
- 1Python实现Word、Excel、PPT批量转为PDF_小程序word excel转pdf功能的实现
- 2推荐5个AI辅助生成论文、降低查重率的网站【2024最新】
- 3昇思MindSpore 25天学习打卡营|day1
- 4本地虚拟机Centos7使用Ollama运行llama3中文模型和OpenWebUI访问_ollama中文ui
- 5如何使用ffmpeg高效的压缩视频_ffmpeg 压缩
- 6Java开发实习面试复盘(亚信科技)_亚信考试java开发实习生
- 7华为仓颉可以取代 Java 吗?_仓颉和java的关联和区别
- 8DS-007 顺序表-寻找两个序列的中位数_找出序列a,b的中位数java
- 910款国内可用的AI工具分享,每一款都能让你工作效率翻倍_魔术todo任务分解
- 10Python的23种设计模式_python 23种设计模式
ai+模型选择+过拟合和欠拟合_ai生成数据集,过拟合
赞
踩
1模型选择
1训练误差和泛化误差

训练误差(Training Error)和泛化误差(Generalization Error)是机器学习中两个关键的性能度量,它们分别描述了模型在训练数据和新数据上的表现。以下是它们的定义和关系:
-
训练误差(Training Error):
- 训练误差是模型在训练数据集上的性能度量。通常使用损失函数来衡量模型在训练数据上的拟合程度,即模型对于训练样本的预测与实际标签之间的差异。
- 训练误差越低,表示模型在训练数据上的拟合越好。然而,仅仅关注降低训练误差并不足以确保模型对未见过的数据也能良好地泛化。
-
泛化误差(Generalization Error):
