
图神经网络的5个基础模型_图神经网络模型
赞
踩
为什么需要GCN(图神经网络)?
随着机器学习和深度学习的发展,简单的序列和网格数据等结构化数据处理取得很大突破,但是对于非结构化数据呢?
图神经网络是什么样子?
图神经网络相比于基本的网络结构的全连接层,多了一个邻接矩阵。
1、Graph Convolution Networks(GCN)
Semi-Supervised Classification with Graph Convolutional Networks(ICLR2017) https://arxiv.org/pdf/1609.02907
GCN可谓是图神经网络的开山之作,首次将图像处理中的卷积操作简单的运用到图结构数据处理中来,给出了推导,涉及到复杂的谱图理论(这个有时间在整理一下)。参考:
1、如何理解 Graph Convolutional Network(GCN)?https://www.zhihu.com/question/54504471
2、GNN 系列:图神经网络的“开山之作”CGN模型 https://mp.weixin.qq.com/s/jBQOgP-I4FQT1EU8y72ICA
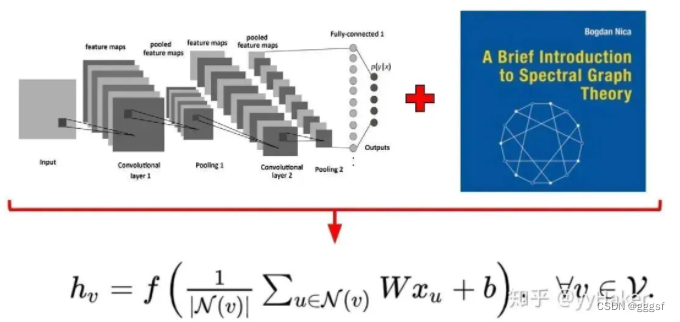
聚合邻居节点的特征做线性变换,同时为了捕捉到K-hop的邻居节点信息,作者堆叠多层GCN layers。
将GCN防在分类节点任务上,在数据集上进行实验,相比于传统的方法有明显提升。
GCN缺点:GCN需要将整个图放到内存和显存,非常耗内存和显存,处理不了大图;GCN在训练的时候需要知道整个图的结构信息。
2、Graph Sample and Aggregate(GraphSAGE)
Inductive Representation Learning on Large Graphs(2017NIPS) https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf
为了解决GCN两个缺点问题,GraphSAGE被提了出来。
Transductive learning:GCN输入了整个图,训练节点收集邻居节点信息的时候,用到了测试和验证集的样本。
Inductive learning:刻意将样本分为训练、验证、测试,训练的时候只用训练样本。
这样的操做对图有个好处,可以处理图中新来的节点,可以利用已知节点的信息为未知节点生成embedding。
(什么是enbedding:https://blog.csdn.net/yuanmiyu6522/article/details/120930840)
GraphSAGE是一个Inductive Learning框架:训练时它仅仅保留训练样本到训练样本的边,包含Sample和Aggregate两大步骤,Sample是指如何对邻居的个数进行采样,Aggregate是指拿到邻居节点的embedding之后如何汇聚这些embedding更新自己的embedding信息。
GraphSAGE的一个学习过程如图所示:
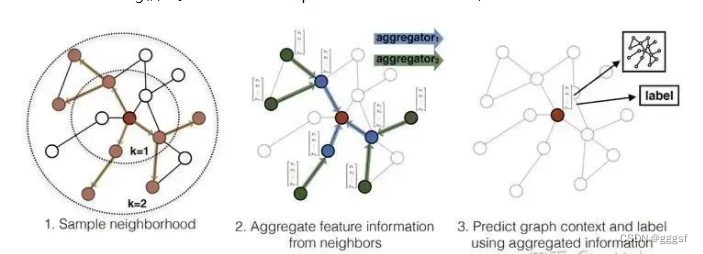
1、对邻居采样
2、采样后的邻居embedding传到节点上来,并使用一个聚合函数聚合这写邻居信息以更节点的embedding
3、根据更新后的embedding预测节点的标签
操作:
1、初始化图中所有节点的特征向量
2、对于每个节点拿到它采样的邻居节点后
3、利用聚合函数聚合邻居节点的信息
4、结合自身embedding通过一个非线性变换更新自身的embedding表示
网络的层数可理解为需要最大访问的邻居的跳数(hops)。图中节点拿到它一、二跳邻居的信息,网络层数就是2,为了更新红色节点,首先在第一层将蓝色节点的信息聚合到红色节点上,将绿色节点的信息聚合到蓝色节点上。到第二层红色节点的embedding再次被更新,保证红色节点更新后的embedding包括蓝色和绿色节点的信息,即两跳信息。
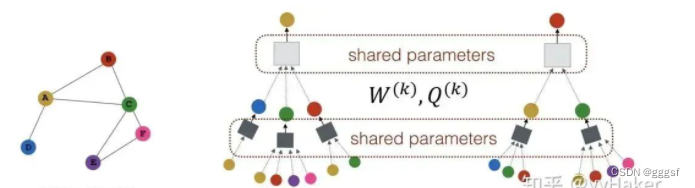
Sample?GraphSAGE采用定长抽样的方法:定义所需邻居的个数,采用有放回的重采样。保证每个节点邻居个数一致,把多个节点以及他们的邻居拼接成Tensor送到GPU进行批训练。
聚合器:
Mean、LSTM、Pooling
graphSAGE如何学习聚合器参数和权重矩阵:
有监督:每个节点的预测lable和真实的lable的交叉熵作为损失函数
无监督:假设相邻的节点的embedding尽可能相近,损失函数

GraphSAGE:
(1)采样机制,很好的解决GCN要知道的全部图的信息,克服了GCN训练时内存和显存的限制,对于未知的节点也可以得到其表示
(2)聚合器和权重矩阵的参数对节点共享
(3)模型参数数量与节点个数无关
缺点:邻居有的重要有的不重要,有的是好邻居有的是不好的邻居。邻居比本人重要还是不重要?
