
- 1ubuntu16.04.7安装jdk_tomcat_mysql_ubuntu16.04.7支持mysql最高版本
- 2APKDeepLens:Android应用安全扫描利器
- 3linux apt与yum什么区别,linux中apt-get和yum和wget的区别
- 4Python爬虫框架有哪些?_cola框架
- 5Golang String字符串类型转Json格式_go string转json
- 6【向量检索】之向量数据库Milvus,Faiss详解及应用案例_向量搜索
- 7DataWhale AI夏令营3-Task 1
- 8解决docker与firewalld冲突问题_firewalld与docker冲突
- 9进阶数据库系列(二十六):PostgreSQL 数据库监控管理_postgresql监控数据库性能指标
- 10使用keras-bert实现序列标注任务_序列标注bert
深度学习环境配置:(windows环境)WSL2-Ubuntu+(mac环境)_windows wsl ubuntu
赞
踩
Windows
1.在Windows的WSL2上安装Ubuntu
流程可参考:https://www.bilibili.com/video/BV1mX4y177dJ
注意:中间可能需要使用命令wsl --update更新一下wsl。
2.WSL数据迁移
按照下面流程:开始菜单->设置->应用->安装的应用->搜索“ubuntu”->点选3个点->移动->移动到"非C盘的其他盘"
3.为WSL适配图形化界面
参考:https://www.bilibili.com/video/BV1mX4y177dJ
启动图形化界面的命令是sudo startxfce4
4.安装cuda
参考:https://zhuanlan.zhihu.com/p/683058297
nvidia-smi命令的解释参考:https://blog.csdn.net/daydayup858/article/details/131633445
注意:一定要先查看nvidia-smi命令中的显示的支持的cuda的最高版本,然后再去下载对应版本的cuda。
如果装错了cuda版本,可以参考这篇文章卸载已安装的cuda:https://blog.csdn.net/ziqibit/article/details/129935737
如果显示nvcc not found,请参考:https://blog.csdn.net/Maggie_JK/article/details/132666245
5.安装cuDNN
参考:https://zhuanlan.zhihu.com/p/683058297
卸载cuDNN的方式是和卸载cuda类似的。
完成安装后可以使用参考链接的内容进行验证,cuDNN是否正确安装。
7.安装miniconda
参考:https://zhuanlan.zhihu.com/p/683058297
安装完conda之后,创建新的环境,并切换到新环境
8.安装pytorch
参考:https://zhuanlan.zhihu.com/p/683058297
9.安装vscode
去vscode官网安装vscode
vscode上安装wsl扩展包
