
- 1程序员找工作过程中担心水平不够该怎么办?我来谈谈解决办法_程序员面试技术不够
- 2单链表面试题---移除链表元素和翻转链表
- 3 推荐项目:ComfyUI-Inpaint-CropAndStitch —— 创新图像修复与融合的终极解决方案
- 4最新宝塔面板部署Django项目教程(踩坑无数板,保姆级教学)_宝塔部署django项目
- 5排序经典算法总结
- 6VRTK4⭐一.VRTK4和VRTK的区别 , 及VRTK4简介_vr tk4是什么
- 7ubuntu+nginx+uwsgi部署django项目
- 8Android Termux安装MySQL,并使用cpolar实现公网安全远程连接[内网穿透]_安卓手机安装mysql
- 9排序算法(三)——选择排序【C/C++】_选择排序c++
- 10java ucs 2,【字符编码系列】JavaScript使用的编码-UCS-2
Web Scraper 网络爬虫零基础详细使用教程,爬取京东商品搜索结果、商品价格、规格参数等,爬取二级网页、滚动加载网页,京东安全验证小技巧_web scraper使用教程
赞
踩
这篇博客介绍了如何使用 Web Scraper 的浏览器插件对京东的商品搜索结果、商品价格、规格参数等进行爬取,介绍了 Web Scraper
插件的基本使用方式,以及京东弹出安全验证的处理小技巧。
- 研究最近需要用到京东的商品数据。刚开始采用了常规的 request 库的方法直接发送请求,然后解析返回结果的方式,但是京东的反爬太狠了,请求几次直接就给嘎了,多次尝试后还是以失败告终。
- 经推荐,我用上了 Web Scraper 这个插件,发现上手简单,傻瓜式操作,而且最重要的是没有被京东很快地拦截掉,能比较顺利地爬到数据,所以写这篇博客记录一下使用方法,以备后续需要并和大家分享。
Web Scraper 安装
Web Scraper 对 MicroSoft Edge 和 Chrome
两款浏览器都提供了插件,直接去插件商店安装就可以了,具体的安装过程也很简单,不会的可以自行百度,这里就不赘述了。
Web Scraper 使用
- 安装好插件之后,按 F12 进入浏览器的开发人员工具,在最右边就可以看到 Web Scraper 选项。

-
点击 Web Scraper 选项,进入页面。刚进入时里面啥也没有,需要自行创建爬虫或者导入别人写好的爬虫。这里的 Sitemap 的意思是对于一个网站(site)需要以怎样的解析方式(map)去获取数据,也就是对目标网站的爬虫结构。
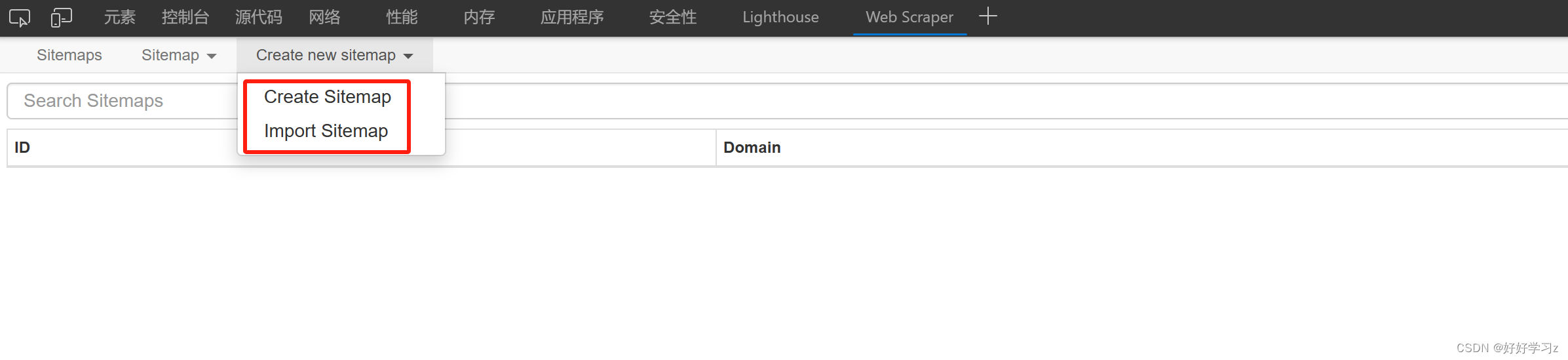
-
点击 Create Sitemap 开始创建第一个爬虫。 Sitemap name 是这个爬虫的名称, Start URL 是要爬取的网页,直接把网址复制粘贴进去即可。另外,可以看到 Start URL 后面有个数字1,点击后面的 + 号可以增加一个URL,也就是说这个爬虫可以应用在多个结构相同的网页上,比如要爬取京东上手机和电脑的搜索结果,可以将手机和电脑的搜索结果的网址逐个粘贴在 Start URL 中,这样就可以避免在爬完手机之后又要回来将网址修改成电脑的URL造成的麻烦。

