
热门标签
热门文章
- 1Spark系列从入门到精通(二)_spark程序
- 2linux内核编译截图,【教程】嵌入式Linux中如何进行截屏?
- 3如何用AI提高论文阅读效率?用这个论文解读agent就够了!_如何使用ai提高论文阅读效率
- 4【Android】AS环境安装并运行第一个Android程序_开发环境搭建及运行android第一个应用程序
- 5Jenkins git plugin SSL验证修复_10:43:39 10:43:39 at org.jenkinsci.plugins.gitclie
- 6【云原生】ConfigMap存储_pod configmap
- 7python--random库
- 8HTML5新特性之WebSocket_html'5新增的websocket
- 9一位资深程序员的亲身经历:跳槽国企要注意啥
- 10【Linux】Linux项目自动化构建工具-make/Makefile(学习复习兼顾)_liunx 自动化工具
当前位置: article > 正文
微调Llama3实现在线搜索引擎和RAG检索增强生成功能_llama3 在线搜索
作者:煮酒与君饮 | 2024-08-08 01:15:05
赞
踩
llama3 在线搜索
微调Llama3实现在线搜索引擎和RAG检索增强生成功能!打造自己的perplexity和GPTs!用PDF实现本地知识库_哔哩哔哩_bilibili
Llama3高级定制:在线搜索与RAG检索增强,打造你的专属perplexity和GPTs知识库! - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI
一.准备工作
1.安装环境
- conda create --name unsloth_env python=3.10
- conda activate unsloth_env
-
- conda install pytorch-cuda=12.1 pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers
-
- pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
-
- pip install --no-deps trl peft accelerate bitsandbytes
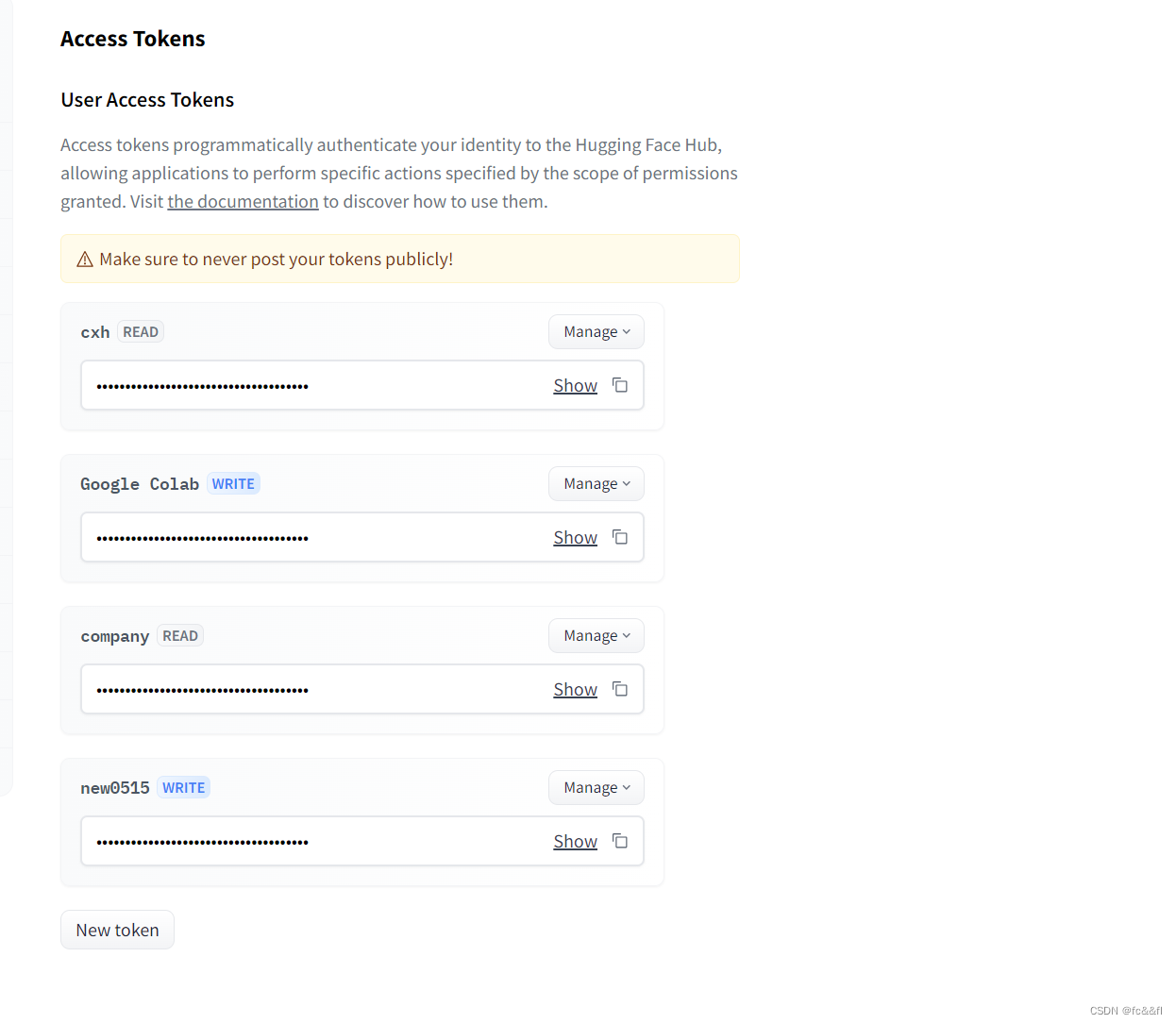
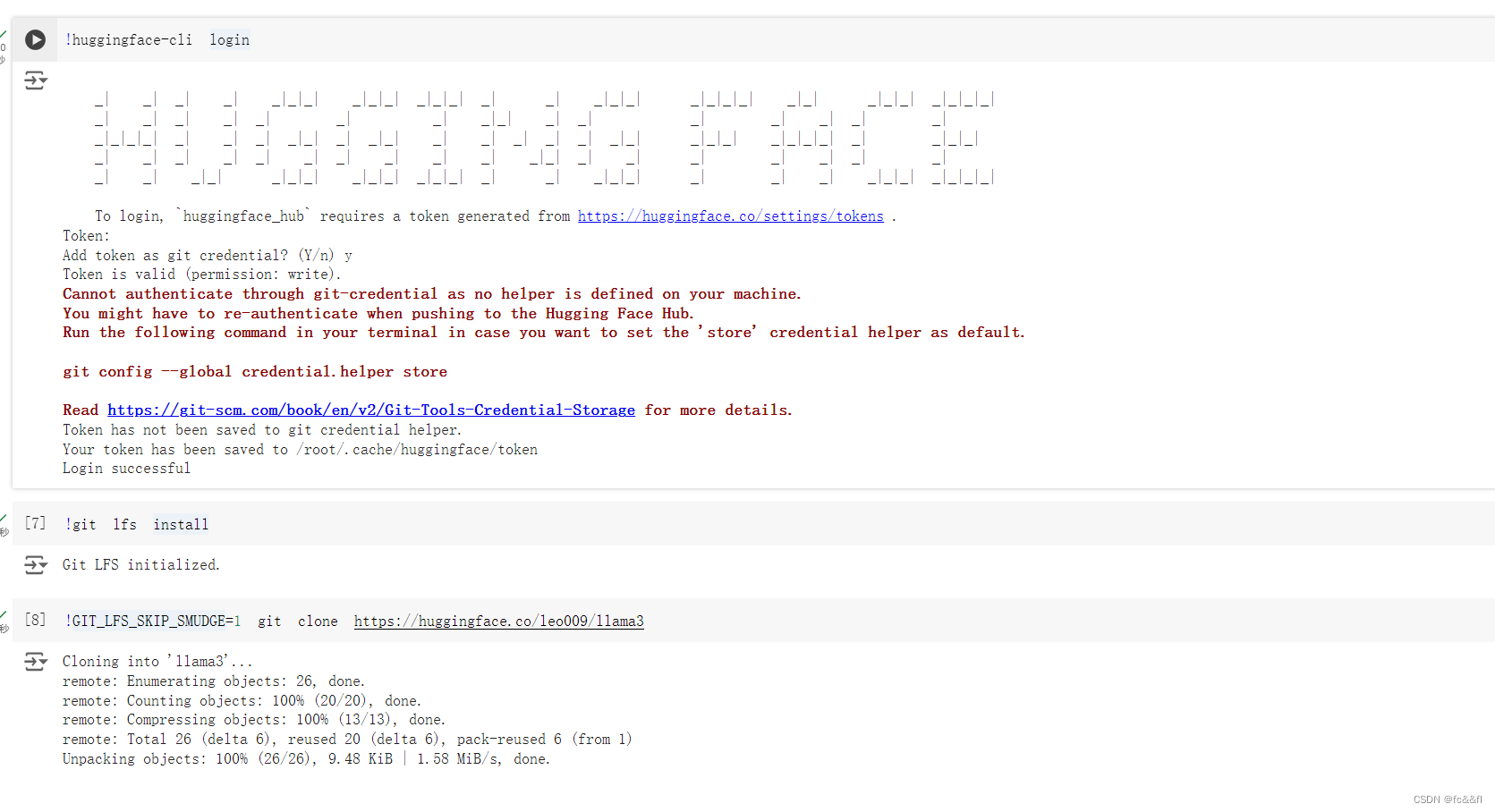
2.微调代码(要先登录一下)
huggingface-cli login
点击提示的网页获取token(注意要选择可写的)
-
- #dataset https://huggingface.co/datasets/shibing624/alpaca-zh/viewer
-
- from unsloth import FastLanguageModel
- import torch
-
- from trl import SFTTrainer
- from transformers import TrainingArguments