之后参考https://zhuanlan.zhihu.com/p/683058297
https://learn.microsoft.com/zh-cn/windows/wsl/tutorials/wsl-vscode
9.代码测试
参考:https://www.bilibili.com/video/BV1B14y1W7z3
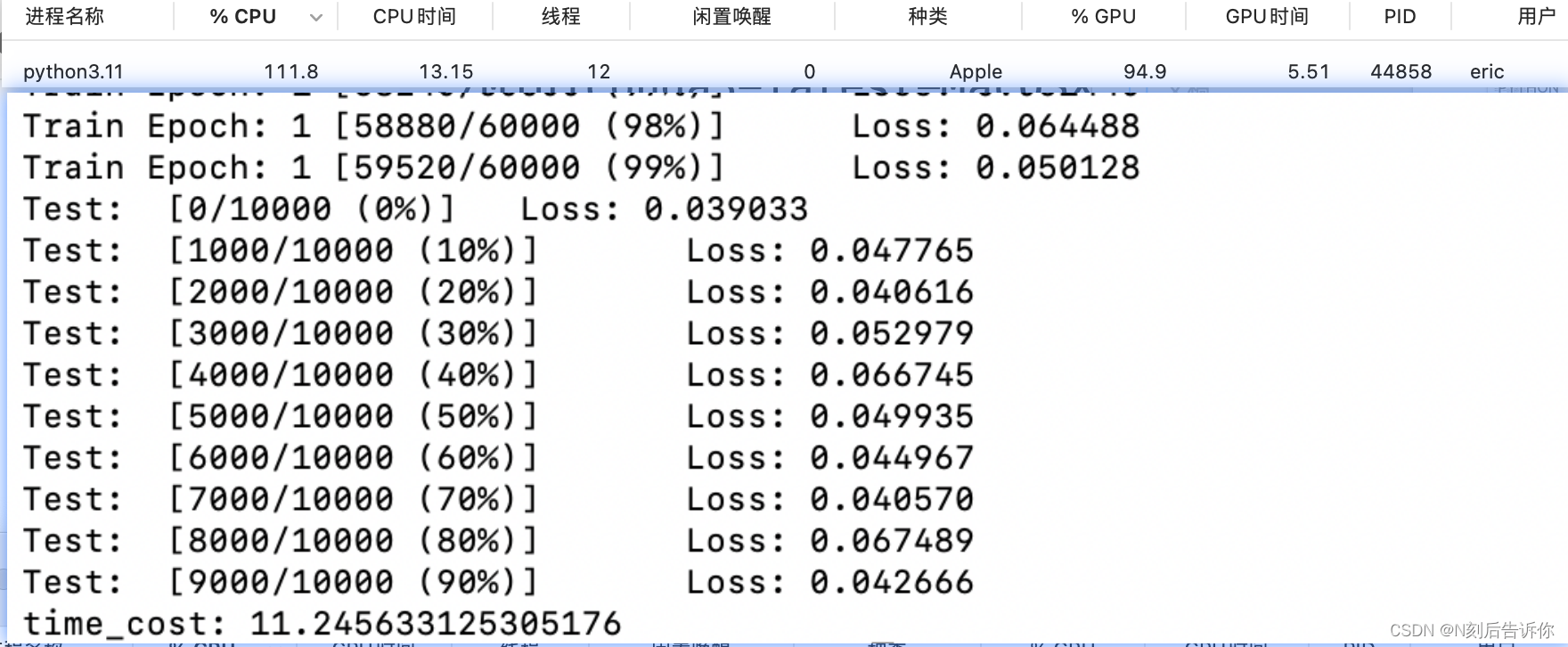
我的测试结果:

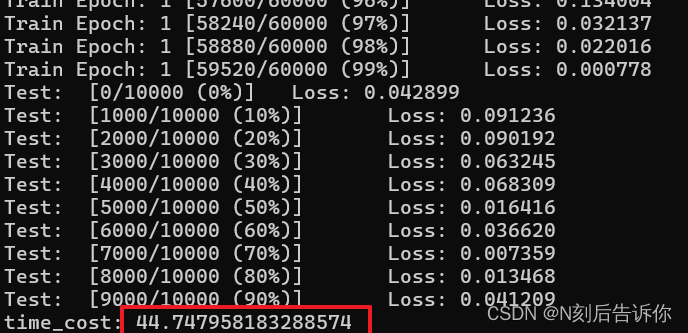
在Mac上只使用CPU
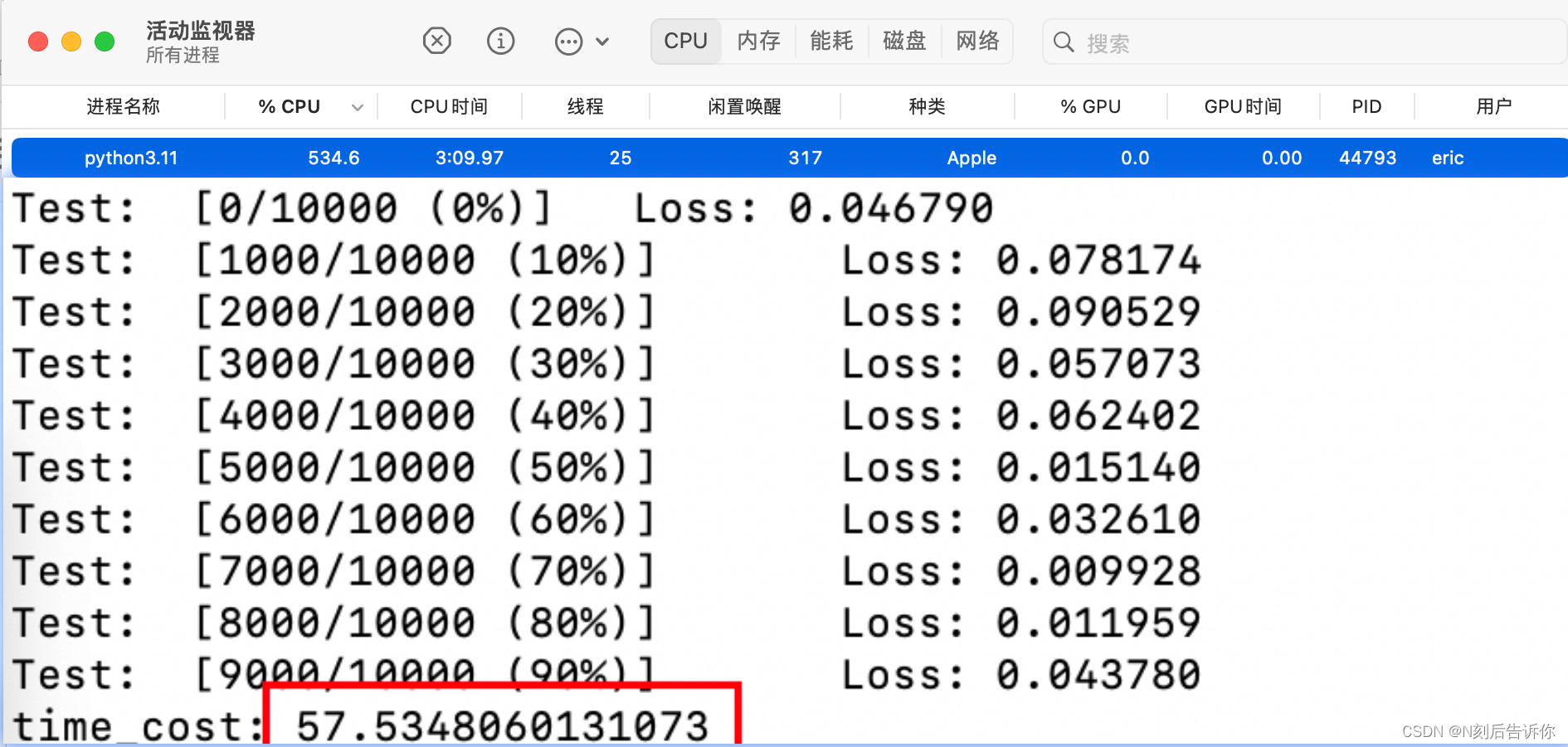
在Mac上使用GPU
10.其他
如何优雅的使用WSL:https://www.bilibili.com/video/BV1Ku4y1f7nq
Mac
Mac上安装anaconda3,pytorch,vscode
参考资料:https://www.bilibili.com/video/BV1gk4y1M76B
Mac上配置vscode和pycharm
参考视频:https://www.bilibili.com/video/BV1j14y1o7k7

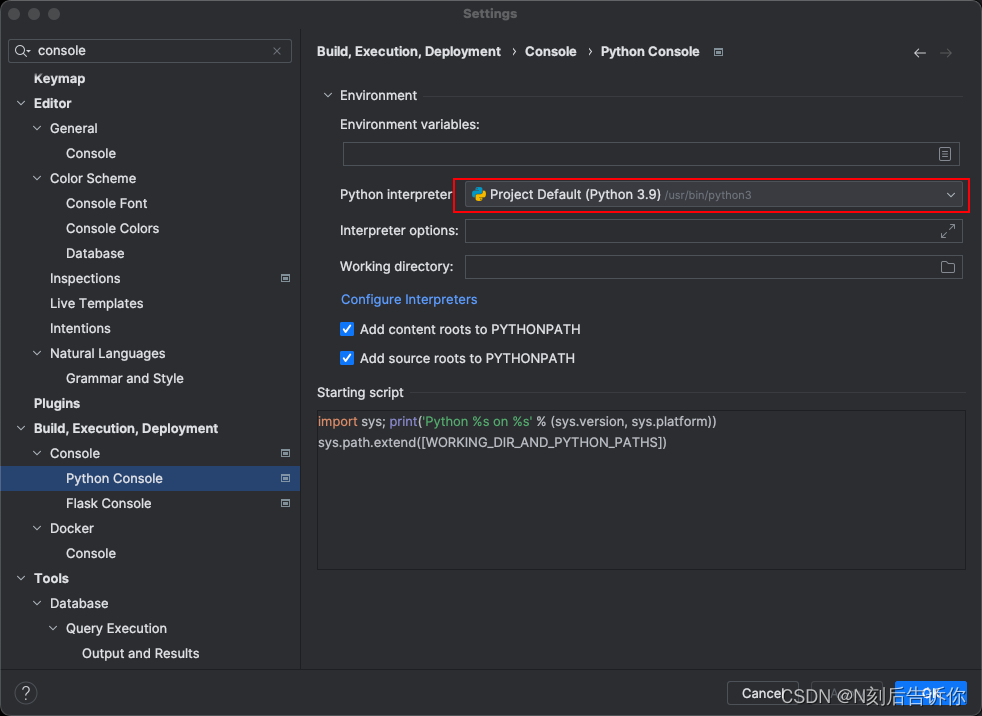
如何修改
python console对应的python默认环境。
一般默认环境是/usr/bin/python3
要修改默认环境,就需要修改这个project的环境
可以通过setting进入修改
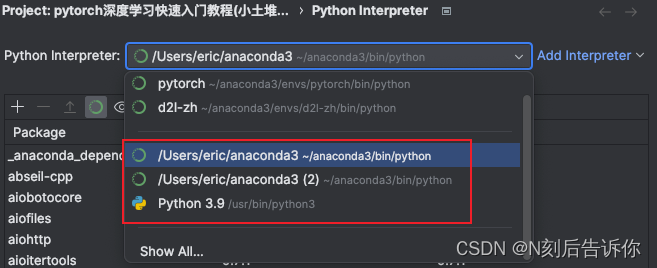
如何继续修改pycharm中的python console的默认环境。
参考:PyCharm中如何设置切换Python Console终端的Python版本
“本地跑神经网络实验”以及“远程连接服务器”
参考资料:https://www.bilibili.com/video/BV1t14y1o7vb
本地跑神经网络实验
from __future__ import print_function import argparse import time import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from torch.optim.lr_scheduler import StepLR class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output def train(args, model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: break def test(model, device, test_loader): model.eval() for batch_idx, (data, target) in enumerate(test_loader): data, target = data.to(device), target.to(device) output = model(data) loss = F.nll_loss(output, target) print('Test: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( batch_idx * len(data), len(test_loader.dataset), 0.1 * batch_idx * len(data) / len(test_loader), loss.item())) def main(): # Training settings parser = argparse.ArgumentParser(description='PyTorch MNIST Example') parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)') parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N', help='input batch size for testing (default: 1000)') parser.add_argument('--epochs', type=int, default=1, metavar='N', help='number of epochs to train (default: 14)') parser.add_argument('--lr', type=float, default=1.0, metavar='LR', help='learning rate (default: 1.0)') parser.add_argument('--gamma', type=float, default=0.7, metavar='M', help='Learning rate step gamma (default: 0.7)') parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training') parser.add_argument('--use_gpu', action='store_true', default=False, help='enable MPS') parser.add_argument('--dry-run', action='store_true', default=False, help='quickly check a single pass') parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)') parser.add_argument('--log-interval', type=int, default=10, metavar='N', help='how many batches to wait before logging training status') parser.add_argument('--save-model', action='store_true', default=False, help='For Saving the current Model') args = parser.parse_args() use_gpu = args.use_gpu torch.manual_seed(args.seed) device = torch.device("mps" if args.use_gpu else "cpu") train_kwargs = {'batch_size': args.batch_size} test_kwargs = {'batch_size': args.test_batch_size} if use_gpu: cuda_kwargs = {'num_workers': 1, 'pin_memory': True, 'shuffle': True} train_kwargs.update(cuda_kwargs) test_kwargs.update(cuda_kwargs) transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) dataset1 = datasets.MNIST('./data', train=True, download=True, transform=transform) dataset2 = datasets.MNIST('./data', train=False, transform=transform) train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs) model = Net().to(device) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma) for epoch in range(1, args.epochs + 1): train(args, model, device, train_loader, optimizer, epoch) test(model, device, test_loader) scheduler.step() if __name__ == '__main__': t0 = time.time() main() t1 = time.time() print('time_cost:', t1 - t0)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
远程连接服务器
下载royal tsx
类似windows上的xshell和fstp
官网:https://royalapps.com/ts/mac/features
- file->new document
- 安装terminal和file transfer插件
- ssh连接
- 优点:可以浏览远程文件路径
- 缺点:无法做到本地与远程的代码同步,无法远程debug
在vscode上远程
- 配置ssh和sftp:详见视频
- 设置远程解释器
- 优点:能做到代码同步,还能远程debug
- 缺点:设置麻烦,无法浏览远程文件
Tmux工具
- Tmux可以防止实验中断
基本命令
# 创建tmux会话
tmux new -s test
# 退出会话
tmux detach
# 进入会话
tmux at -t name # at实际上是attach的简写
- 1
- 2
- 3
- 4
- 5
- 6
一定要进tmux会话里面再运行实验代码