-
新建一个 Sitemap 后,我们还没有定义任何的爬取行为。点击 Add new selector ,开始定义爬取行为。

-
在 selector 定义界面,id 是你爬取得到的数据字段的名称。接下来的 Type 是要爬取的行为的类型,最常用的是文本类型 Text ,也就是获取文字。
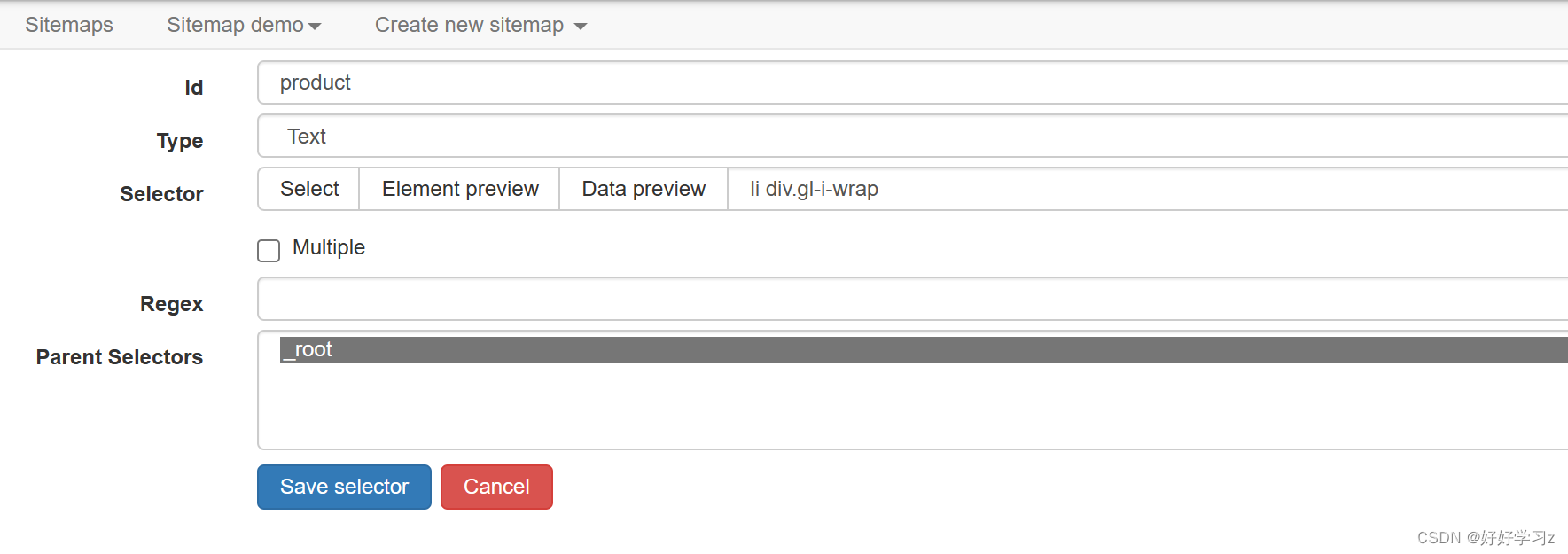
-
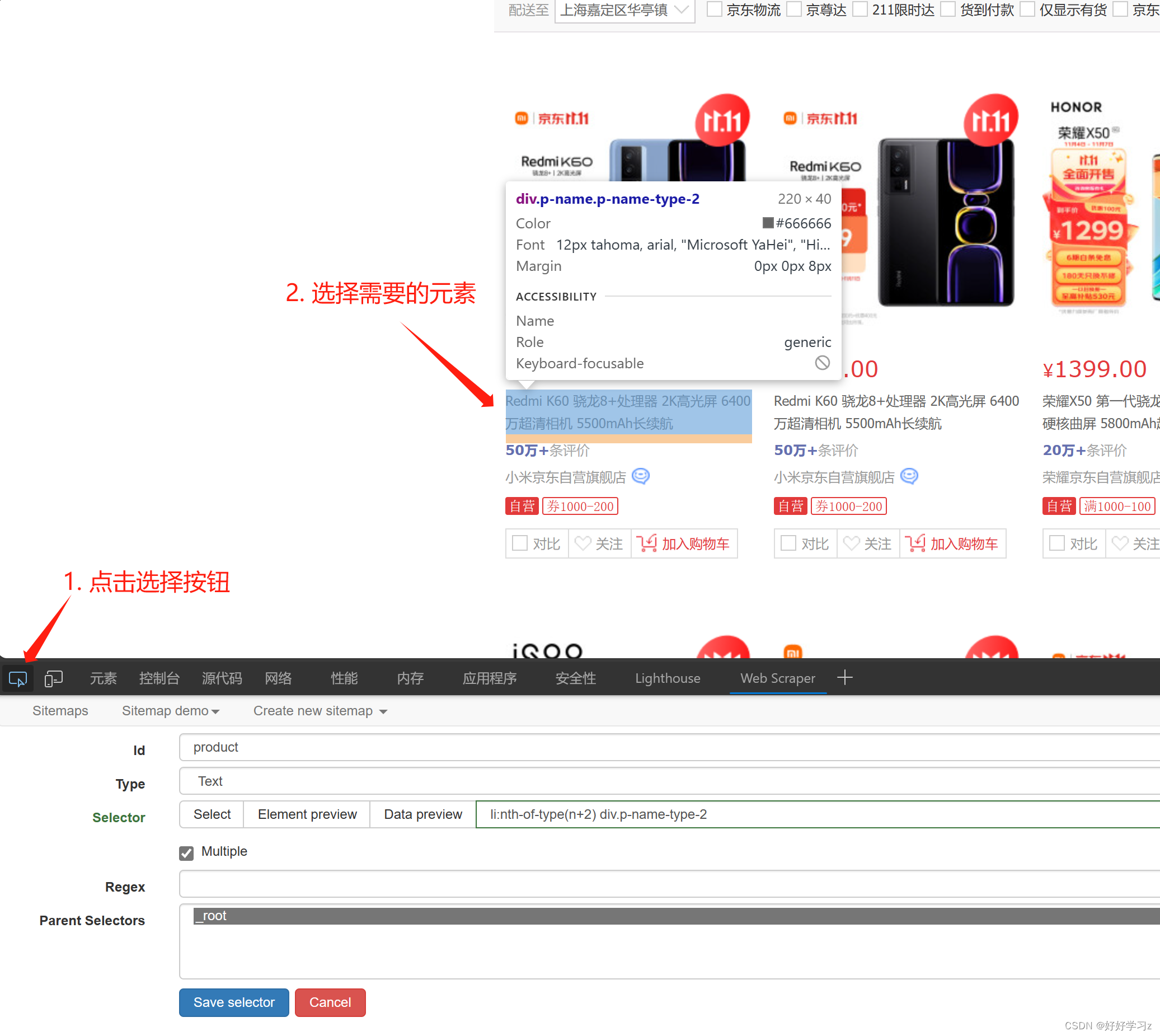
Selector 是选取网页上的元素。点击 Select 后,网页会弹出选择提示框。点击网页中你想要爬取的元素后,网页会用红色框将元素标记。通过点击多个相同的元素, Web Scraper 会调整提取代码以匹配标记结果。如下图,我要爬取手机的名称,所以在点击 Selector 后,我对网页上的手机名称进行点击。点击第二个名称后,就会有多个被代码匹配的名称被标红。此时,可以滑动网页查看是否有漏掉的没被标红的名称,然后将漏网之鱼选上即可。
-
如果对选取结果不满意,或者想换一种元素选取,可以再次点击 Selector,此时标记会被清除,点击后会匹配重新选择的元素。
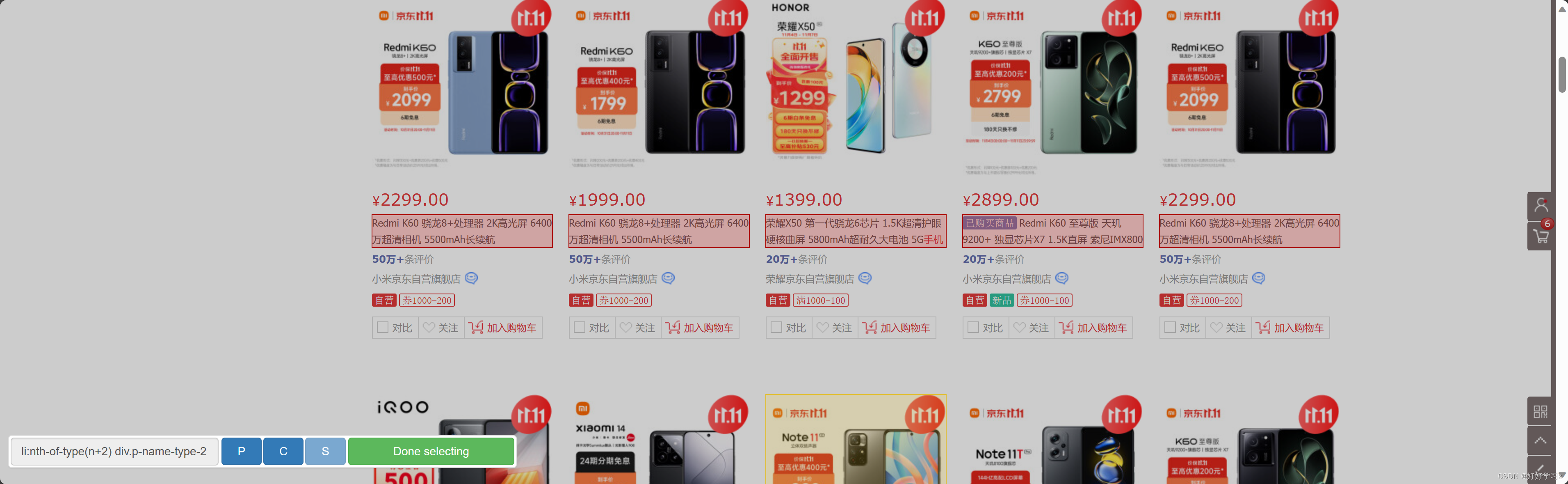
-
点击 Element preview ,你可以查看网页中哪些元素被匹配了,然后决定是否调整选择器的代码。
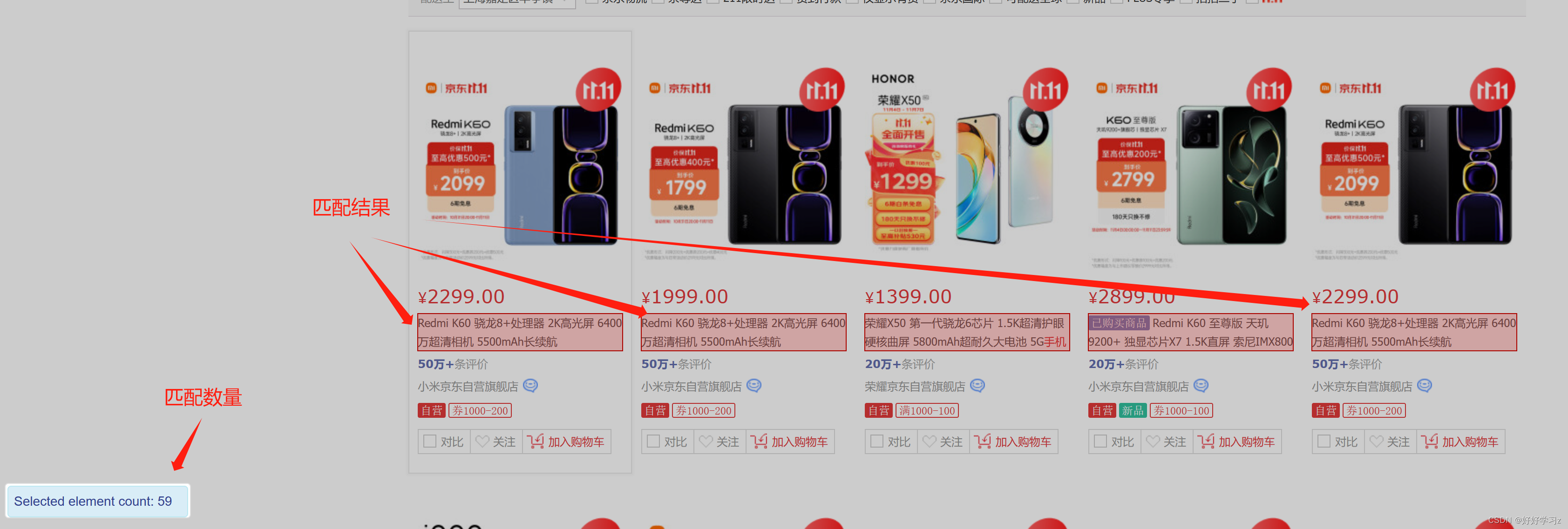
-
点击 Data Preview ,你可以查看提取出来的数据是怎么样的,然后决定是否调整选择器的代码。
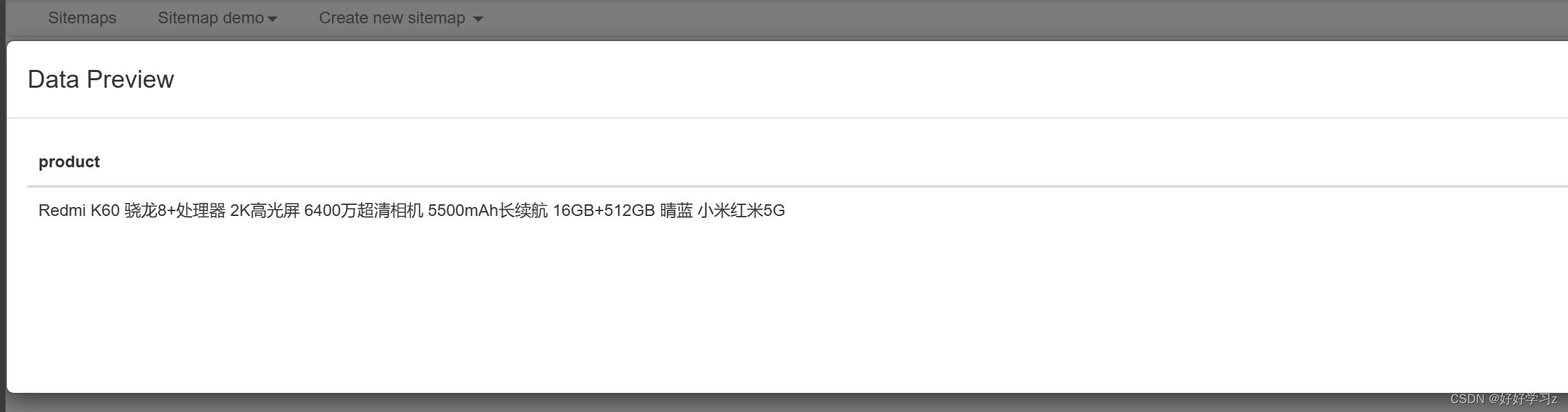
-
可以看到,此时提取出来的数据只有一条,但是我们需要所有的匹配结果。这时,我们只需勾选上 Multiple 选项,就会提取所有匹配数据。
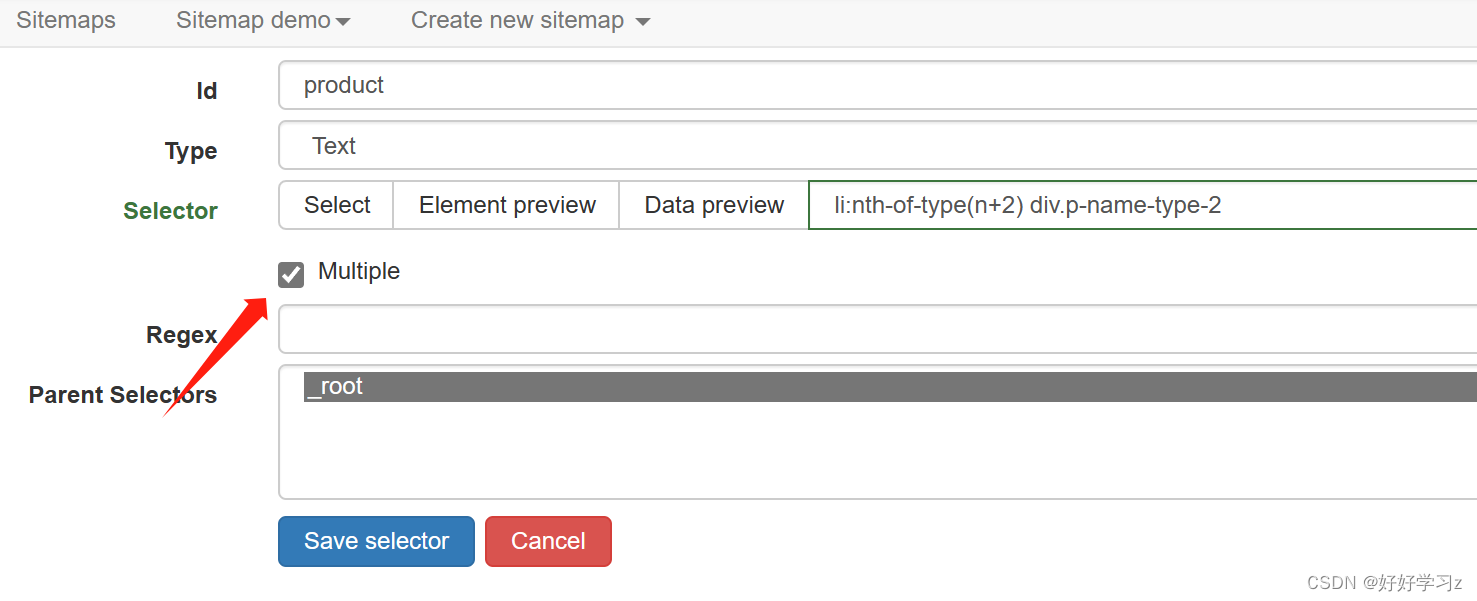