-
-
-
-
- max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
- dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
- load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
-
- # 4bit pre quantized models we support for 4x faster downloading + no OOMs.
- fourbit_models = [
- "unsloth/mistral-7b-bnb-4bit",
- "unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
- "unsloth/llama-2-7b-bnb-4bit",
- "unsloth/gemma-7b-bnb-4bit",
- "unsloth/gemma-7b-it-bnb-4bit", # Instruct version of Gemma 7b
- "unsloth/gemma-2b-bnb-4bit",
- "unsloth/gemma-2b-it-bnb-4bit", # Instruct version of Gemma 2b
- "unsloth/llama-3-8b-bnb-4bit", # [NEW] 15 Trillion token Llama-3
- ] # More models at https://huggingface.co/unsloth
-
- model, tokenizer = FastLanguageModel.from_pretrained(
- model_name = "unsloth/llama-3-8b-bnb-4bit",
- max_seq_length = max_seq_length,
- dtype = dtype,
- load_in_4bit = load_in_4bit,
- # token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
- )
-
- model = FastLanguageModel.get_peft_model(
- model,
- r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
- target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
- "gate_proj", "up_proj", "down_proj",],
- lora_alpha = 16,
- lora_dropout = 0, # Supports any, but = 0 is optimized
- bias = "none", # Supports any, but = "none" is optimized
- # [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
- use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
- random_state = 3407,
- use_rslora = False, # We support rank stabilized LoRA
- loftq_config = None, # And LoftQ
- )
-
- alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
- ### Instruction:
- {}
- ### Input:
- {}
- ### Response:
- {}"""
-
- EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
- def formatting_prompts_func(examples):
- instructions = examples["instruction"]
- inputs = examples["input"]
- outputs = examples["output"]
- texts = []
- for instruction, input, output in zip(instructions, inputs, outputs):
- # Must add EOS_TOKEN, otherwise your generation will go on forever!
- text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
- texts.append(text)
- return { "text" : texts, }
- pass
-
- from datasets import load_dataset
-
- #file_path = "/home/Ubuntu/alpaca_gpt4_data_zh.json"
-
- #dataset = load_dataset("json", data_files={"train": file_path}, split="train")
-
- dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
-
- dataset = dataset.map(formatting_prompts_func, batched = True,)
-
-
-
-
- trainer = SFTTrainer(
- model = model,
- tokenizer = tokenizer,
- train_dataset = dataset,
- dataset_text_field = "text",
- max_seq_length = max_seq_length,
- dataset_num_proc = 2,
- packing = False, # Can make training 5x faster for short sequences.