- 泛化误差是模型在新、未见过的数据上的性能度量。它表示模型对于不包含在训练数据中的样本的预测能力。
- 模型的目标是在降低训练误差的同时,确保泛化误差也保持较低水平。过度拟合训练数据可能导致较低的训练误差,但在新数据上的表现可能不佳。
-
训练误差与泛化误差的关系:
- 在理想情况下,训练误差和泛化误差应该趋于相等,即模型能够在训练数据上学到数据的真实模式,从而在新数据上也表现良好。
- 当训练误差远远低于泛化误差时,可能存在过拟合问题。这表示模型过度适应了训练数据中的噪声和细微差异,而无法泛化到新数据。
- 监控训练误差和验证(或测试)误差,了解它们之间的差异,有助于判断模型是否过拟合或欠拟合,以及进行相应的调整。
为了降低泛化误差,可以使用正则化技术、交叉验证、验证集的使用以及更复杂的模型选择等方法。综合考虑训练误差和泛化误差,有助于构建更健壮、泛化能力更强的机器学习模型。
更关注泛化误差。
2验证数据集和测试数据集

训练集测试超参数的好坏,是个错误的做法,他只能用一次,不能用来验证模型。
在机器学习中,典型的数据集划分包括训练集、验证集和测试集。这三者各自的角色如下:
-
训练集(Training Set):
- 用于训练模型的数据集。模型使用训练集来学习特征、权重和模型的参数。通过反向传播和优化算法,模型试图最小化在训练集上的损失函数,从而提高对训练数据的拟合程度。
-
验证集(Validation Set):
- 用于选择模型超参数(如学习率、正则化项等)的数据集。在模型训练的过程中,使用验证集来评估模型的性能,并根据性能调整超参数。这有助于防止模型在训练数据上过度拟合,提高对未见过的数据的泛化性能。