-
Regex 选项是用来匹配正则表达式的,你可以在这里面输入正则表达式来筛选出想要的文本。
-
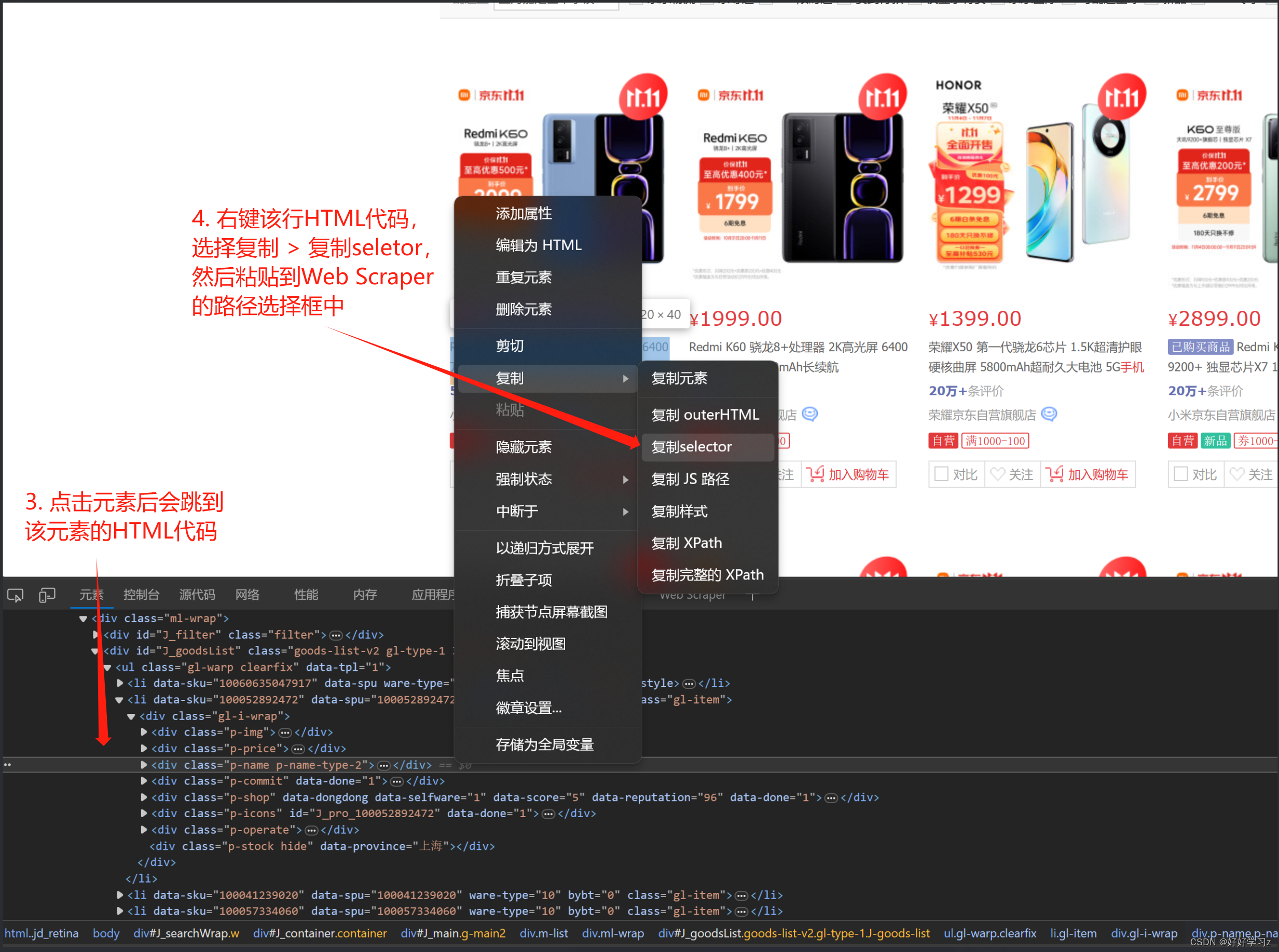
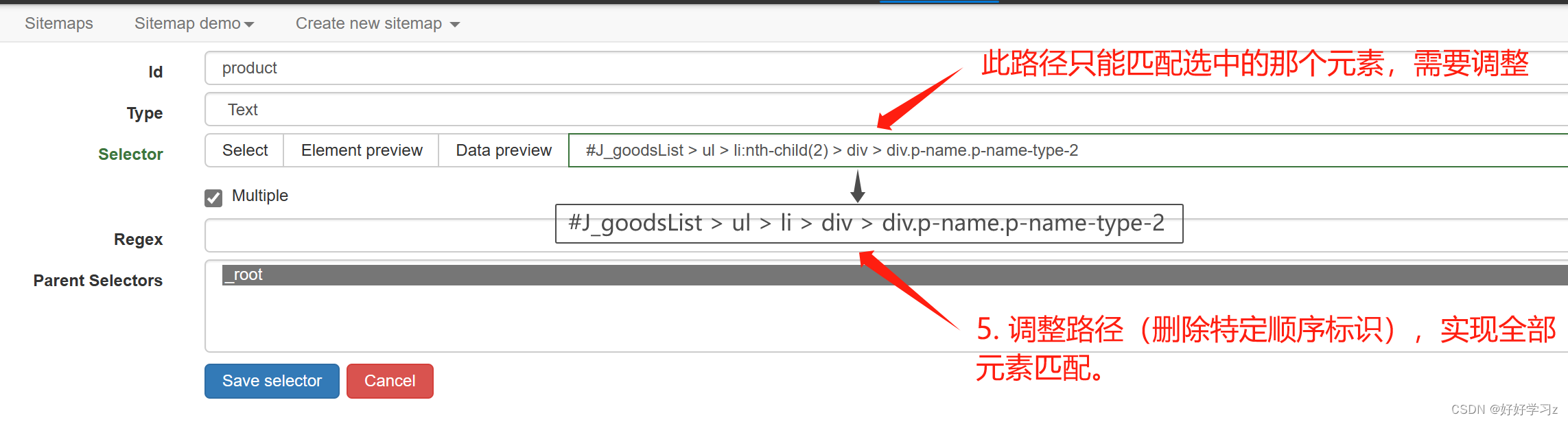
如果你对HTML网页的结构有一些了解的话,可以使用元素选择其去定位网页中的元素的HTML代码,然后复制 selector 路径,粘贴到 Selector 的路径框中。之后,对路径代码进行调整使其匹配所有元素(如删除特定的顺序标识或类名标识)。
-
!!!强烈推荐使用HTML网页代码路径的方式来匹配目标元素,准确率更高,而且能够爬取那些页面上不可见但存在于HTML代码里面的文本(如包含在
-
- 在实际运行爬虫的时候,我们发现,京东的商品页面在搜索后只会加载一半,当将网页往下滑时才会加载另一半,所以在运行爬虫时,我们需要先将网页向下滑动、使网页完全加载,然后再提取商品名称。Web Scraper 提供了 Element scroll down 行为来实现这种目标。
-
新建一个 Selector,选择 Type 为 Element scrill down 。
-
Selector 选择需要加载的元素。这里选择的元素需要是商品名称的父元素,也就是包含商品名称的上一级元素。在使用 Select选择时,可以在点击完商品名称后再点击一下 P ,即可选择父元素。
-
勾选 Multiple,选择所有匹配的元素。
-
Element limit (加载元素的数量上限) 和 Delay (网页加载时间) 根据需要调整。

