
- 1华中农业大学计算机学硕,华中农业大学工学院2017年研究生招生预录取名单(含专业和导师)...
- 2用c语言计算正四棱锥的体积,刘徽与正四棱台体积的计算
- 3AI Agent在11个领域100个应用场景_ai agent应用
- 4使用变更数据捕获方法通过提取-转换-加载过程实时更新数据仓库_数据捕捉提取转换加载
- 5大数据技术应用干货:Spark在360商业数据部的应用实践_使用sparksql进行数据分析比mapreduce更容易
- 6python:imaplib --- IMAP4 协议客户端_python imaplib
- 7vue3初始搭建项目完整教程 vue3 + vite + element-ui + axios_vue3初始化项目
- 8VUE ElementUI Admin使用table时,选中某行或者鼠标移入某行时添加背景色_elementui表格选中用什么色加深
- 9数据库(mysql)忘记密码解决办法
- 10linux下载安装fastdfs和fastdfs与nginx整合、springboot访问fastdfs_服务器下载fastdfs
Linux安装Spark-详细步骤及常见报错_failed to find spark jars directory
赞
踩
目录
一、前期环境配置
Hadoop单机环境搭建
Java环境搭建
二、Spark安装及相关配置
三、Hadoop及Spark安装报错
一、前期环境配置
Hadoop单机环境搭建
创建新用户hadoop
- sudo useradd -m hadoop -s /bin/bash
- sudo passwd hadoop #设置密码
- sudo adduser hadoop sudo #增加用户权限
更新apt,下载vim
- sudo apt-get update
- sudo apt-get install vim
安装SSH,配置无密码登录
- sudo apt-get install openssh-server
- ssh localhost
- exit # 退出刚才的 ssh localhost
- cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
- ssh-keygen -t rsa # 会有提示,都按回车就可以
- cat ./id_rsa.pub >> ./authorized_keys # 加入授权
Java环境搭建
jdk下载地址:链接: https://pan.baidu.com/s/1xrg-tk73T7U4RYRhBQ5UMg 提取码: bv8c
- cd /usr/lib
- sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