-
测试集(Test Set):
- 用于评估最终模型性能的数据集。测试集是模型未见过的数据,因此用于评估模型在真实场景中的泛化能力。测试集的结果提供了对模型在实际应用中的性能的估计。
通常,数据集的划分比例可能是70-80%的训练集,10-15%的验证集,和10-15%的测试集。这些比例是常见的规则,但在特定情况下可能需要调整。
这样的划分方式有助于确保模型不仅在训练数据上表现良好,而且能够泛化到未见过的数据。在训练过程中,通过观察在验证集上的性能,可以调整模型的超参数,以提高模型的整体性能。最终,使用测试集来评估模型在真实应用中的表现。
3k-折交叉验证

似乎有一些误解,通常我们说的是k-折交叉验证(k-fold cross-validation),而不是"k-则"交叉验证。让我来解释一下k-折交叉验证是什么。
K-折交叉验证(K-Fold Cross-Validation):
K-折交叉验证是一种模型评估方法,通常用于评估模型的性能并减少因数据划分不同而引起的差异。在K-折交叉验证中,数据集被均匀划分成K个折(或称为“fold”),然后模型在这K个子集上进行K次训练和验证。
具体步骤如下:
- 将数据集分成K个相似的大小的折。
- 对于K个折中的每一个,使用K-1个折来训练模型,然后在保留的折上评估模型。
- 重复这一过程K次,每次使用不同的验证折。
- 计算K次评估的平均性能作为模型的最终性能。
这种方法有助于确保模型在不同的数据子集上进行了训练和验证,从而更全面地评估模型的性能。它尤其对于小数据集和高方差(overfitting)的模型评估非常有用。