- args = TrainingArguments(
- per_device_train_batch_size = 2,
- gradient_accumulation_steps = 4,
- warmup_steps = 5,
- max_steps = 60,
- learning_rate = 2e-4,
- fp16 = not torch.cuda.is_bf16_supported(),
- bf16 = torch.cuda.is_bf16_supported(),
- logging_steps = 1,
- optim = "adamw_8bit",
- weight_decay = 0.01,
- lr_scheduler_type = "linear",
- seed = 3407,
- output_dir = "outputs",
- ),
- )
-
- trainer_stats = trainer.train()
-
- model.save_pretrained_gguf("llama3", tokenizer, quantization_method = "q4_k_m")
- model.save_pretrained_gguf("llama3", tokenizer, quantization_method = "q8_0")
- model.save_pretrained_gguf("llama3", tokenizer, quantization_method = "f16")
-
-
- #to hugging face
- model.push_to_hub_gguf("leo009/llama3", tokenizer, quantization_method = "q4_k_m")
- model.push_to_hub_gguf("leo009/llama3", tokenizer, quantization_method = "q8_0")
- model.push_to_hub_gguf("leo009/llama3", tokenizer, quantization_method = "f16")
3.我们选择将hugging face上微调好的模型下载下来(https://huggingface.co/leo009/llama3/tree/main)
4.模型导入ollama
下载ollama
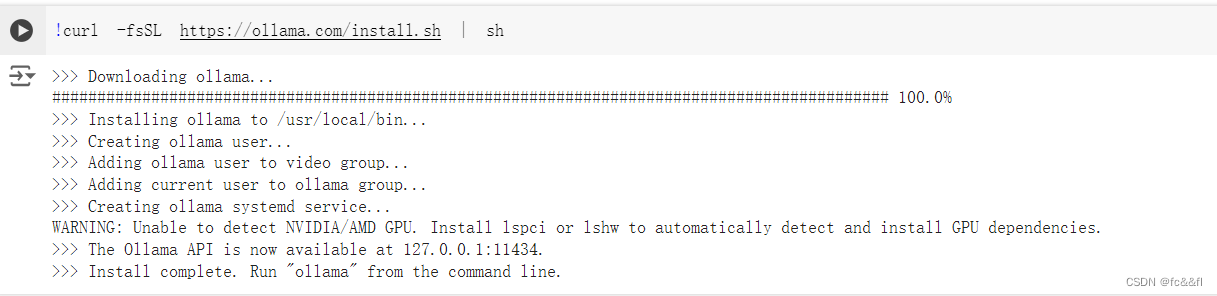
导入ollama
- FROM ./downloads/mistrallite.Q4_K_M.gguf
- ollama create example -f Modelfile
二.实现在线搜索
1.获取Tavily AI API
export TAVILY_API_KEY=tvly-xxxxxxxxxxx2.安装对应的python库
install tavily-python
pip install phidata
pip install ollam
3.运行app.py
- #app.py
- import warnings
-
- # Suppress only the specific NotOpenSSLWarning
- warnings.filterwarnings("ignore", message="urllib3 v2 only supports OpenSSL 1.1.1+")
-
- from phi.assistant import Assistant
- from phi.llm.ollama import OllamaTools
- from phi.tools.tavily import TavilyTools
-
-
- # 创建一个Assistant实例,配置其使用OllamaTools中的llama3模型,并整合Tavily工具
- assistant = Assistant(
- llm=OllamaTools(model="mymodel3"), # 使用OllamaTools的llama3模型
- tools=[TavilyTools()],
- show_tool_calls=True, # 设置为True以展示工具调用信息
- )
-
- # 使用助手实例输出请求的响应,并以Markdown格式展示结果
- assistant.print_response("Search tavily for 'GPT-5'", markdown=True)
三.实现RAG
1.git clone https://github.com/phidatahq/phidata.git
2.phidata---->cookbook---->llms--->ollama--->rag里面 有示例和教程
修改assigant.py中的14行代码,将llama3改为自己微调好的模型
另外需要注意的是!!!