- cd ~ #进入hadoop用户的主目录
- cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
- sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
- cd /usr/lib/jvm
- ls
- cd ~
- vim ~/.bashrc
添加如下内容
- export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
- export JRE_HOME=${JAVA_HOME}/jre
- export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
- export PATH=${JAVA_HOME}/bin:$PATH
使配置生效
- source ~/.bashrc #使配置生效
- java -version #检测是否安装成功
安装Hadoop
- sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
- cd /usr/local/
- sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
- sudo chown -R hadoop ./hadoop # 修改文件权限
- cd /usr/local/hadoop
- ./bin/hadoop version #成功则输出版本信息
启动Hadoop
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格,启动hadoop
- ./sbin/stop-dfs.sh #关闭hadoop
二、Spark安装及相关配置
安装Spark:官方下载地址
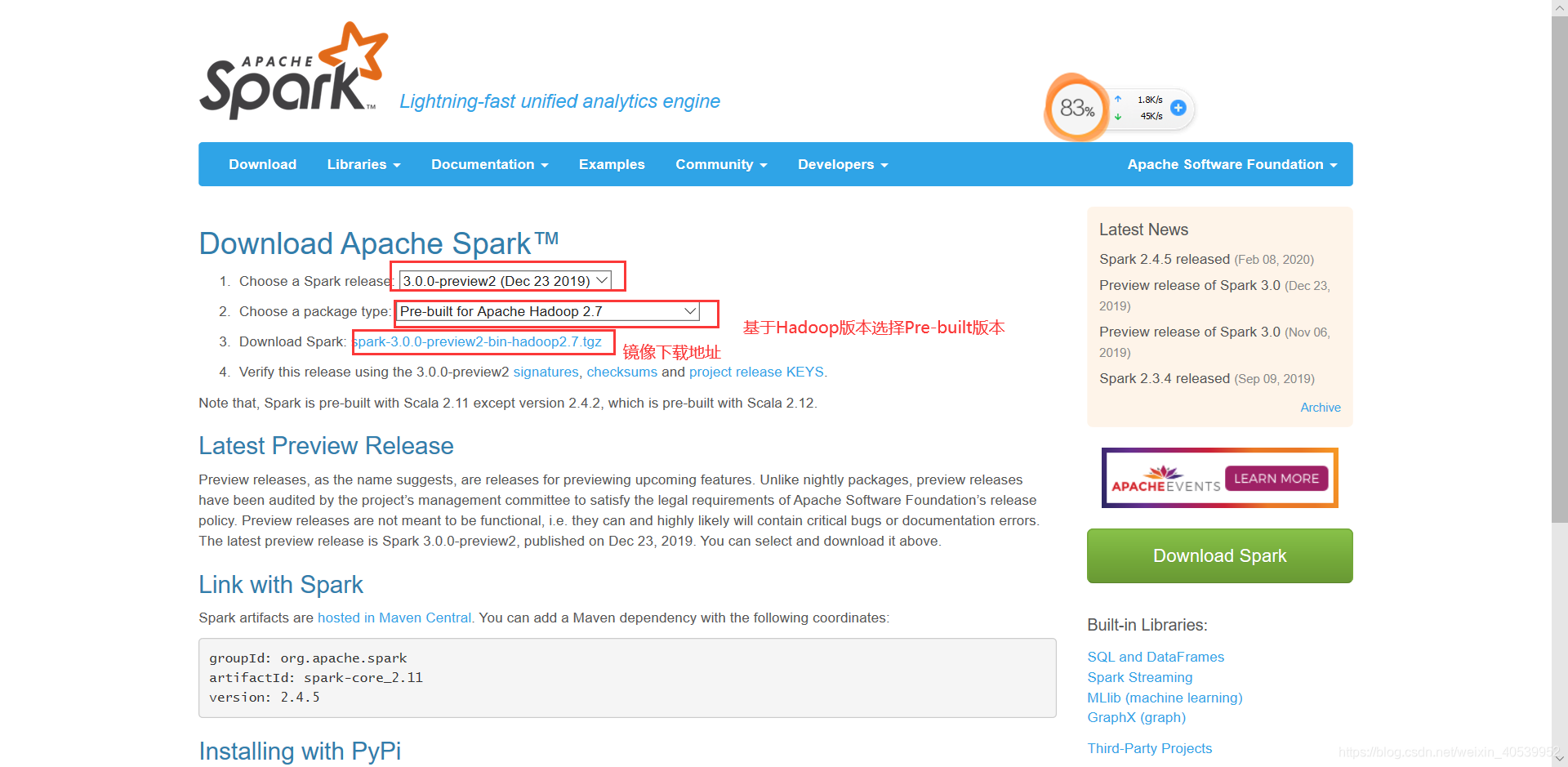
相关配置修改
- sudo tar -zxf ~/下载/spark-1.6.2-bin-without-hadoop.tgz -C /usr/local/
- cd /usr/local
- sudo mv ./spark-1.6.2-bin-without-hadoop/ ./spark
- sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
- cd /usr/local/spark #修改配置
- cp ./conf/spark-env.sh.template ./conf/spark-env.sh
- vim ./conf/spark-env.sh