选择K的取值通常是一个在实践中需要平衡的问题。一般来说,K的取值在3到10之间较为常见,但具体的选择可以根据你的数据集的大小和特性来调整。
以下是一些一般性的指导原则:
-
小规模数据集: 如果你的数据集相对较小,选择较小的K值可能更合适,以确保每个折中有足够的样本用于训练和验证。在这种情况下,K可以选择为3或5。
-
大规模数据集: 对于大规模数据集,可以选择更大的K值,如10。这样每次训练模型时,都有更多的数据参与,但计算开销也会相应增加。
-
具体应用场景: 不同的应用场景可能需要不同的K值。例如,在某些竞赛中,可能会尝试使用较大的K值进行更全面的模型评估。在其他情况下,选择较小的K值可能更为合适。
-
计算资源: K的值也可能受到可用计算资源的限制。较大的K值可能需要更多的计算时间和内存。
-
数据的分布: 如果数据有明显的分布特征,比如时间序列数据,考虑到保持时间顺序的一致性,可能需要使用时间序列交叉验证而不是标准的K-折交叉验证。
最佳的K值通常需要通过实验和观察模型的性能来确定。可以尝试不同的K值,然后观察模型在验证集上的性能,选择能够提供对模型泛化性能有良好估计的K值。在实践中,一些人会通过使用交叉验证的平均性能来减轻单次划分可能引入的随机性。
4总结
- 验证数据集是用来选择模型超参数的,训练数据集是用来训练模型参数的
- 非大型数据集上通常使用k-折交叉验证
2过拟合和欠拟合
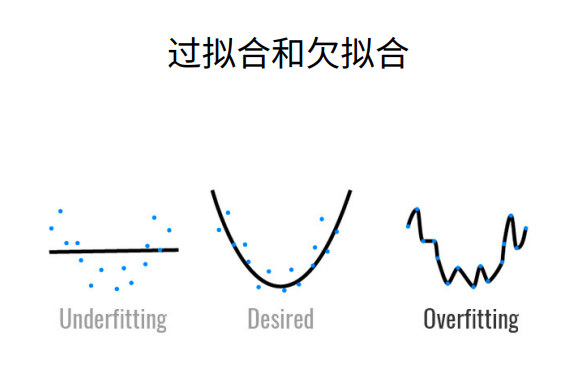

1模型容量

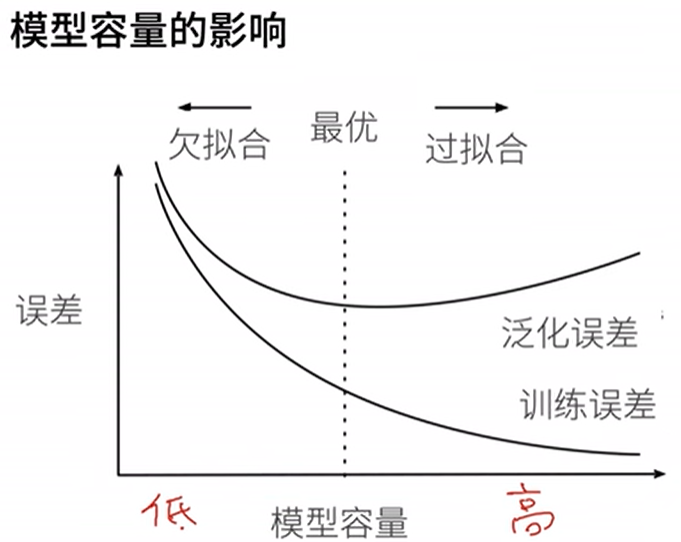
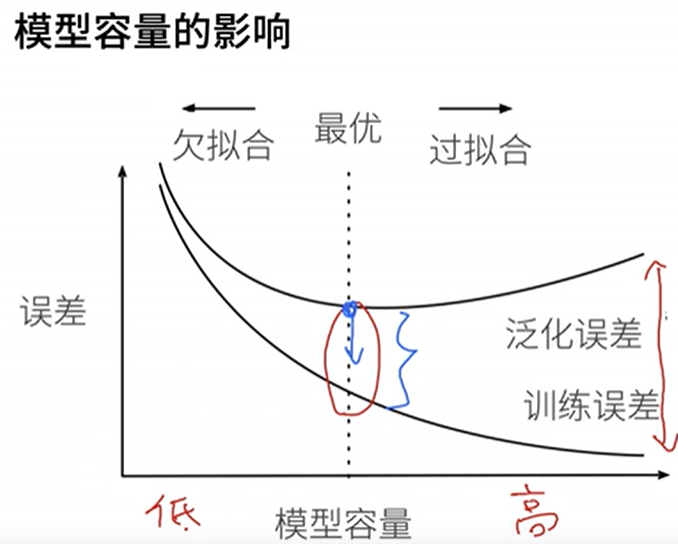