要将自己的模型名称加入到app.py里面的数组里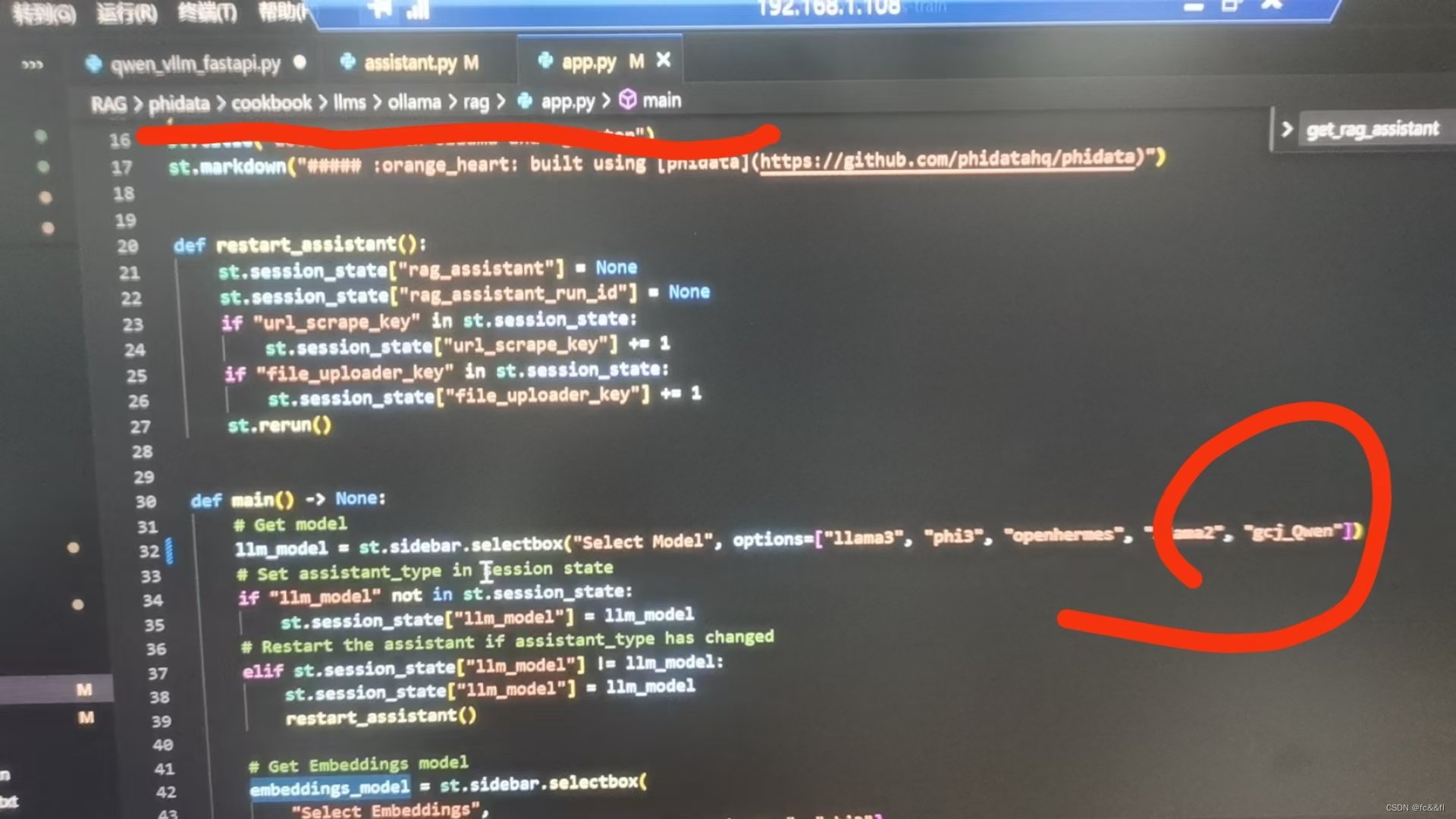
streamlit run /home/cxh/phidata/cookbook/llms/ollama/rag/assistant.py
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/945391
推荐阅读
相关标签