3、Graph Attention Networks(GAT)
Graph Attention Networks(ICLR2018) https://arxiv.org/pdf/1710.10903
GAT出现的意义?
考虑邻居的重要性,GAT借鉴Transformer,引入masked self-attention机制,根据节点的特征分配不同的权值。
一个graph attention layer如图:
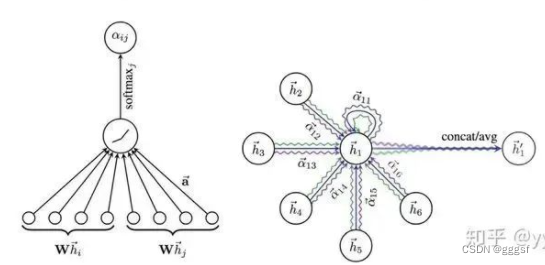
GAT优点:
(1)训练GCN无需了解整个图的结构,只需要知道每个节点的邻居节点即可
(2)计算速度快,在不同节点上进行并行运算
(3)可以用于Transductive Learning也可以用于Inductive Learning,对未见过的图结构进行处理。
4、无监督的节点表示学习
标注数据成本高,无监督学习节点表示。
GraphSAGE是一种很好的无监督学方法(Graph Auto-Encoder也是)。
Auto-Encoder(自编码器)
Variational Auto-Encoder(变分自编码器)
AE与VAE
参考:https://zhuanlan.zhihu.com/p/531763049
变分图的自编码器:
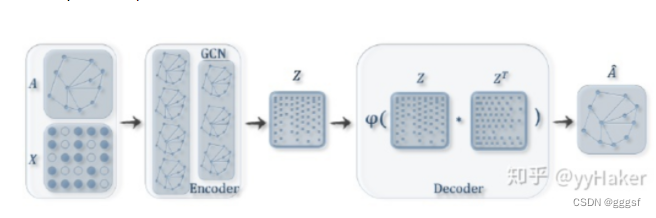
输入图的邻接矩阵和节点的特征矩阵,通过编码器学习低维向量表示的均值和方差,用解码器生成图。
编码器:采用两层GCN,解码器计算两点之间存在的变得概率来重构图,损失函数包括生成图和原始图之间的距离度量,以及表示向量分布和正态分布的KL散度。
图自编码器:
Encoder两层GCN,Loss只包含Reconstruction Loss。
结果GAE和VGAE效果普遍好,VGAE更好,但是调参困难。
5、Graph pooling
是为了获取一整个图的表示,用于处理图级别的分类任务,有监督的图分类、文档分类等。
Graph pooling方法有很多,简单的max pooling和mean pooling,这两种方法有局限性,局限性就是忽视了节点的顺序信息,新方法:Differentiable Pooling
DiffPool:生成图的层级结构,以端到端的方式被各种图神经网络整合。
核心思想:通过一个可微池化操作模块去分层的聚合图节点。可微池化操作模块基于GNN上一层生成节点嵌入以及分配矩阵,以端到端的方式分配给下一层的簇,然后将这些簇输入到GNN下一层,进而实现用分层的方式堆叠多个GNN层的想法。
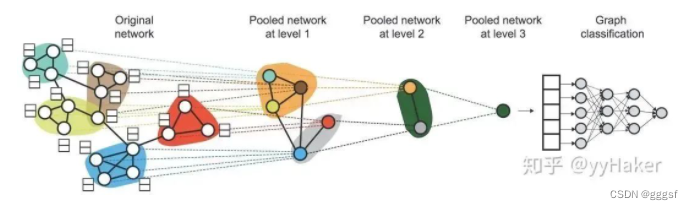
DiffPool优点:
(1)可以学习层次化pooling策略
(2)可以学习图的层次化表示
(3)可以端到端的方式被各种图神经网络整合
缺:
分配矩阵需要很大的空间去存储,空间复杂度随着池化层的层数变大。
本文只是为了写下梳理自己的知识框架,主要内容可以移步下方:
本文来源:https://zhuanlan.zhihu.com/p/136521625