-
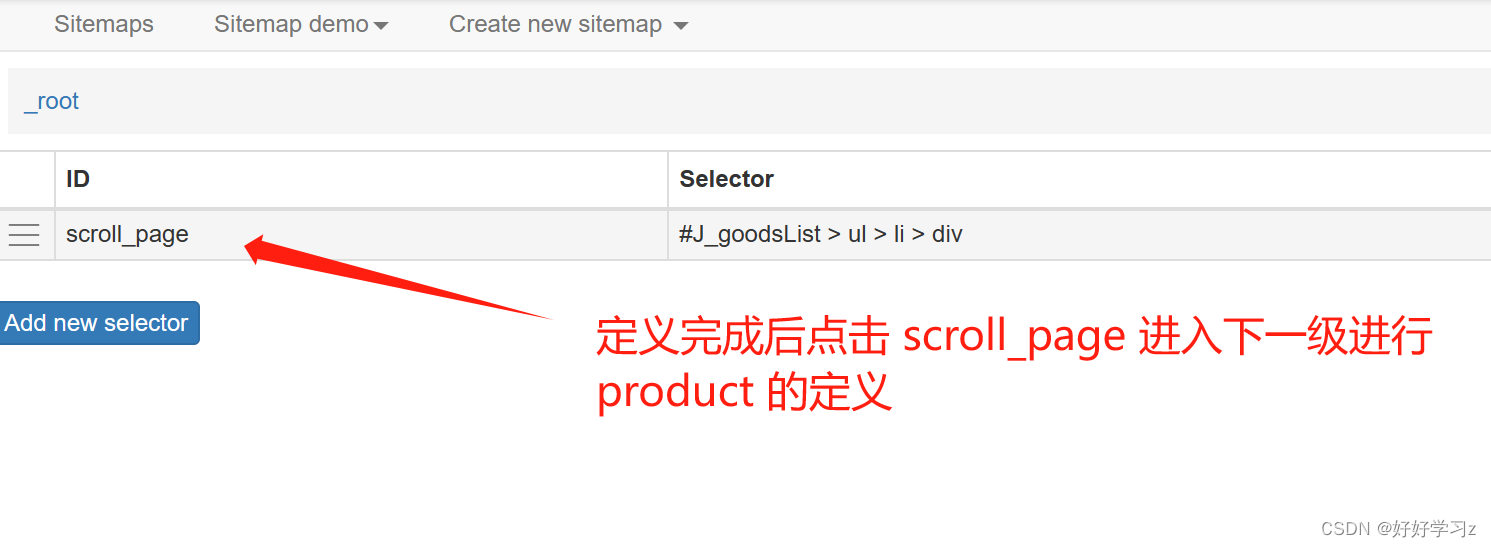
由于我们需要先加载页面再提取名称,所以 scroll_page 需要在 product 前执行,因此 scroll_page 应该作为 product 的父节点,即先定义 scroll_page,然后在其下一级定义 product。
-
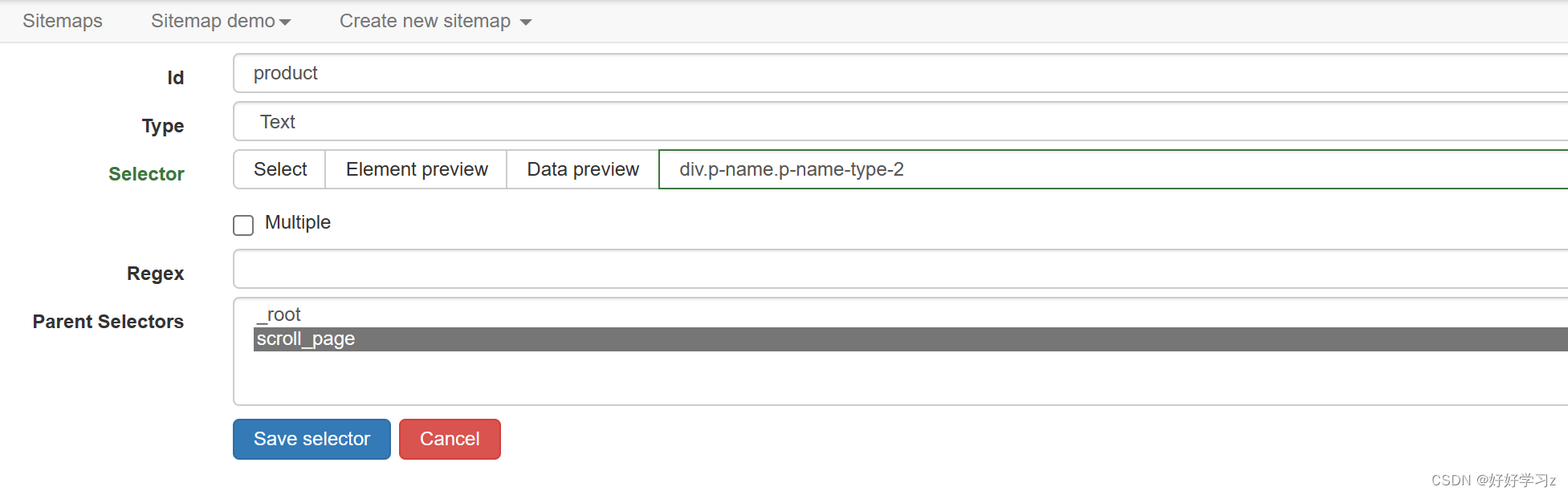
此时,product 的定义与之前有所不同。此时的 product 的行为是针对每一个 scroll_page 爬取得到的元素进行处理,所以在定义时:1)不用勾选 Multiple,因为处理对象由上一级的 scroll_page提供;2)在定义 Selector 时,要以 scroll_page 的元素为参考标准来定义,即定义父节点内部的路径。
-
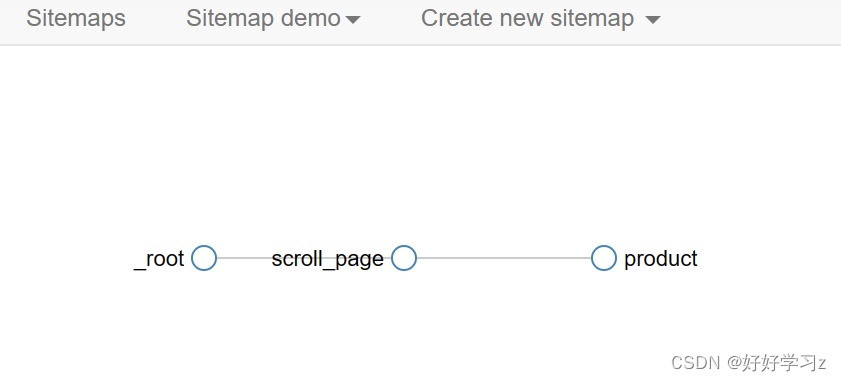
在 Sitemap demo 中选择 Selector graph,可以看到爬虫执行的顺序结构。