在机器学习中,模型容量(Model Capacity)通常指的是模型能够学习或逼近复杂函数的能力。一个拥有更大容量的模型可以学习更复杂的关系,但也容易过度拟合(Overfitting)训练数据。
模型的容量与模型的复杂性直接相关。以下是一些关于模型容量的重要概念:
-
低容量模型:
- 低容量的模型可能过于简单,无法很好地适应训练数据中的复杂模式。它们可能无法捕捉到数据中的细微差异或噪声。
-
高容量模型:
- 高容量的模型能够更好地适应训练数据中的复杂性,甚至可以学习到噪声。然而,如果不加以控制,高容量模型容易过度拟合,对未见过的数据表现不佳。
-
过拟合和欠拟合:
- 过拟合通常发生在高容量模型上,因为它们对训练数据过于敏感,学到了训练数据中的噪声。相反,低容量模型可能会发生欠拟合,即无法很好地适应训练数据的真实模式。
-
平衡与调整:
- 找到适当的模型容量是机器学习中的一个平衡问题。在模型的容量过大时,可以通过正则化技术或减少模型复杂度来控制过拟合。相反,如果模型容量不足,可能需要通过增加模型复杂度或使用更复杂的架构来提高性能。
-
训练数据的大小:
- 模型容量的适当选择也与训练数据的大小相关。在大规模数据集上,较大容量的模型可能更容易受益,而在小规模数据集上,可能需要限制模型容量以防止过拟合。
在实际应用中,通过交叉验证等技术,观察模型在训练集和验证集上的性能,可以帮助找到适当的模型容量。通常,建议始终尝试使用较简单的模型开始,并根据性能逐步增加复杂性,以避免过拟合。
2估计模型容量
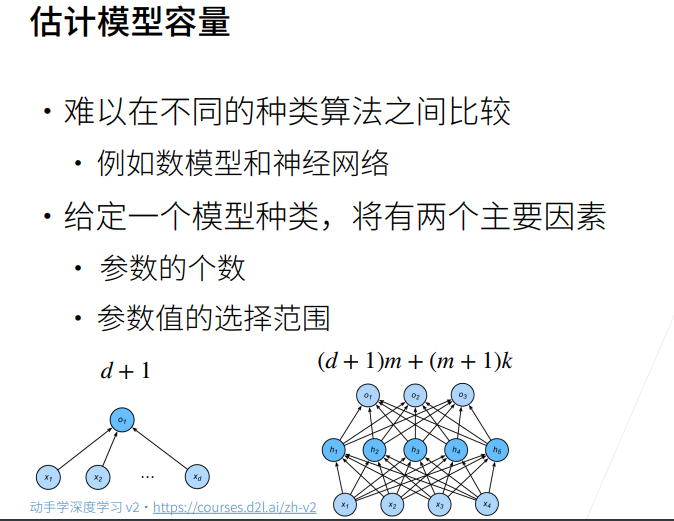
估计模型容量是一个重要的步骤,有助于找到合适的模型复杂度,避免过拟合或欠拟合。以下是一些方法来估计模型容量:
-
学习曲线(Learning Curves):
- 观察模型在训练集和验证集上的学习曲线。学习曲线可以显示随着训练数据量的增加,模型在训练集和验证集上的性能变化。如果训练误差和验证误差都很高,可能是模型容量不足。如果训练误差低而验证误差高,可能是模型容量过大导致过拟合。
-
交叉验证:
- 使用交叉验证技术,观察模型在不同训练和验证集组合上的性能。通过比较不同模型在交叉验证上的表现,可以选择适当容量的模型。
-
正则化:
- 引入正则化项来控制模型复杂度。正则化可以防止模型参数过大,从而降低模型容量。常见的正则化项包括L1正则化和L2正则化。
-
模型复杂度参数:
- 对于一些模型,有一些调整模型复杂度的超参数,例如决策树的最大深度、神经网络的隐藏层节点数等。通过调整这些参数,可以调整模型的容量。
-
特征工程:
- 仔细选择和设计特征可以间接影响模型的容量。过多或过少的特征可能导致模型容量的问题。选择合适的特征可以提高模型的泛化能力。
-
集成方法:
- 使用集成方法,如随机森林或梯度提升树。集成方法可以减小单个模型的过拟合风险,提高模型的泛化性能。
通过这些方法,你可以逐步找到合适的模型容量,确保模型在训练数据和验证数据上都能够表现出色。请注意,估计模型容量是一个迭代的过程,可能需要多次实验和调整来找到最佳的平衡点。
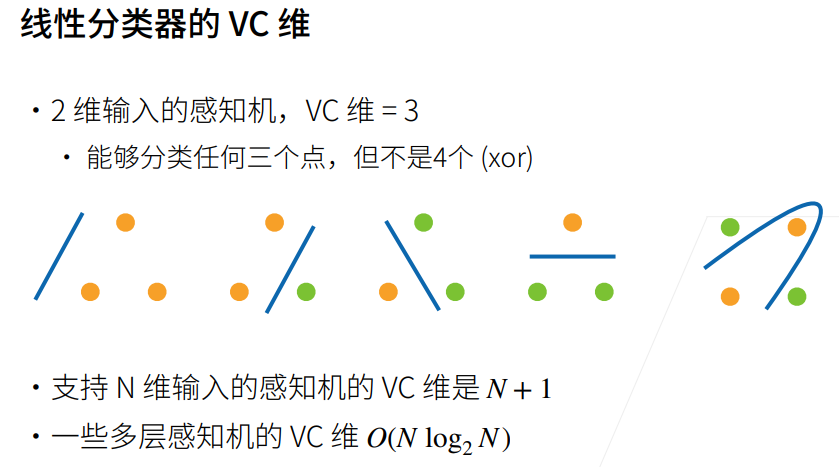
3VC维

VC维(Vapnik-Chervonenkis Dimension),通常简写为VC维,是由计算机科学家Vladimir Vapnik和Alexey Chervonenkis提出的概念,用于衡量一个假设类(hypothesis class)的表达能力或复杂性。
