
热门标签
热门文章
- 1如何使用adb控制手机_adb 连接手机_adb连接手机
- 2中文多模态大模型基准8月榜单发布!8大维度30个测评任务,3个模型超过70分_internvl2
- 3[人工智能] AI浪潮下Sora对于普通人的机会
- 4JakartaEE servlet_jakarta.servlet
- 5联邦学习目前的热门研究方向_联邦学习研究的热点方向有哪些
- 603 pytorch 验证指标工具 torchmetrics_torchmetrics安装包
- 7FPGA Verilog 控制CAN接收发送数据帧(标准/扩展),遥控帧(标准/扩展)_修改 can-fpga
- 8第三章: AIGC的应用领域_aigc技术根据教学大纲和学习目标,自动生成课程内容,
- 9.gitignore忽略文件不生效_.gitignore文件不生效
- 10使用CTEX生成中文pdf_ctex怎么生成pdf
当前位置: article > 正文
mysql比较两个数据库表不同的数据_mysql 不同库两个表怎么对比数据
作者:煮酒与君饮 | 2024-08-10 08:06:12
赞
踩
mysql 不同库两个表怎么对比数据
之前写的说法是还是不够简便。
创建一个表t1:
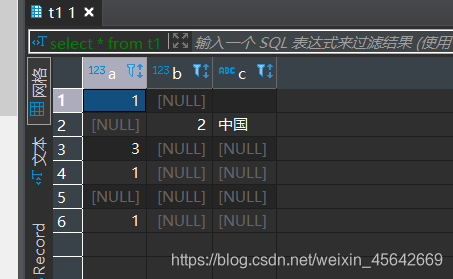
查询是否有不同数据。
select count(*) from (select DISTINCT * from t1)t
union all
select count(*) from t1;
- 1
- 2
- 3
比对这两个值。如果一样就确定这个表无重复数据。
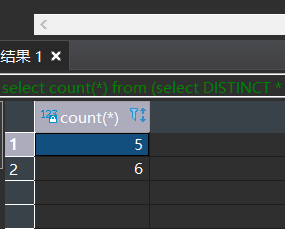
只有一条。
——————————————————————————————————————
比较某一个字段有无重复数据。
(比如表t1的a列有无重复数据)
select a,count(*) from t1 t
group by a
having count(*)>1;
- 1
- 2
- 3
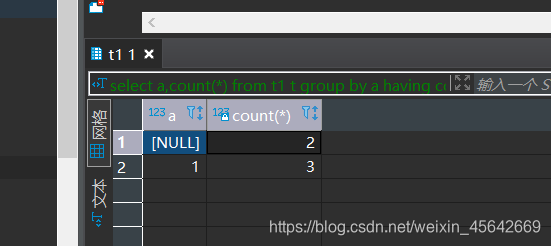
a列相同的有3条重复数据,重复的值分别为:
null重复的3条,1重复的两条。
————————————————————————————————————————
比较两个表不同的数据:
创建一个新表
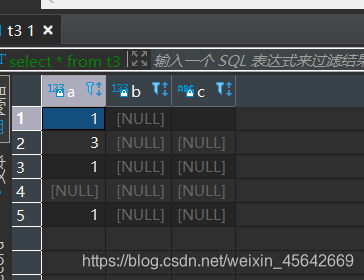
存在A表没有B表有,A表和B表不同、A表有B表没有这几个情况,所以挺难写的。
你得知道A表多了啥,B表多了啥,不然咋处理?
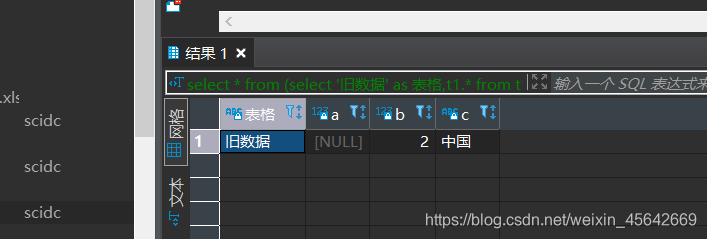
select * from
(select '旧数据' as 表格,t1.* from t1
union all
select '新数据' as 表格,t3.* from t3)t
group by a,b,c
having count(*)=1;
- 1
- 2
- 3
- 4
- 5
- 6
执行结果:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/957618
推荐阅读
相关标签