-
-
在获取完手机名称后,我们还需要获取手机的售价、规格参数等信息,这些都在手机的详情页中。因此,我们需要点击手机详情页链接,进入新的网页进行爬取 。
-
在 scroll_page 的下一级、product 的同一级新建一个 Selector,命名为 click。
-
选择 Type 为 Link ,这代表去到一个新的网页。
-
在 Selector 中选择获取手机详情页链接的路径。
-
和 product 一样,路径以 scroll_page 为父节点,且不需要勾选 Multiple。
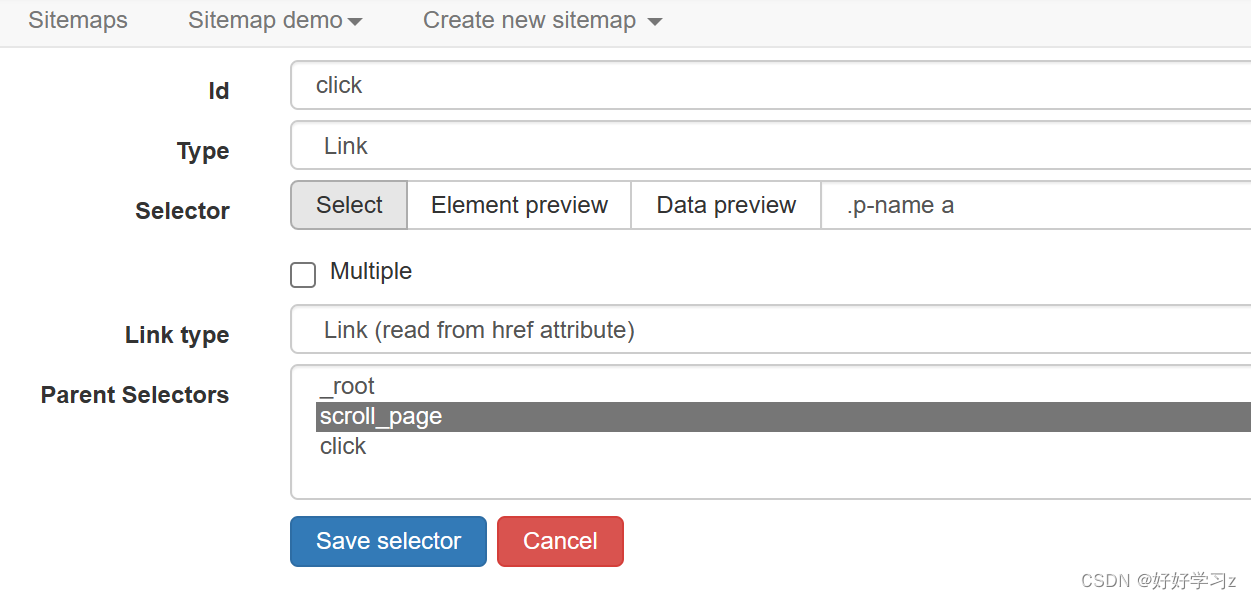
-
点击 Data preview,可以看到成功提取出了每款手机的详情页链接。