在机器学习中,VC维主要用于理论上研究模型的泛化性能,特别是在统计学习理论中。VC维的概念涉及到假设类能够拟合的样本集的最大大小。
具体来说,VC维是这样定义的:
-
定义:
- 一个假设类(或假设空间)的VC维是该类可以拟合的样本集的最大大小。更具体地说,是能够被该假设类分开的不同样本集的最大数量。
-
VC维的直观理解:
- 一个假设类的VC维越大,表示它越灵活,可以适应更多的样本集。换句话说,VC维反映了假设类的表达能力和复杂性。
-
VC维与泛化误差的关系:
- 在统计学习理论中,VC维与泛化误差之间存在关系。VC维较小的模型更容易泛化到未见过的数据,而VC维较大的模型可能更容易在训练数据上过拟合。
-
Rademacher复杂度:
- 在一些情况下,VC维可以用于计算模型的Rademacher复杂度,这是一种评估模型复杂性的方法,与泛化性能有关。
需要注意的是,VC维通常用于理论上的分析,对于实际问题,我们更常用交叉验证等实验性方法来评估模型的泛化性能。 VC维提供了一种对模型复杂性的理论界定,但并不总是能完全捕捉实际问题中的情况。

4数据复杂度

5总结

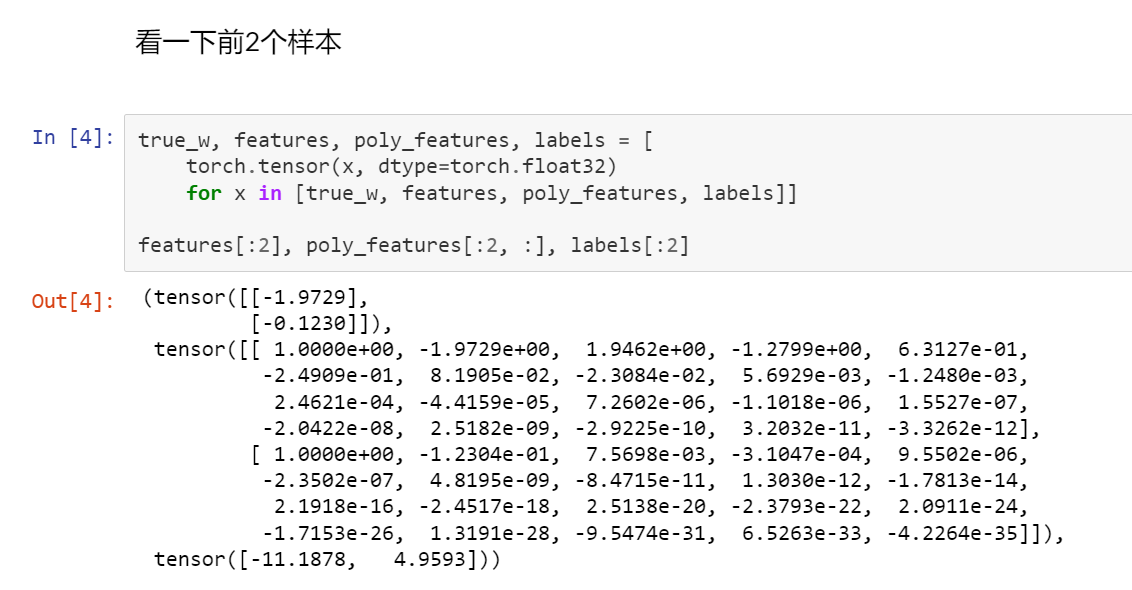
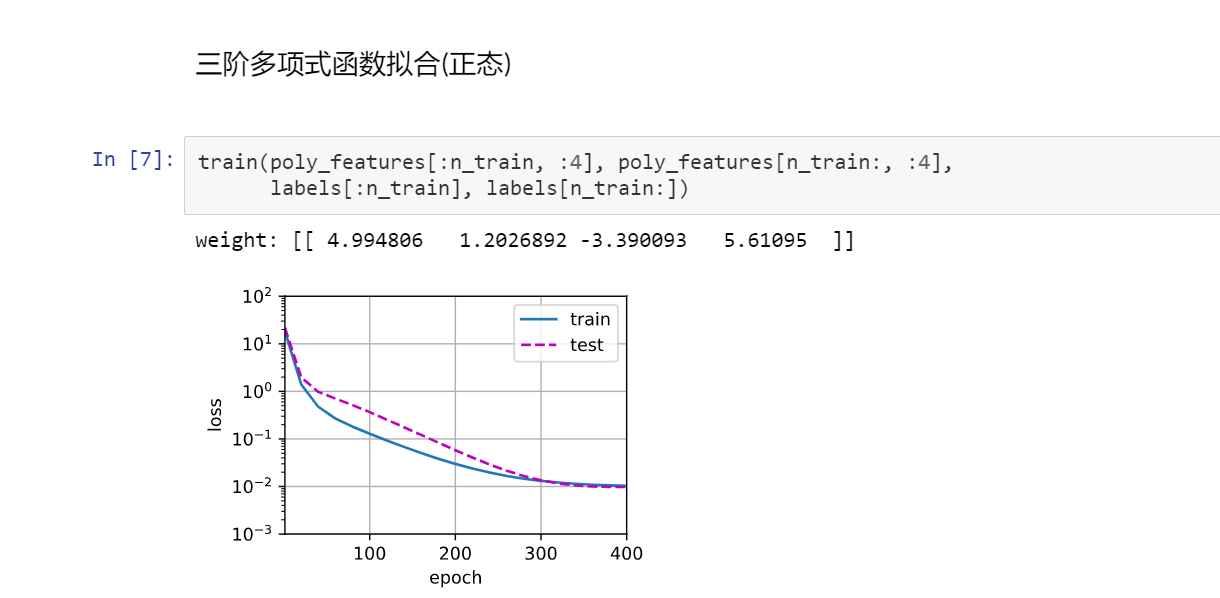
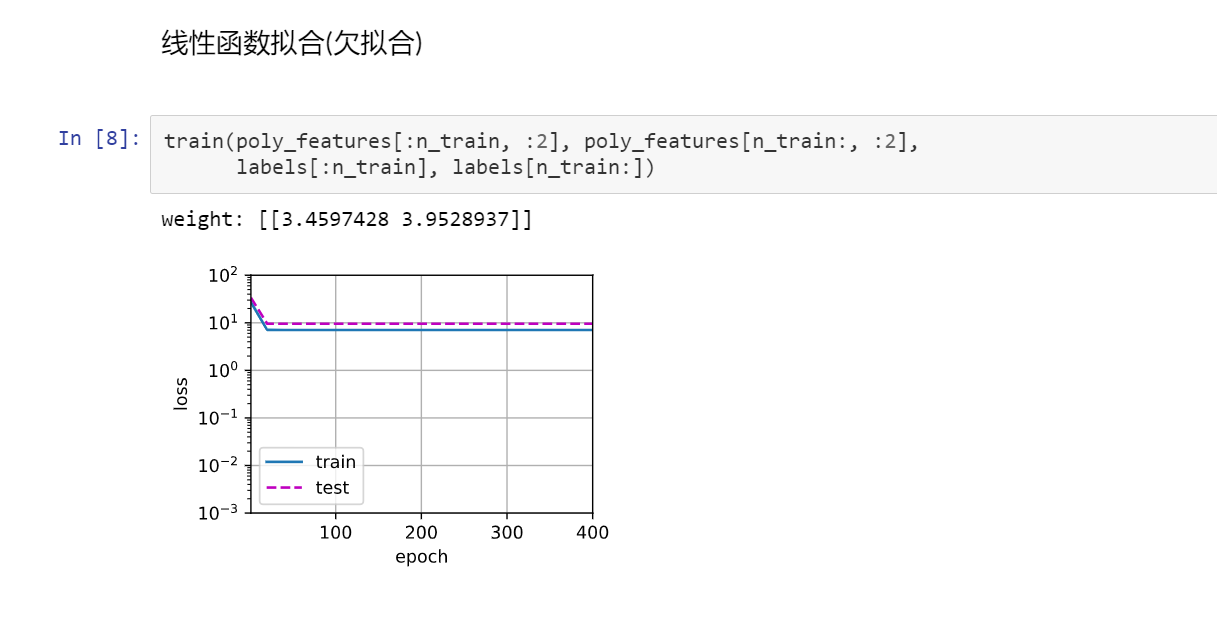
3代码



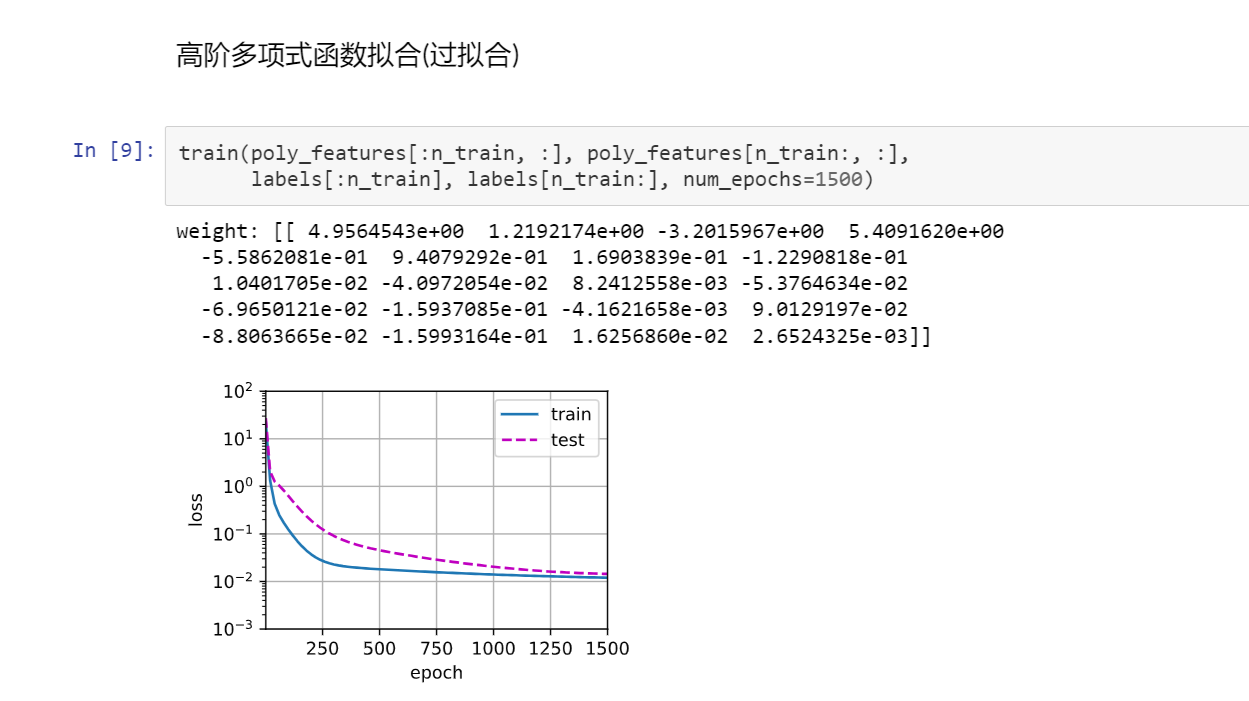

- HTML代码:[详细] -->
赞
踩

