
- 1tensorflow 车牌识别项目(一)_车牌定位的标签文件时json吗
- 2【Android高级UI】PorterDuffMode颜色混合公式
- 3【推荐】AI人工智能-机器视觉-深度学习资料合集44篇_人工智能50问
- 4微信小程序消息通知开发
- 509.9 python基础--openpyxl库_openpyxl根据标题定位
- 6在Kubernetes中采用零信任: 基本原则_implementing zero-trust on kubernetes
- 7【常用工具】MSF使用教程(一)漏洞扫描与利用(以永恒之蓝漏洞复现为例)_msf漏洞扫描_msf渗透工具
- 82024年最新github之Go语言开源项目top50排行榜项目_golang开源项目排行
- 9ibm入职测试题太难了_IBM面试经验
- 10大学生宿舍管理系统的设计与实现|SSM+ Mysql+Java+ B/S结构(可运行源码+数据库+LW)校园,高校,公寓,住宿,寝室,晚归登记水电缴费宿舍维修卫生管理留言管理_如何设计一个宿舍系统
Elasticsearch 高频面试题(含答案),2024年最新阿里的面试官_elasticsearch面试题
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
(5)设置合理的路由机制。
1.4、其他调优
部署调优,业务调优等。
上面的提及一部分,面试者就基本对你之前的实践或者运维经验有所评估了。
2、elasticsearch 的倒排索引是什么
面试官:想了解你对基础概念的认知。
解答:通俗解释一下就可以。
传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置。
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。有了倒排索引,就能实现 o(1)时间复杂度的效率检索文章了,极大的提高了检索效率。

学术的解答方式:
倒排索引,相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
加分项:倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
lucene 从 4+版本后开始大量使用的数据结构是 FST。FST 有两个优点:
(1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
(2)查询速度快。O(len(str))的查询时间复杂度。
3、elasticsearch 索引数据多了怎么办,如何调优,部署
面试官:想了解大数据量的运维能力。
解答:索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户检索或者其他业务受到影响。
如何调优,正如问题 1 所说,这里细化一下:
3.1 动态索引层面
基于模板+时间+rollover api 滚动创建索引,举例:设计阶段定义:blog 索引的模板格式为:blog_index_时间戳的形式,每天递增数据。这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线 2 的32 次幂-1,索引存储达到了 TB+甚至更大。
一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
3.2 存储层面
冷热数据分离存储,热数据(比如最近 3 天或者一周的数据),其余为冷数据。
对于冷数据不会再写入新数据,可以考虑定期 force_merge 加 shrink 压缩操作,节省存储空间和检索效率。
3.3 部署层面
一旦之前没有规划,这里就属于应急策略。
结合 ES 自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注意:如果之前主节点等规划合理,不需要重启集群也能完成动态新增的。
4、elasticsearch 是如何实现 master 选举的
面试官:想了解 ES 集群的底层原理,不再只关注业务层面了。
解答:
前置前提:
(1)只有候选主节点(master:true)的节点才能成为主节点。
(2)最小主节点数(min_master_nodes)的目的是防止脑裂。
核对了一下代码,核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。选举流程大致描述如下:
第一步:确认候选主节点数达标,elasticsearch.yml 设置的值
discovery.zen.minimum_master_nodes;
第二步:比较:先判定是否具备 master 资格,具备候选主节点资格的优先返回;
若两节点都为候选主节点,则 id 小的值会主节点。注意这里的 id 为 string 类型。
题外话:获取节点 id 的方法。
1GET /_cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
2ip port heapPercent heapMax id name
5、详细描述一下 Elasticsearch 索引文档的过程
面试官:想了解 ES 的底层原理,不再只关注业务层面了。
解答:
这里的索引文档应该理解为文档写入 ES,创建索引的过程。
文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程。
记住官方文档中的这个图。