-
-
获取完详情页链接后,进入 click 的下一级,在其子级中定义商品售价、规格参数等爬虫,代表之后的爬取行为都在新的网页中进行。在设置 Web Scraper 时,可以直接将详情页链接复制粘贴到当前窗口的地址栏,这样可以在当前窗口进行 click 子级的可视化编辑。
-
爬取手机价格
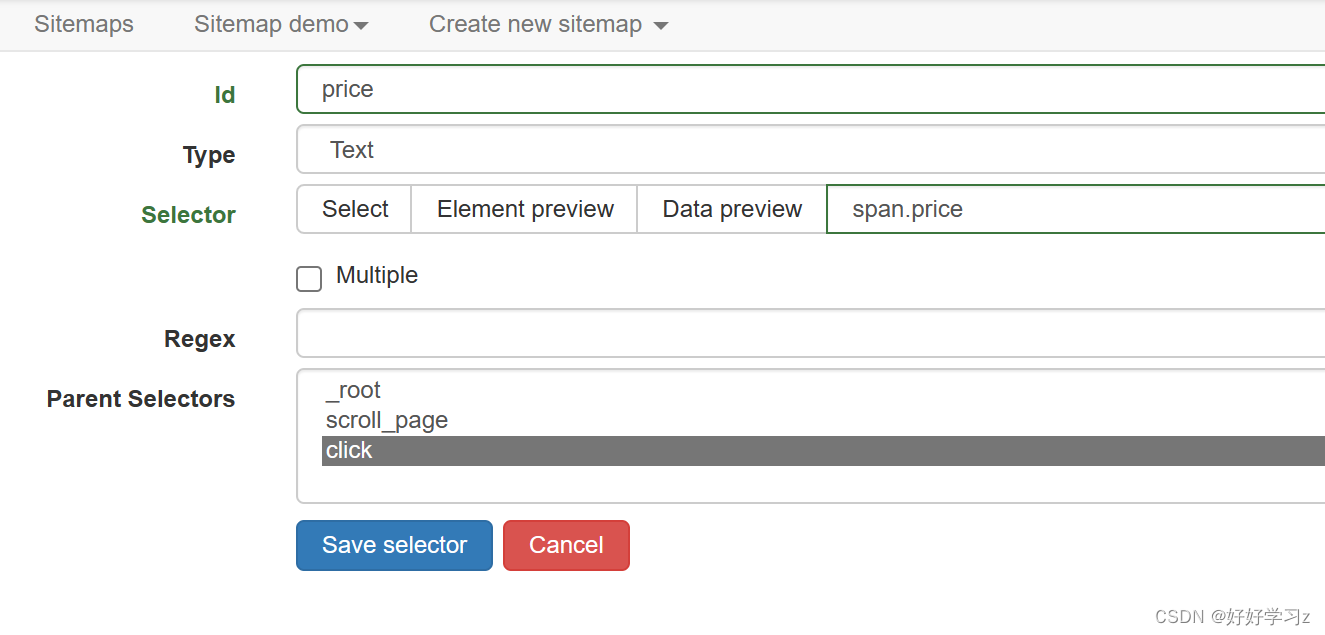
- 新建一个 Selector,命名为 price。
- 爬取价格的设置与之前爬取手机名称的设置类似,这里就不赘述了,直接上图。
-
爬取手机规格参数
- 点击手机规格参数选项,发现参数的呈现形式类似于表格,但是使用 Table 类型的 Type 对参数信息提取时失败了,因为其在HTML中的编写时并非使用表格形式。所以直接提取 Text。
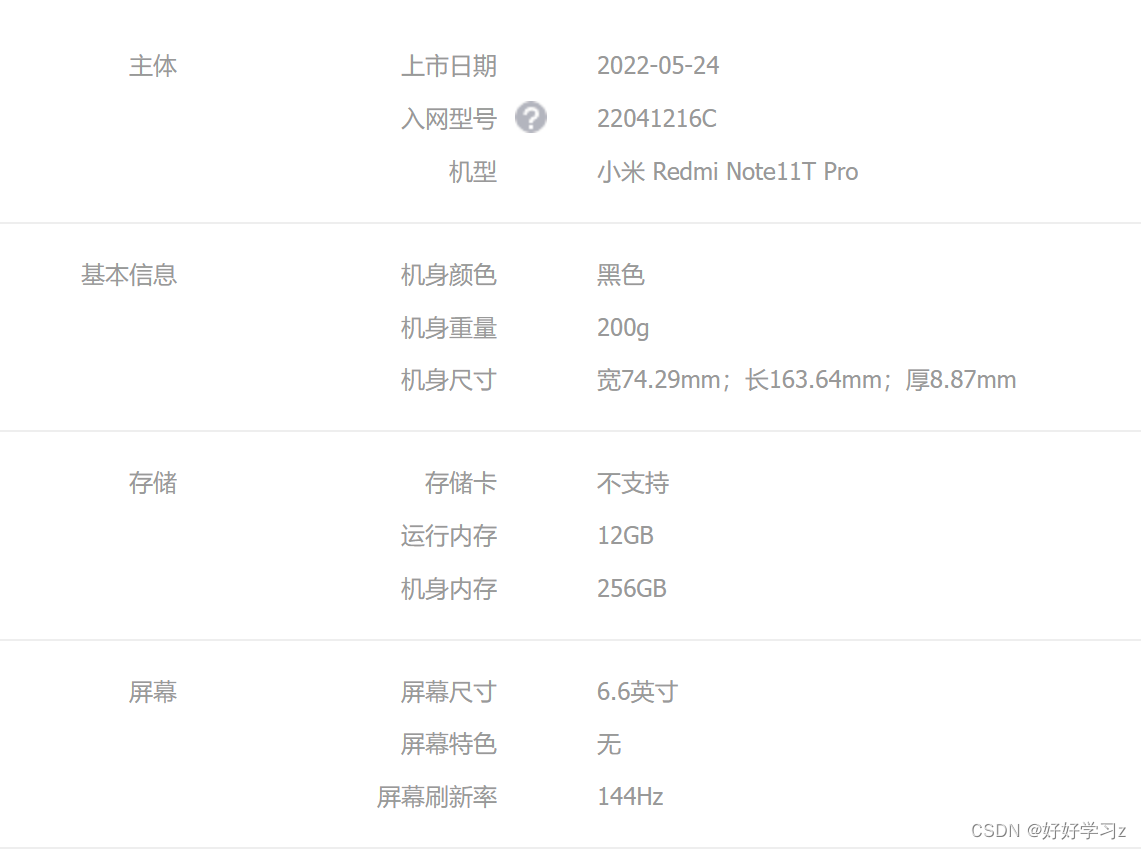
- 点击手机规格参数选项,发现参数的呈现形式类似于表格,但是使用 Table 类型的 Type 对参数信息提取时失败了,因为其在HTML中的编写时并非使用表格形式。所以直接提取 Text。
-
由于参数类别、参数名称、参数值(第1、2、3列)提取逻辑类似,所以只介绍参数类别的设置。
-
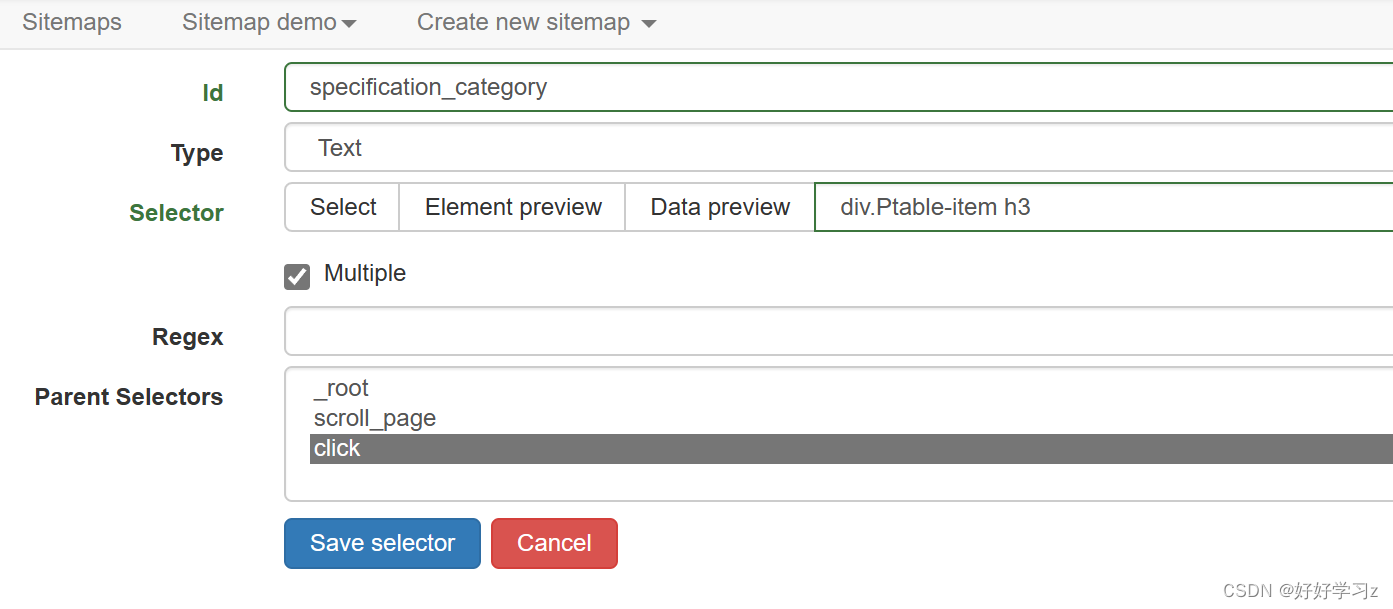
新建一个 Selector,命名为 specification_category。
-
选择 Tpye 为 Text,直接提取文字。
-
勾选 Multiple 。因为这相当于在一个父元素中提取多个元素。
-
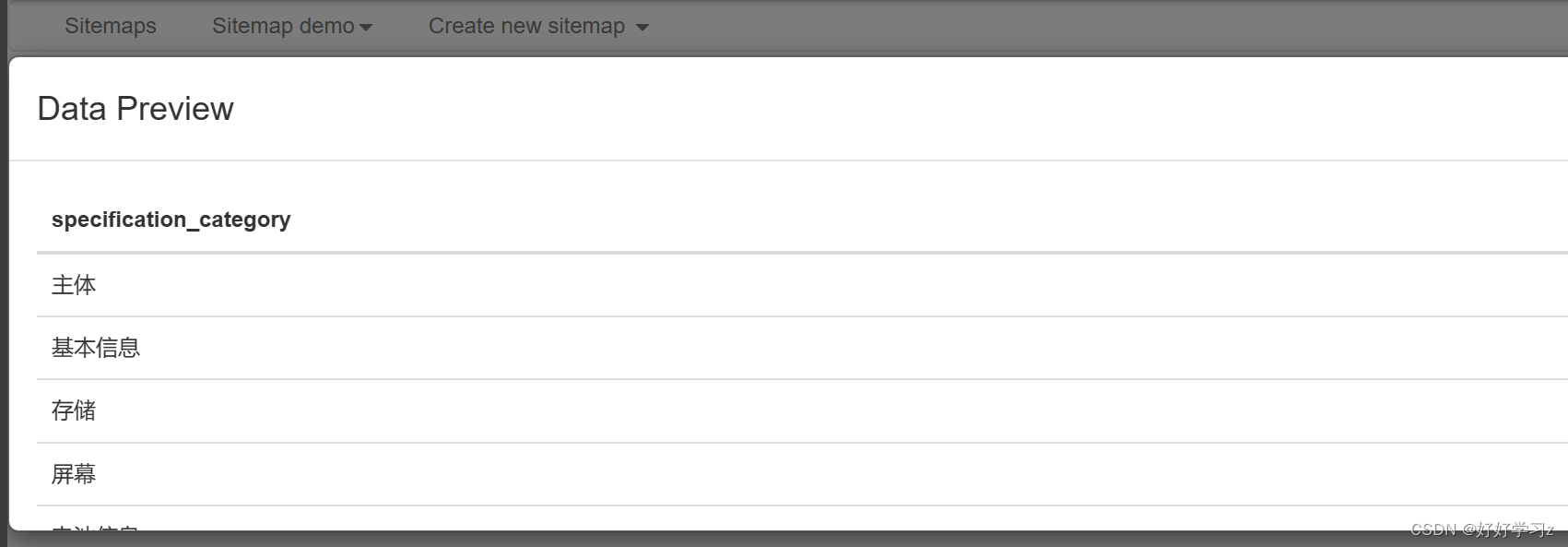
点击 Data preview,发现提取结果将每一个类别都单独作为一条信息记录,而这种记录格式的后果是,在最终的爬取结果中,每一个类别数据都会占据独立的一行,而在之前爬取的信息会重复记录以匹配每一条数据,再加上如果参数名称和参数值都这样处理,便会造成大量的数据冗余。因此,我们希望在记录数据时,每款手机的参数类别作为一条记录存储。
-
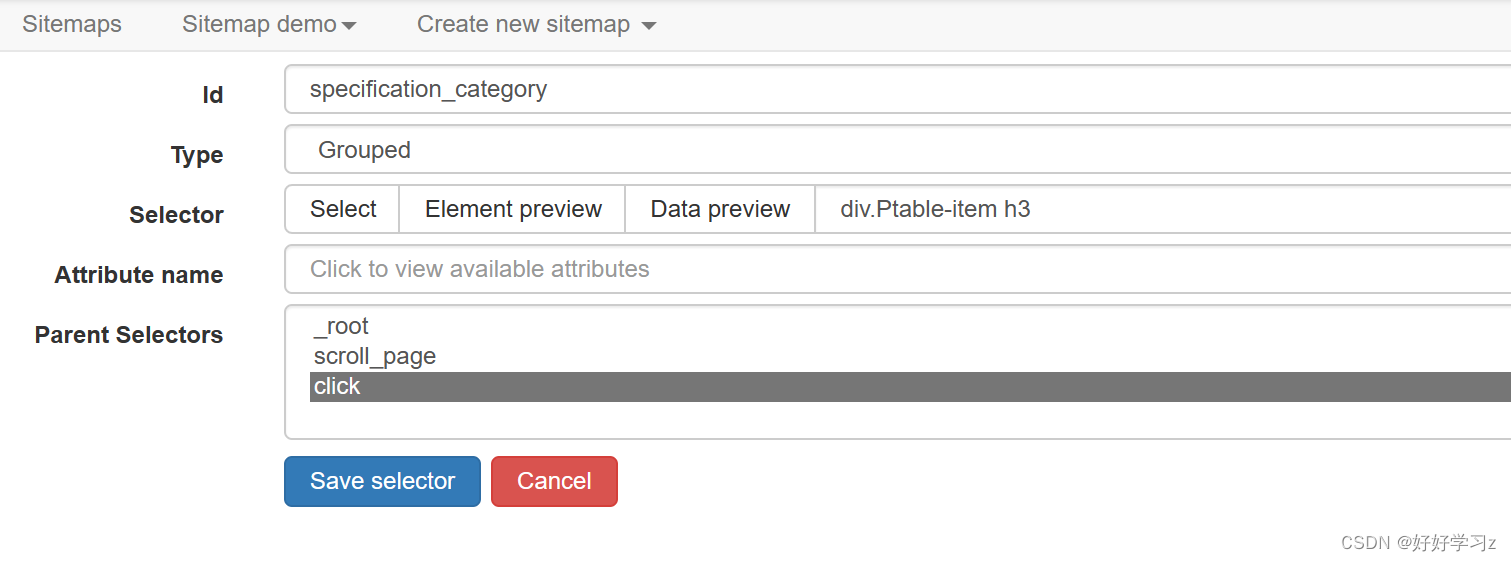
为了改变记录格式,我们重新设置 Selector。选择 Type 为 Grouped,这样会以列表的形式记录下参数类别。
-
点击 Data preview,可以看到所有参数类别都记录为同一条数据。

