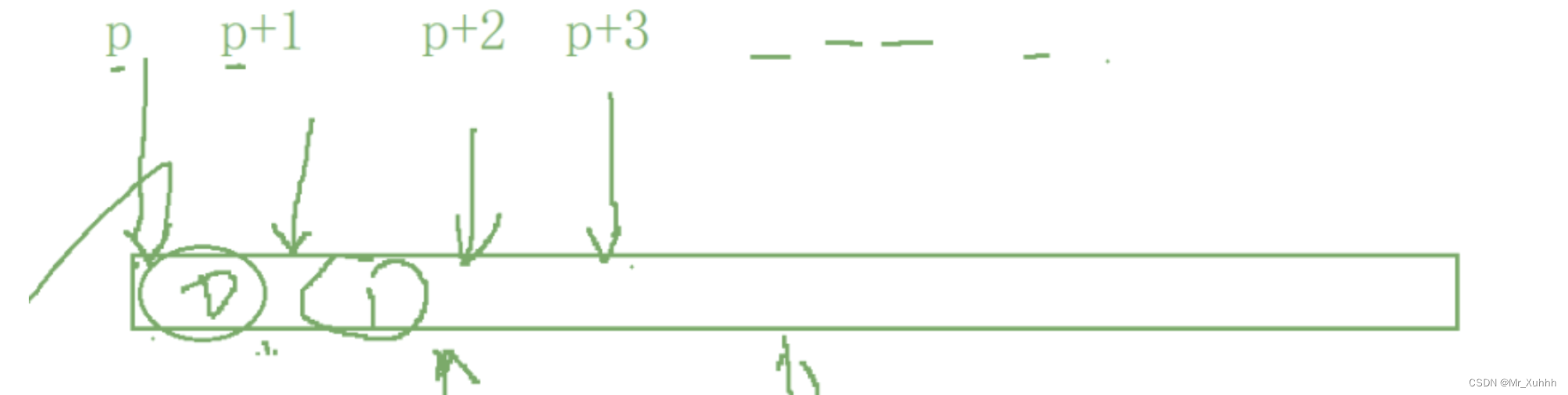
5.对同⼀块动态内存多次释放
void test()
{
int *p = (int *)malloc(100);
free(p);
free(p);//重复释放
}
- 1
- 2
- 3
- 4
- 5
- 6
6.动态开辟内存忘记释放(内存泄漏)
void test()
{
int *p = (int *)malloc(100);
if(NULL != p)
{
*p = 20;
}
}
int main()
{
test();
while(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
忘记释放不再使⽤的动态开辟的空间会造成内存泄漏。
切记:动态开辟的空间⼀定要释放,并且正确释放。
题目7:数组串联
给你一个长度为 n 的整数数组 nums 。请你构建一个长度为 2n 的答案数组 ans ,数组下标 从 0 开始计数 ,对于所有 0 <= i < n 的 i ,满足下述所有要求:
ans[i] == nums[i]ans[i + n] == nums[i]
具体而言,ans 由两个 nums 数组 串联 形成。
返回数组 ans 。
示例 1:
输入:nums = [1,2,1]
输出:[1,2,1,1,2,1]
解释:数组 ans 按下述方式形成:
- ans = [nums[0],nums[1],nums[2],nums[0],nums[1],nums[2]]
- ans = [1,2,1,1,2,1]
- 1
- 2
- 3
- 4
- 5
示例 2:
输入:nums = [1,3,2,1]
输出:[1,3,2,1,1,3,2,1]
解释:数组 ans 按下述方式形成:
- ans = [nums[0],nums[1],nums[2],nums[3],nums[0],nums[1],nums[2],nums[3]]
- ans = [1,3,2,1,1,3,2,1]
- 1
- 2
- 3
- 4
- 5
提示:
n == nums.length1 <= n <= 10001 <= nums[i] <= 1000
对题目进行分析:
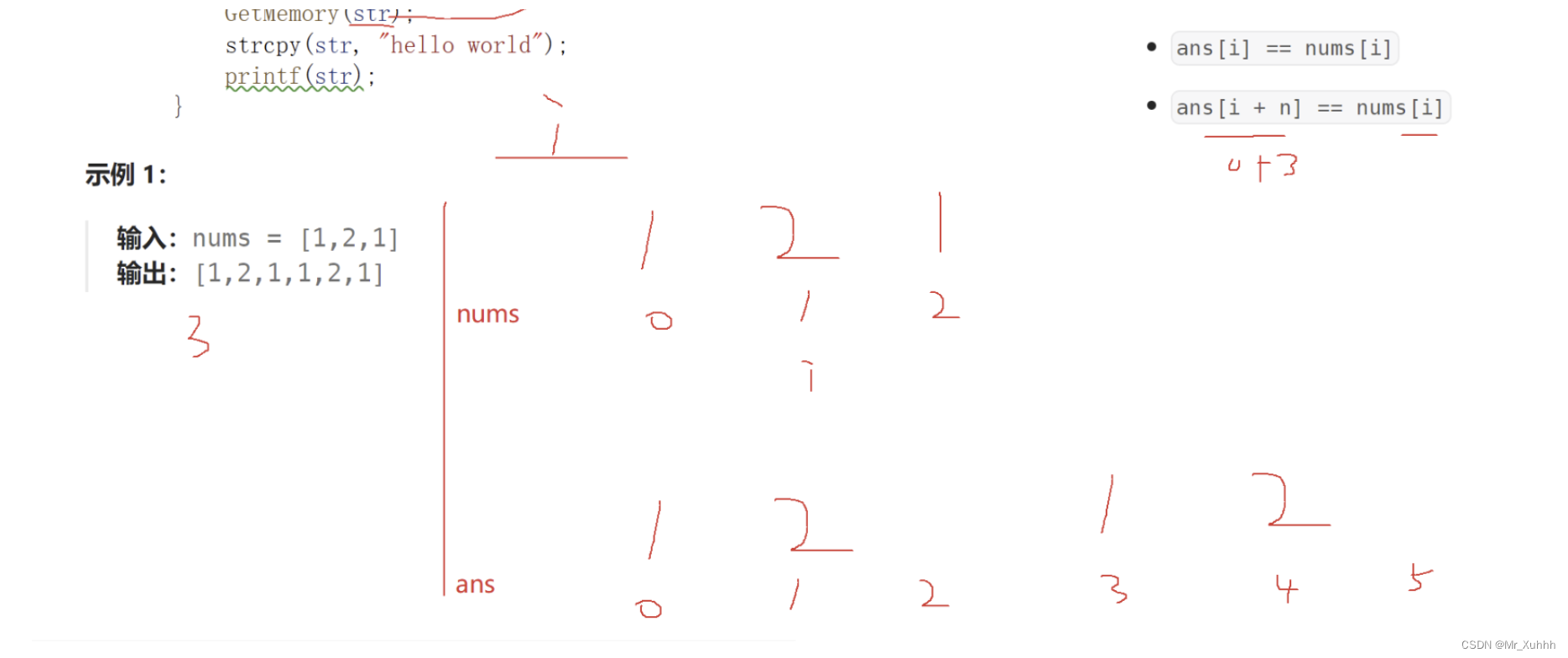
以示例1为例子,就相当于nums要做两次事情,一次是放i到ans中,另一次是放i+n到ans中

上图是以后遇到oj代码编程题会遇到的一些经验包
int getConcatenation(int*nums,int numSize,int*returnSize)
{
int* ans = (int*)malloc(2 * sizeof(int) * numSize);
for (int i = 0; i < numSize; i++)
{
ans[i] = nums[i];
ans[i+numSize] = nums[i];
}
*returnSize = 2 * numSize;
return ans;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
returnSize是一个输出型参数,谁调用getConcatenation就给谁
ans是在getConcatenation函数内部申请的空间,返回给调用者,谁调用就返回给谁,由谁去释放内存(这个点题目在Note中有解释)
题目8:用malloc函数创建一个二维数组
使用malloc函数模拟开辟一个3*5的整型二维数组,开辟好后,使用二维数组的下标访问形式,访问空间。
分析:
二维数组是特殊的一维数组,也就是说二维数组的每个元素存放的是每个一维数组的地址,也可以存数组首元素的地址,首元素的地址存放的整型地址。