在env文件中插入
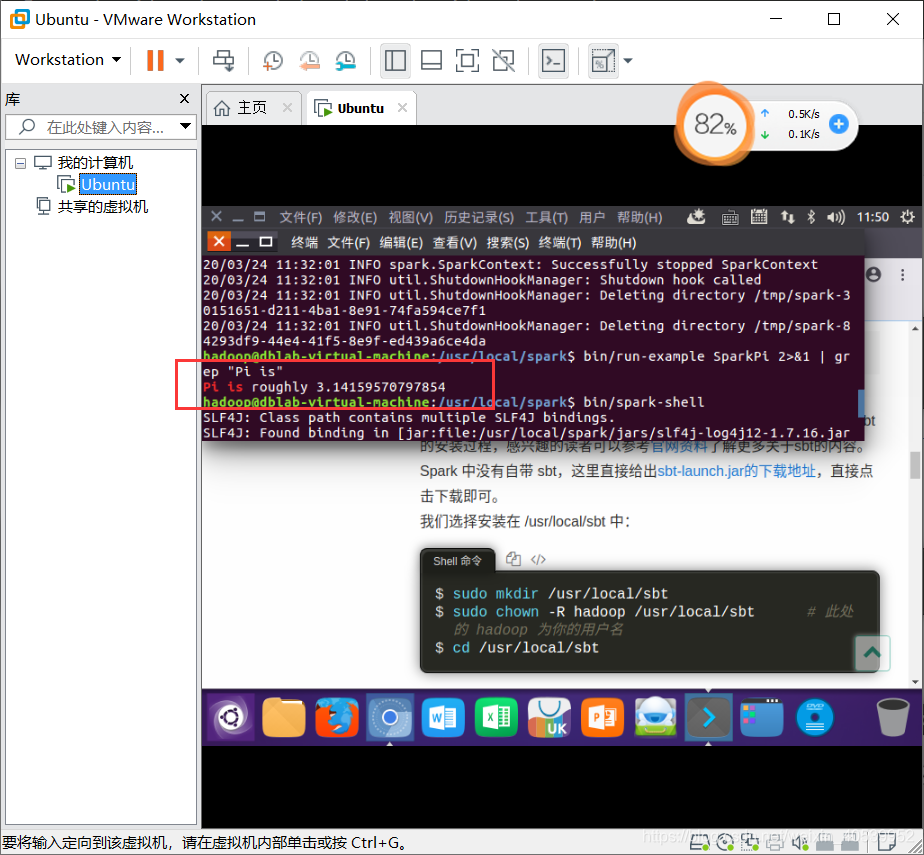
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)- cd /usr/local/spark #测试是否安装成功
- bin/run-example SparkPi 2>&1 | grep "Pi is" #出现下列截图即安装成功
三、Hadoop及Spark安装报错
问题1:ssh: Could not resolve hostname xxx
解决办法:在~/.bashrc中加入,修改完成后输入jps查看是否修改成功。
- export HADOOP_HOME=/usr/local/hadoop
- export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
问题2:DataNode无法启动
解决办法:这种办法会损坏原有HDFS中数据
- # 针对 DataNode 没法启动的解决方法
- cd /usr/local/hadoop
- ./sbin/stop-dfs.sh # 关闭
- rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
- ./bin/hdfs namenode -format # 重新格式化 NameNode
- ./sbin/start-dfs.sh # 重启
问题3:Failed to find Spark jars directory.......You need to build the Spark with the package.......
解决办法:这里的Spark版本安装与Hadoop的安装版本不匹配,建议直接重新安装与Hadoop匹配的Spark版本。
四、Spark基础知识点
三大分布式计算系统:Spark.Hadoop.Storm
Spark生态系统:Spark Core;Spark Sql;Spark Streaming;Mllib;GraphX
RDD:弹性分布式数据集(共享内存模型),在内存中进行,管道化操作;
RDD执行过程:读入数据集(可以分为多个分区);一系列转换操作(惰性机制,只是记录转换的轨迹);进行动作操作,完成第二步的所有计算并输出到外部节点;
RDD优势:具有良好的容错机制;内存持久化;无需进行序列化和反序列化操作;
RDD依赖关系:窄依赖(一个父分区对一个孩子分区;多个RDD父分区对应一个孩子分区),宽依赖(一个父RDD一个分区对应一个子RDD多个分区);
Stage类型:ShuffleMapStage;ResultStage(没有输出,直接产生结果,至少含有1个);