第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
第二步:节点 1 接受到请求后,使用文档_id 来确定文档属于分片 0。请求会被转到另外的节点,假定节点 3。因此分片 0 的主分片分配到节点 3 上。
第三步:节点 3 在主分片上执行写操作,如果成功,则将请求并行转发到节点 1和节点 2 的副本分片上,等待结果返回。所有的副本分片都报告成功,节点 3 将向协调节点(节点 1)报告成功,节点 1 向请求客户端报告写入成功。
如果面试官再问:第二步中的文档获取分片的过程?
回答:借助路由算法获取,路由算法就是根据路由和文档 id 计算目标的分片 id 的过程。
1shard = hash(_routing) % (num_of_primary_shards)
6、详细描述一下 Elasticsearch 搜索的过程?
面试官:想了解 ES 搜索的底层原理,不再只关注业务层面了。
解答:
搜索拆解为“query then fetch” 两个阶段。
query 阶段的目的:定位到位置,但不取。
步骤拆解如下:
(1)假设一个索引数据有 5 主+1 副本 共 10 分片,一次请求会命中(主或者副本分片中)的一个。
(2)每个分片在本地进行查询,结果返回到本地有序的优先队列中。
(3)第 2)步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。
fetch 阶段的目的:取数据。
路由节点获取所有文档,返回给客户端。
7、Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法
面试官:想了解对 ES 集群的运维能力。
解答:
(1)关闭缓存 swap;
(2)堆内存设置为:Min(节点内存/2, 32GB);
(3)设置最大文件句柄数;
(4)线程池+队列大小根据业务需要做调整;
(5)磁盘存储 raid 方式——存储有条件使用 RAID10,增加单节点性能以及避免单节点存储故障。
加粗样式8、lucence 内部结构是什么?
面试官:想了解你的知识面的广度和深度。
解答:
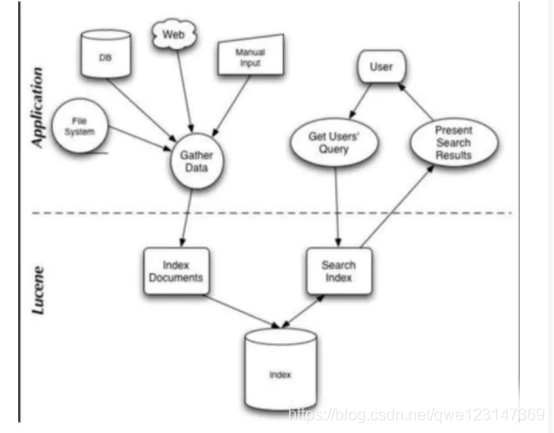 Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。可以基于这个脉络展开一些。
Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。可以基于这个脉络展开一些。
9、Elasticsearch 是如何实现 Master 选举的?
(1)Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个 RPC 来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
(2)对所有可以成为 master 的节点(node.master: true)根据 nodeId 字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第 0 位)节点,暂且认为它是 master 节点。
(3)如果对某个节点的投票数达到一定的值(可以成为 master 节点数 n/2+1)并且该节点自己也选举自己,那这个节点就是 master。否则重新选举一直到满足上述条件。
(4)补充:master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能*。
**10、Elasticsearch 中的节点(比如共 20 个),其中的 10 个
选了一个 master,另外 10 个选了另一个 master,怎么办?**
(1)当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
(3)当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data节点,避免脑裂问题。
11、客户端在和集群连接时,如何选择特定的节点执行请求的?
TransportClient 利用 transport 模块远程连接一个 elasticsearch 集群。它并不加入到集群中,只是简单的获得一个或者多个初始化的 transport 地址,并以 轮询 的方式与这些地址进行通信。
12、详细描述一下 Elasticsearch 索引文档的过程。
协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片。
shard = hash(document_id) % (num_of_primary_shards)
(1)当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 MemoryBuffer,然后定时(默认是每隔 1 秒)写入到 Filesystem Cache,这个从 MomeryBuffer 到 Filesystem Cache 的过程就叫做 refresh;
(2)当然在某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中 ,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
(3)在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
(4)flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时;
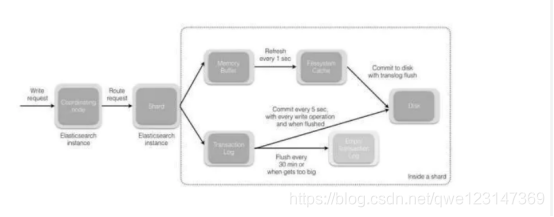
补充:关于 Lucene 的 Segement:
(1)Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
(2)段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
