
热门标签
热门文章
- 1基于ros-qt 开发ui界面完成标定工具包_标定界面ui
- 2RK3568技术笔记十五 固件烧写_rk3568固件解sr
- 3ES聚合查询详解(二):桶聚合_mindoccount
- 4自己电脑做服务器需要装什么系统,自己电脑做服务器需要什么配置
- 5在idea下terminal输入git的status命令后出现中文乱码\346\240\210/的解决办法_idea使用git status之后无法输入命令了
- 6【Yarn】系统架构&高可用_yarn采用的体系架构是主从结构,其中主节点是 ,从节点是 。
- 7大数据的5V特征分别是什么?_大数据5v特性
- 8各种对抗神经网络(GAN)大合集_gan non-overlapping
- 9git合并分支(一看就懂)_合并分支成功后显示啥页面
- 10程序猿214情人节专题----基于GitHub打造个人网站及Android的录制功能使用_android 录像github
当前位置: article > 正文
Yolov5 中添加注意力机制 CBAM_yolov5 cbam
作者:煮酒与君饮 | 2024-07-24 09:02:12
赞
踩
yolov5 cbam
1. CBAM
CBAM(Convolutional Block Attention Module)是一种注意力机制,它通过关注输入数据中的重要特征来增强卷积神经网络(CNN)的性能。CBAM的原理可以分为两个部分:空间注意力模块和通道注意力模块。
- 空间注意力模块:该模块关注输入特征图的每个空间位置的重要性。它首先对特征图的每个通道进行全局平均池化,然后使用1x1卷积将通道数调整为与输入特征图相同的大小。接着,使用sigmoid激活函数对每个空间位置的激活进行归一化,最后使用全局最大池化获取最重要的空间信息。
- 通道注意力模块:该模块关注每个通道对最终输出贡献的重要性。它首先对每个通道的特征进行全局平均池化,然后使用1x1卷积将通道数调整为与输入特征图相同的大小。接着,使用sigmoid激活函数对每个通道的激活进行归一化,最后使用全局最大池化获取最重要的通道信息。
CBAM将这两个注意力模块嵌入到CNN的卷积层之间,以增强网络对重要特征的关注度。实验表明,CBAM可以显著提高CNN的性能,特别是在图像分类、目标检测和语义分割等任务中。
1.1 Channel Attention Module
先上一下代码:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(nn.Conv2d(in_planes, in_planes // 16, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // 16, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
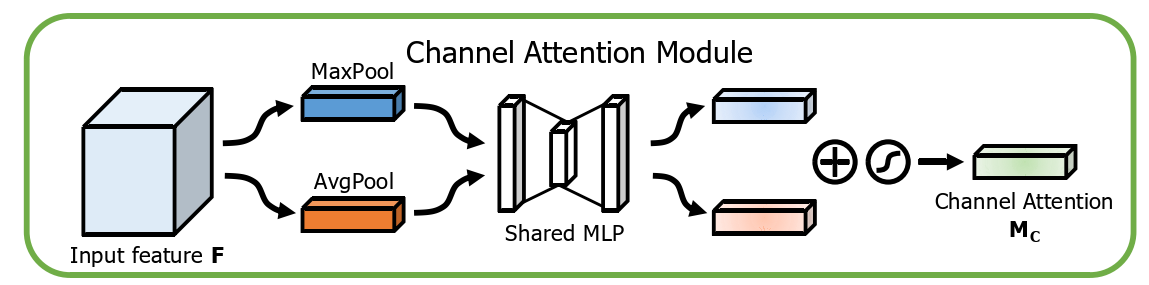
Channel Attention的流程为:
- 输入一组特征;
- 对特征在空间维度上进行MaxPool,即最大值池化;
- 对特征在空间维度上进行AvgPool,即平局池化;
- 经过池化后的两组特征分别进入MLP网络中,分别得到两组新的特征;
- 然后将两组新的特征进行相应元素一一相加,再通过激活函数,就得到一组所需要的新的特征;
channel attention 主要关注输入特征中的“what”,即在这么多特征中,哪些才是有意义的部分。
- 1
MLP的作用是让特征向量不同维度之间做充分的交叉,让模型能够抓取到更多的非线性特征和组合特征的信息
- 1
其数学表达式如下:
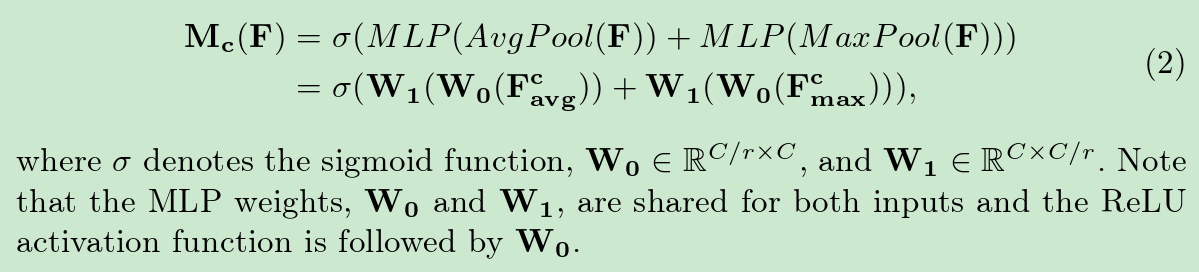
1.2 Spatial Attention Module
先上一下代码:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
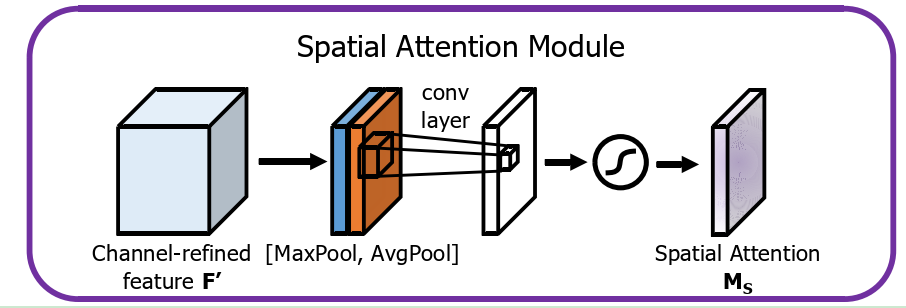
Spatial Attention的流程为:
- 输入一组特征;
- 对特征在通道维度上进行MaxPool,即最大值池化;
- 对特征在通道维度上进行AvgPool,即平局池化;
- 然后将两组特征进行concatenate组成新的特征;
- 将新的特征送入卷积,得到2D空间注意力特征图;
- 最后通过激活函数得到需要的特征;
spatial attention 主要关注输入特征中的“where”,即在所有特征中,哪些部分需要去关注。
- 1
1.3 Channel attention 和 Spatial attention 如何去使用
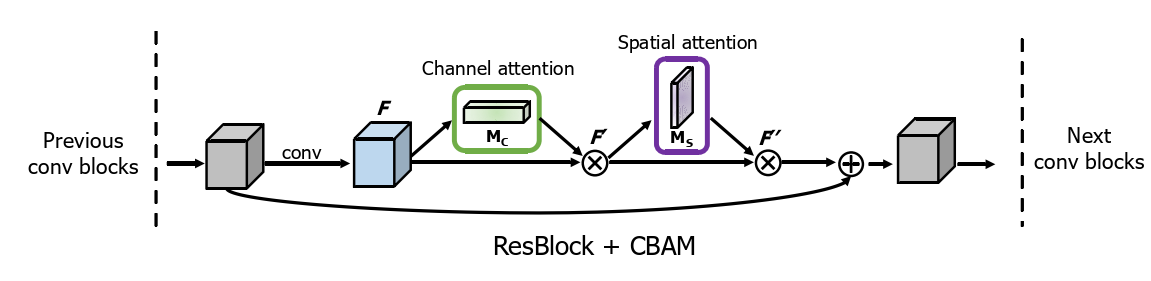
从上图中可以看到,前面的卷积神经网络提前特征后,分别进行两个通道注意力计算,两个通道可以并行也可以串行,但是原作者在实验中发现,串行且channel在spatial之前,性能会更好。每个注意出来后,都需要与输入进行一次对应元素的点乘;
其表达式如下:
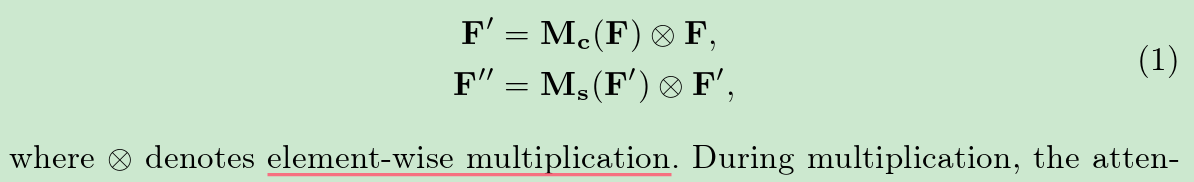
2. 在Yolov5中添加CBAM模块
参考文章如下:https://blog.csdn.net/qq_27353621/article/details/125603799
2.1 修改common.py 文件
路径:models/common.py
在common.py的尾部添加如下代码,即Channel Attention 模块、Spatial Attention模块、CBAMC3模块
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return torch.mul(x, out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv(out))
return torch.mul(x, out)
class CBAMC3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAMC3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c2, 16)
self.spatial_attention = SpatialAttention(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
# 将最后的标准卷积模块改为了注意力机制提取特征
return self.spatial_attention(
self.channel_attention(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
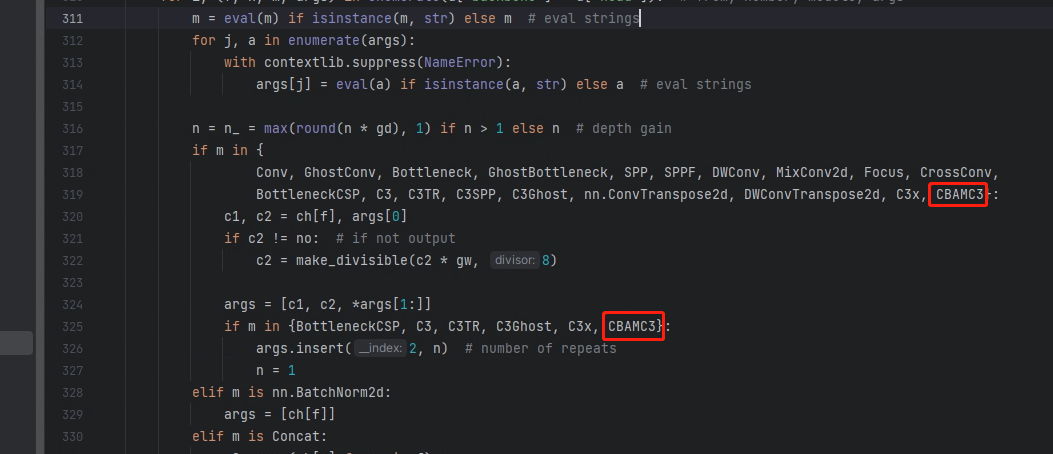
2.2 修改yolo.py 文件
路径:models/yolo.py
修改如下
2.3 修改网络配置yolov5x-seg.yaml文件
路径:models/segment/yolov5x-seg.yaml
将C3替换为CBAMC3
# YOLOv5 声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