-
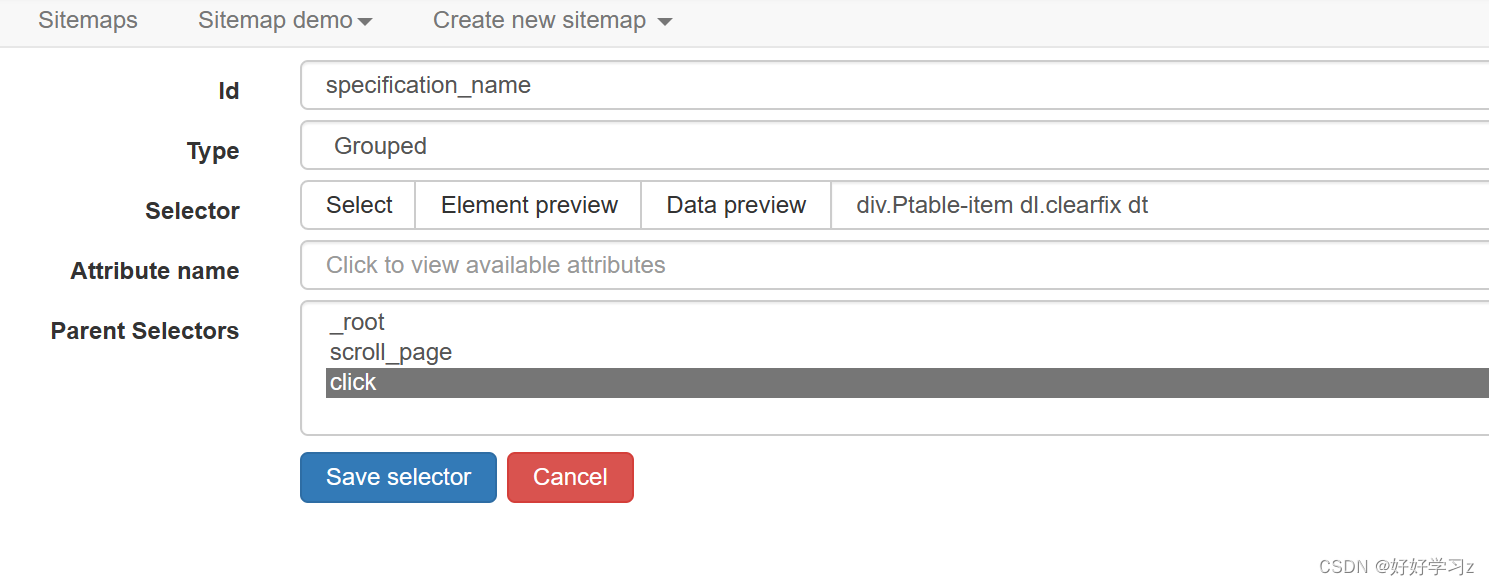
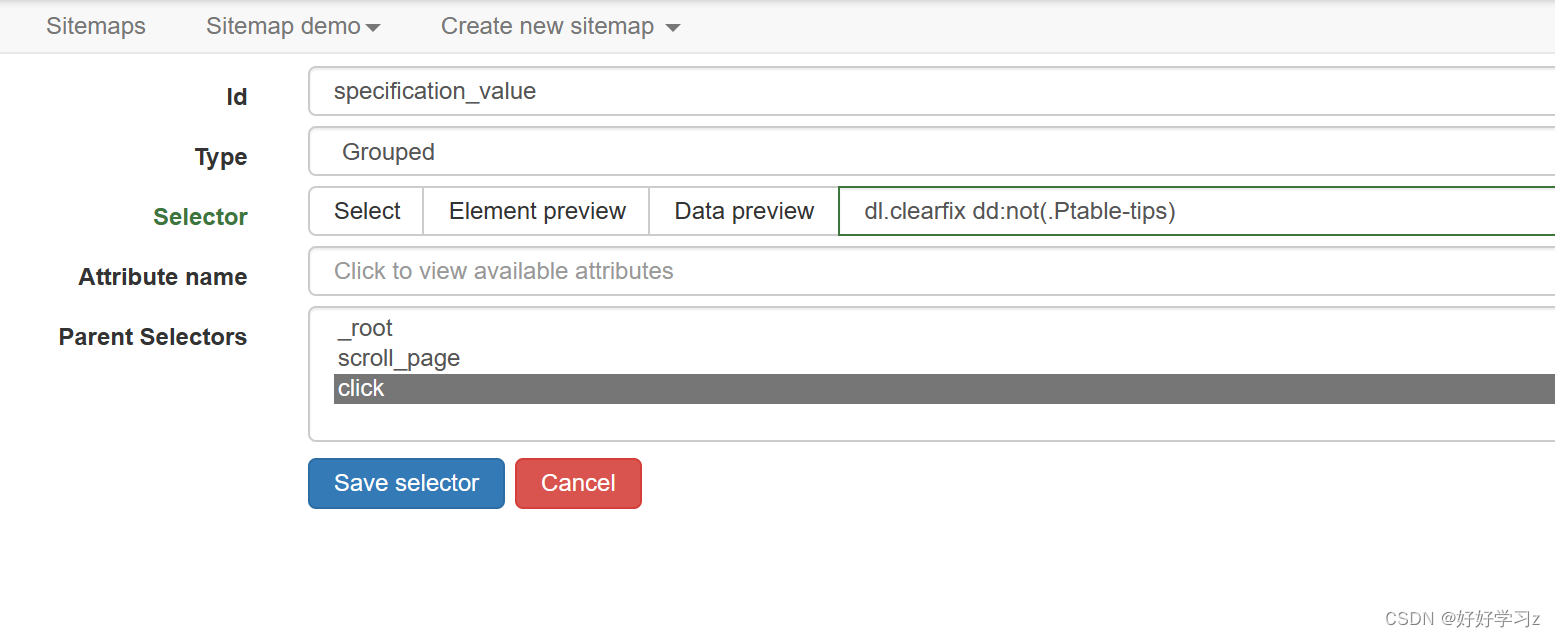
类似地,定义爬取参数名称和参数值的行为。
-
-
至此,所有的爬虫结构均定义完毕,总体结构如下图所示:
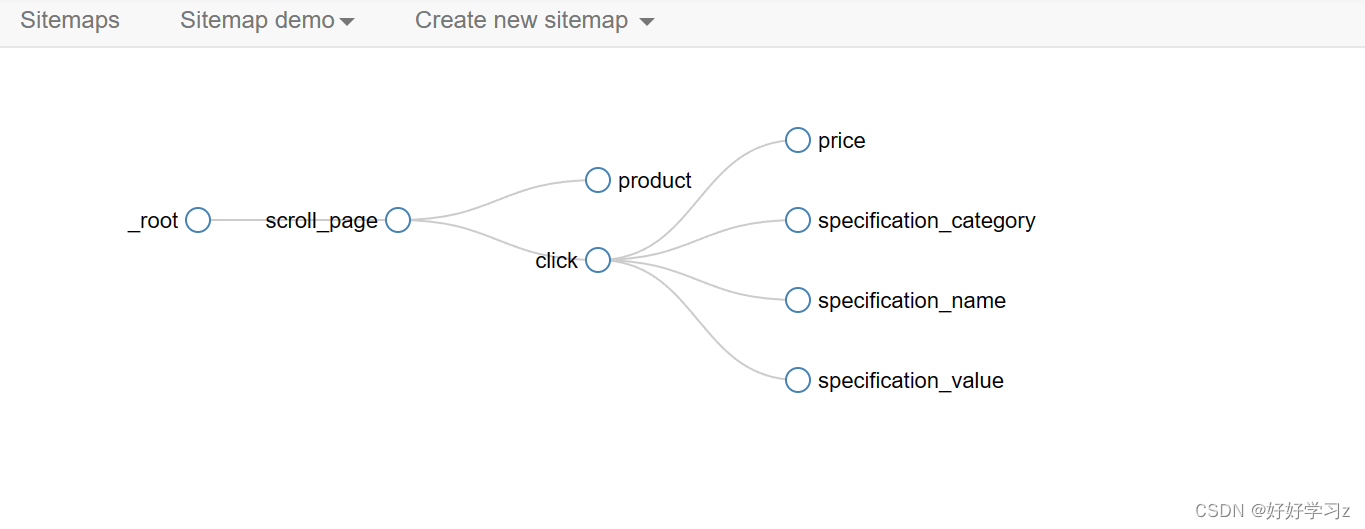
-
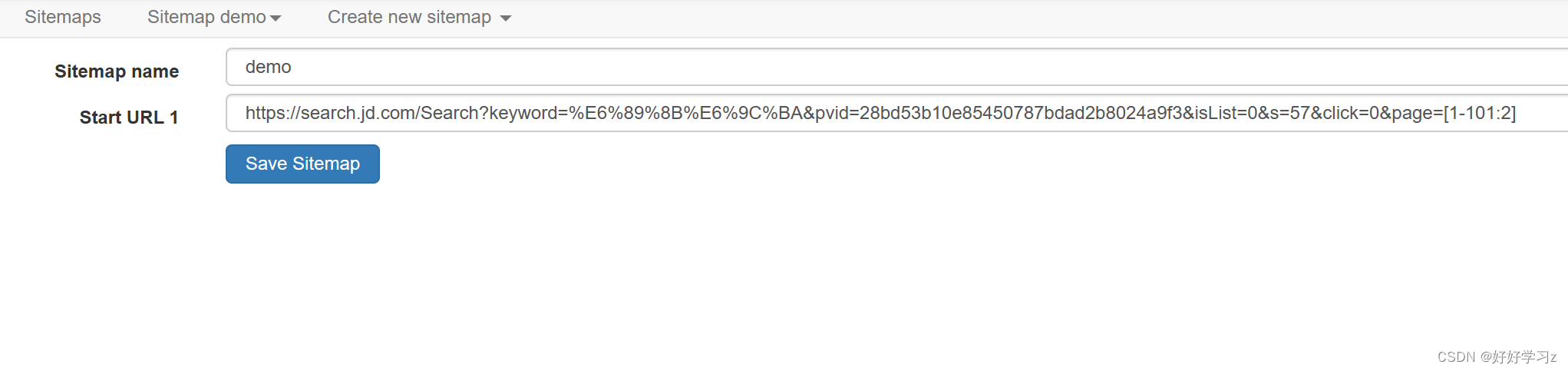
接下来,我们定义需要爬取的所有页面。点击 Sitemap demo > Edit metadata,将要爬取的 URL 改成不同页面的通用格式。京东的商品搜索页面的编号是 2*n+1,我们爬取前50页,所以 page 设置为 [1-101:2] (含义是:[start_num-end_num:step]) 。
-
至此,爬虫设置完毕,可以开始爬数据了!
-
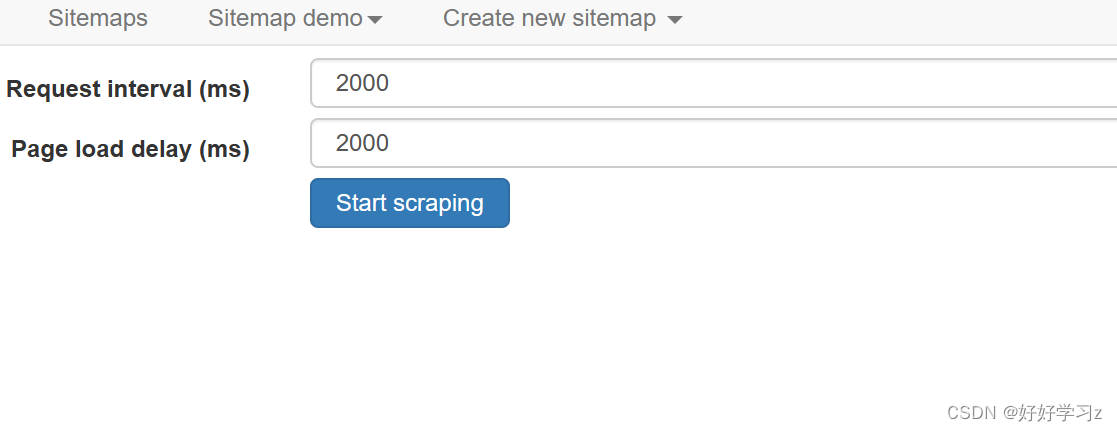
点击 Sitemap demo > Scrape,根据自己的需要调整 Request interval(请求间隔)和 Page load delay (网页加载时间),点击 Start scraping 即可开始爬取数据。
-
开始爬取后,Web Scraper 会新打开一个浏览器窗口。我们只需等待爬虫运行结束即可。
-
注意:爬虫运行时,千万不要将 Web Scraper 打开浏览器窗口最小化或关闭,不然爬虫会停止或者结束。
-
-
爬虫运行期间或者结束后,我们都可以点击 Sitemap demo > Browse 查看已爬取的数据。倘若发现有需要调整的地方,可以及时关闭浏览器窗口结束爬虫。