(3)对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
(4)为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。
13、详细描述一下 Elasticsearch 更新和删除文档的过程。
(1)删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;
(2)磁盘上的每个段都有一个相应的.del 文件。当删除请求发送后,文档并没有真的被删除,而是在.del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del 文件中被标记为删除的文档将不会被写入新段。
(3)在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
14、详细描述一下 Elasticsearch 搜索的过程。
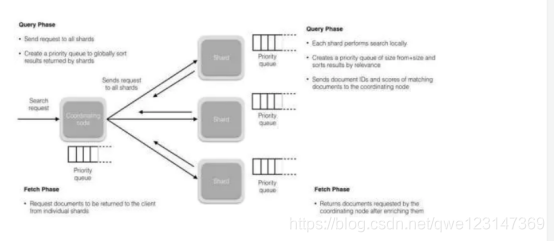
(1)搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
(2)在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。
PS:在搜索的时候是会查询 Filesystem Cache 的,但是有部分数据还在 MemoryBuffer,所以搜索是近实时的。
(3)每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
(4)接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰 富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
(5)补充:Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。*
15、在 Elasticsearch 中,是怎么根据一个词找到对应的倒排索引的?
(1)Lucene的索引过程,就是按照全文检索的基本过程,将倒排表写成此文件格式的过程。
(2)Lucene的搜索过程,就是按照此文件格式将索引进去的信息读出来,然后计算每篇文档打分(score)的过程。
16、Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法?
(1)64 GB 内存的机器是非常理想的, 但是 32 GB 和 16 GB 机器也是很常见的。少于 8 GB 会适得其反。
(2)如果你要在更快的 CPUs 和更多的核心之间选择,选择更多的核心更好。多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
(3)如果你负担得起 SSD,它将远远超出任何旋转介质。 基于 SSD 的节点,查询和索引性能都有提升。如果你负担得起,SSD 是一个好的选择。
(4)即使数据中心们近在咫尺,也要避免集群跨越多个数据中心。绝对要避免集群跨越大的地理距离。
(5)请确保运行你应用程序的 JVM 和服务器的 JVM 是完全一样的。 在Elasticsearch 的几个地方,使用 Java 的本地序列化。
(6)通过设置 gateway.recover_after_nodes、gateway.expected_nodes、gateway.recover_after_time 可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数个小时缩短为几秒钟。
(7)Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。最好使用单播代替组播。
(8)不要随意修改垃圾回收器(CMS)和各个线程池的大小。
(9)把你的内存的(少于)一半给 Lucene(但不要超过 32 GB!),通过ES_HEAP_SIZE 环境变量设置。
(10)内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个100 微秒的操作可能变成 10 毫秒。 再想想那么多 10 微秒的操作时延累加起来。 不难看出 swapping 对于性能是多么可怕。
(11)Lucene 使用了大 量 的文件。同时,Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字。 所有这一切都需要足够的文件描述符。你应该增加你的文件描述符,设置一个很大的值,如 64,000。
补充:索引阶段性能提升方法
(1)使用批量请求并调整其大小:每次批量数据 5–15 MB 大是个不错的起始点。
(2)存储:使用 SSD
最后希望可以帮助到大家!
千千万万要记得:多刷题!!多刷题!!
之前算法是我的硬伤,后面硬啃了好长一段时间才补回来,算法才是程序员的灵魂!!!!
篇幅有限,以下只能截图分享部分的资源!!
(1)多线程(这里以多线程为代表,其实整理了一本JAVA核心架构笔记集)

(2)刷的算法题(还有左神的算法笔记)

(3)面经+真题解析+对应的相关笔记(很全面)

(4)视频学习(部分)
ps:当你觉得学不进或者累了的时候,视频是个不错的选择
在这里,最后只一句话:祝大家offer拿到手软!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
存中…(img-WO606F1g-1713054246563)]
(4)视频学习(部分)
ps:当你觉得学不进或者累了的时候,视频是个不错的选择
在这里,最后只一句话:祝大家offer拿到手软!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-QZkm4Is3-1713054246563)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