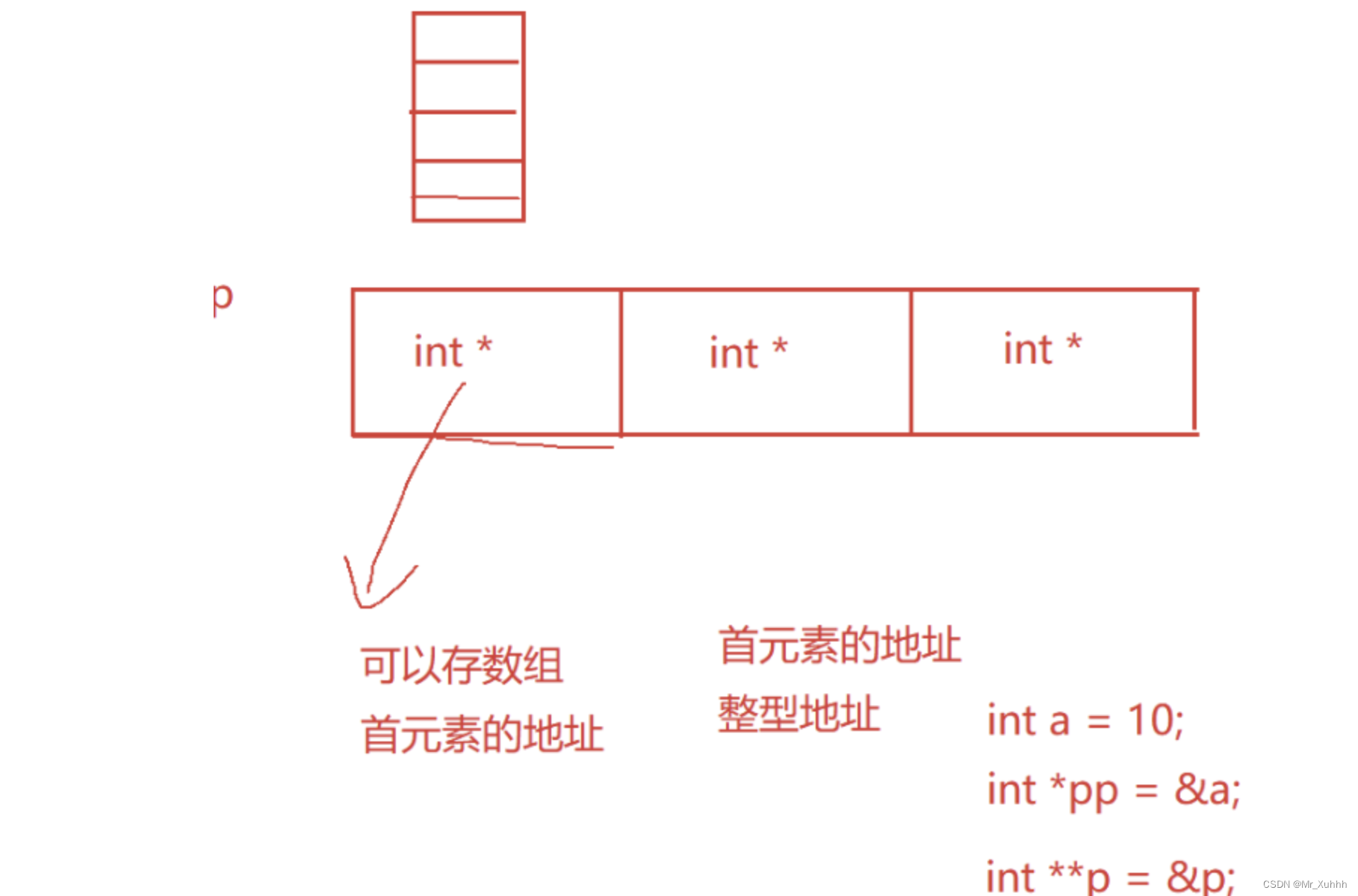
接下来再做一个分析:
看下面这行代码:
int *p=(int*)malloc(10*sizeof(int))//这个就相当于是开辟了一个一维数组的空间
- 1
再看下面这行代码:
int**p=(int**)malloc(3*sizeof(int*))//这个就是我们从上面这幅图中看到的开辟二维数组的方式
- 1
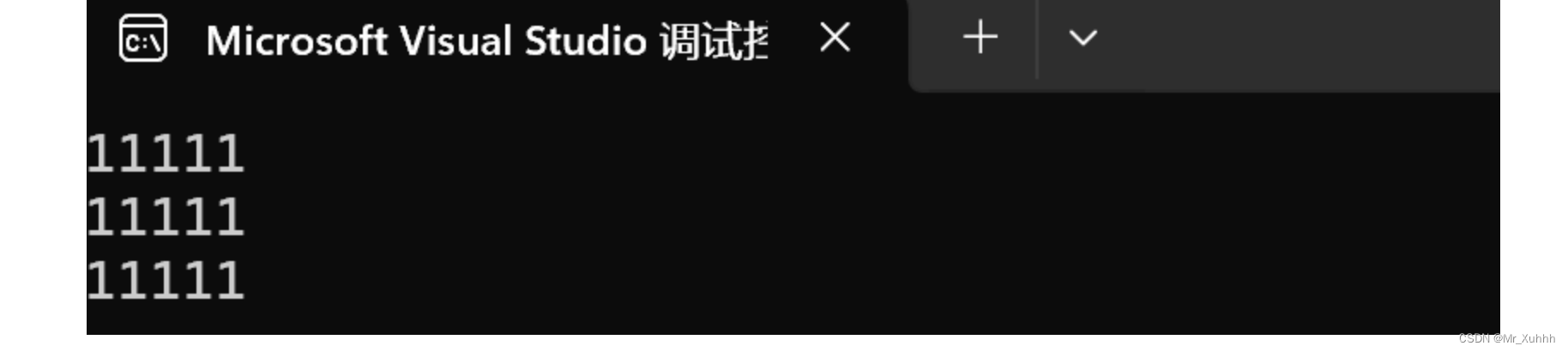
最后呈现的结果如下:
int main() { //1.开辟空间(核心部分) int **p=(int**)malloc(3*sizeof(int*)); for(int i=0;i<3;i++) { p[i]=(int*)malloc(5*sizeof(int)); } //2.初始化 for(int i=0;i<3;i++) { for(int j=0;j<5;j++) { p[i][j]=1; } } //3.打印数组 for(int i=0;i<3;i++) { for(int j=0;j<5;j++) { printf("%d",p[i][j]); } printf("\n"); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
打印结果:
题目9:练习使用动态内存相关的函数
练习使用动态内存相关的4个函数,并调试观察。
malloc、calloc、realloc、free
二进制文件和文本文件
题目1:文本文件和二进制文件的区别
关于文本文件和二进制文件描述错误的是?
A.文本文件是可以读懂的,二进制文件没办法直接读懂
B.数据在内存中以二进制的形式存储,如果不加转换的输出到外存,就是二进制文件