-
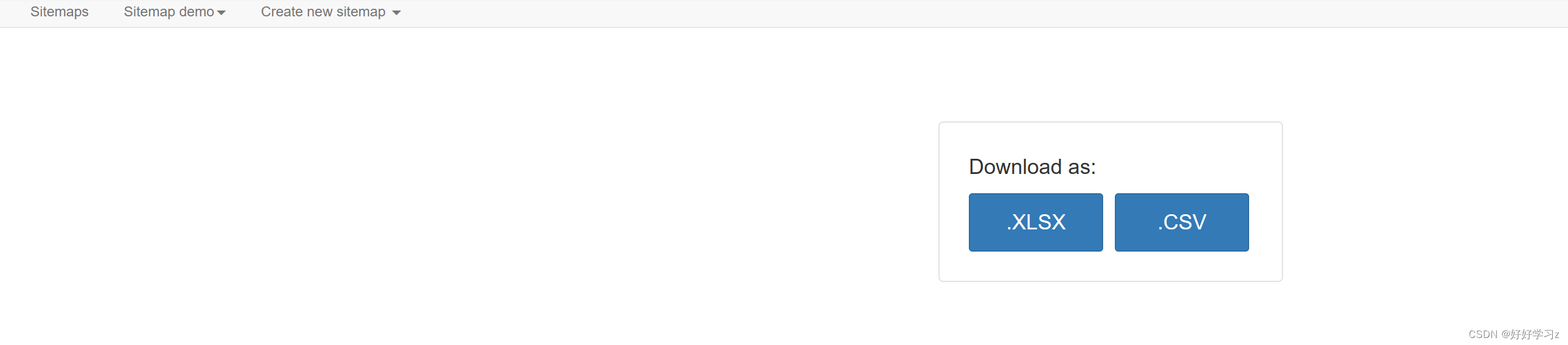
爬取结束后,点击 Sitemap demo > Export data可以选择以 .xlsx 或 .csv 的格式导出数据。
-
点击 Sitemap demo > Export Sitemap,可以将爬虫结构导出。

-
爬虫运行期间,总会因为网络波动或安全验证等原因导致爬取数据缺失。针对这种情况,我们在数据处理后将未爬取到的链接写入一个新的 HTML 文件中,然后以此 HTML 文件为起始网页运行 Web Scraper,对缺失的数据进行补充爬取。
-
本文的爬虫 json 如下,有需要的同学自取,直接点击 Create new sitemap > Import Sitemap 后粘贴即可:
{“_id”:“demo”,“startUrl”:[“https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8”],“selectors”:[{“delay”:1000,“elementLimit”:500,“id”:“scroll_page”,“multiple”:true,“parentSelectors”:[“_root”],“selector”:“#J_goodsList
ul > li >
div”,“type”:“SelectorElementScroll”},{“id”:“product”,“multiple”:false,“parentSelectors”:[“scroll_page”],“regex”:“”,“selector”:“div.p-name.p-name-
type-2”,“type”:“SelectorText”},{“id”:“click”,“linkType”:“linkFromHref”,“multiple”:false,“parentSelectors”:[“scroll_page”],“selector”:“.p-name
a”,“type”:“SelectorLink”},{“id”:“price”,“multiple”:false,“parentSelectors”:[“click”],“regex”:“”,“selector”:“span.price”,“type”:“SelectorText”},{“extractAttribute”:“”,“id”:“specification_category”,“parentSelectors”:[“click”],“selector”:“div.Ptable-
item
h3”,“type”:“SelectorGroup”},{“extractAttribute”:“”,“id”:“specification_name”,“parentSelectors”:[“click”],“selector”:“div.Ptable-
item dl.clearfix
dt”,“type”:“SelectorGroup”},{“extractAttribute”:“”,“id”:“specification_value”,“parentSelectors”:[“click”],“selector”:“dl.clearfix
dd:not(.Ptable-tips)”,“type”:“SelectorGroup”}]}
京东安全验证
- 在爬虫运行过程中,京东安全验证是一个极大的阻碍,基本上一两分钟就会跳出来,导致很多数据爬不全。而由于爬虫运行时的请求间隔和加载时间较短,很难在那么短的时间内完成滑块验证,所以在爬取界面直接完成验证难度很大。
- 数次尝试后,我发现在新的标签页再打开一个京东页面,也会出现安全验证,而此时不存在爬虫导致的需要很快的手速,完成验证后也能使爬虫继续获取数据。
- 这种方式一定程度上解决了由于安全验证导致数据缺失的问题,但终归无法实现自动完成验证,需要一直盯着浏览器窗口,一出现验证就及时处理。
- 经过测试发现, Web Scraper 可以同时在 Edge 和 Chrome 上执行不同的爬虫程序,但如果在一个浏览器上执行多个爬虫程序,会导致先执行的爬虫在后执行的爬虫开始执行前爬取到的数据丢失。
原创不易,麻烦大家点个关注收藏评论支持一下~~
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
网络安全学习资源分享:
最后给大家分享我自己学习的一份全套的网络安全学习资料,希望对想学习 网络安全的小伙伴们有帮助!
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
【点击领取】网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!

1.学习路线图

攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。【点击领取视频教程】

技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本【点击领取技术文档】

(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本【点击领取书籍】

4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。

最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…


因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享