C.将内存中的数据转化成ASCII码值的形式,并以ASCII码值的形式存储的文件就是文本文件。
D.文本文件和二进制文件没啥区别,机器都能识别
解析:
文本文件和二进制文件机器确实都能识别,但是存储的形式还是有所差异的。答案为D
题目2:打开文件
C语言以二进制方式打开一个文件的方法是?( )
A.FILE *f = fwrite( “test.bin”, “b” );
B.FILE *f = fopenb( “test.bin”, “w” );
C.FILE *f = fopen( “test.bin”, “wb” );
D.FILE *f = fwriteb( “test.bin” );
解析:
首先,因为要打开文件,AD直接拖出去,由于不存在一个“fopenb”函数,所以直接选C。二进制描述中的b要放在权限后,也就是“wb”才是合法的。
题目3:fopen函数
关于fopen函数说法不正确的是:( )
A.fopen打开文件的方式是"r",如果文件不存在,则打开文件失败
B.fopen打开文件的方式是"w",如果文件不存在,则创建该文件,打开成功
C.fopen函数的返回值无需判断
D.fopen打开的文件需要fclose来关闭
解析:
C选项中fopen的返回值可以检验文件是否打开成功,打开方式为"r"时尤其重要。ABD为文件操作的基本概念和原则
题目4:文件名及路径
下列关于文件名及路径的说法中错误的是:( )
A.文件名中有一些禁止使用的字符
B.文件名中一定包含后缀名
C.文件的后缀名决定了一个文件的默认打开方式
D.文件路径指的是从盘符到该文件所经历的路径中各符号名的集合
解析:
B选项中,文件名可以不包含后缀名。A的话,文件名中不能包含这些字符:/

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

