
- 1python遍历一个文件夹下所有excel,读取所有sheet页,然后写入另一个文件夹下对应模板的excel中_用python检查excel文件中所有的sheet页
- 2React中WebSocket使用以及服务端崩溃重连_react使用ws
- 3网吧无盘系统
- 4Karpathy的33个神经网络「炼丹」技巧学习笔记_karpathy的33个神经网络炼丹技巧
- 5《TCP/IP详解》笔记——TCP/IP基本工作原理概述_tcpip的结构和基本原理
- 6Java高阶知识体系总结(一)_java知识体系
- 7Streamlit搭建聊天机器人(一)_streamlit 聊天
- 8Node.js中npm中ws的WebSocket协议的实现_nodejs ws
- 9机械制图之零件图表达_零件的表达方法有哪五种
- 10数据库系统原理----笔记整理系列_在定义外键时没有定义“on update”,则修改参照表中主键值时,依赖表的默认操作是
Spark调度系列-----5.Spark task和Stage的跳过执行(ui显示task和stage skipped)_spark skipped
赞
踩
在spark的首页ui上经常显示任务和Stage被skipped,如以下截图所式:
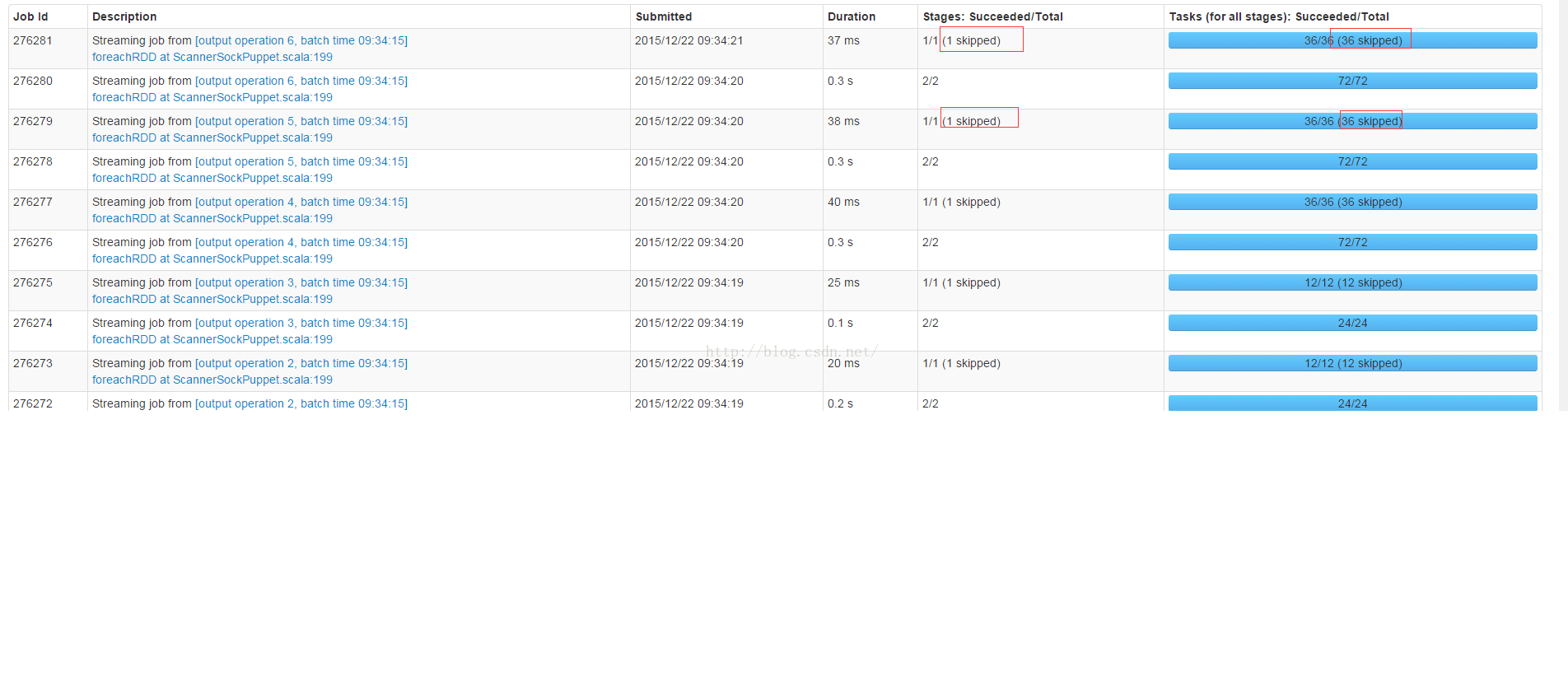
本文将阐述什么情况下Stage或者Task会显示为skipped,以及stage和task显示为skipped的时候是否spark application执行会出问题?
Spark Job的ResultStage的最后一个Task成功执行之后,DAGScheduler.handleTaskCompletion方法会发送SparkListenerJobEnd事件,源码如下:
- private[scheduler] def handleTaskCompletion(event: CompletionEvent) {
- val task = event.task
- val stageId = task.stageId
- val taskType = Utils.getFormattedClassName(task)
-
- outputCommitCoordinator.taskCompleted(stageId, task.partitionId,
- event.taskInfo.attempt, event.reason)
-
- // The success case is dealt with separately below, since we need to compute accumulator
- // updates before posting.
- if (event.reason != Success) {
- val attemptId = stageIdToStage.get(task.stageId).map(_.latestInfo.attemptId).getOrElse(-1)
- listenerBus.post(SparkListenerTaskEnd(stageId, attemptId, taskType, event.reason,
- event.taskInfo, event.taskMetrics))
- }
-
- if (!stageIdToStage.contains(task.stageId)) {
- // Skip all the actions if the stage has been cancelled.
- return
- }
-
- val stage = stageIdToStage(task.stageId)
- event.reason match {
- case Success =>
- listenerBus.post(SparkListenerTaskEnd(stageId, stage.latestInfo.attemptId, taskType,
- event.reason, event.taskInfo, event.taskMetrics))
- stage.pendingTasks -= task
- task match {
- case rt: ResultTask[_, _] =>
- // Cast to ResultStage here because it's part of the ResultTask
- // TODO Refactor this out to a function that accepts a ResultStage
- val resultStage = stage.asInstanceOf[ResultStage]
- resultStage.resultOfJob match {
- case Some(job) =>
- if (!job.finished(rt.outputId)) {
- updateAccumulators(event)
- job.finished(rt.outputId) = true
- job.numFinished += 1
- // If the whole job has finished, remove it
- if (job.numFinished == job.numPartitions) {//ResultStage所有任务都执行完毕,发送SparkListenerJobEnd事件
- markStageAsFinished(resultStage)
- cleanupStateForJobAndIndependentStages(job)
- listenerBus.post(
- SparkListenerJobEnd(job.jobId, clock.getTimeMillis(), JobSucceeded))
- }
-
- // taskSucceeded runs some user code that might throw an exception. Make sure
- // we are resilient against that.
- try {
- job.listener.taskSucceeded(rt.outputId, event.result)
- } catch {
- case e: Exception =>
- // TODO: Perhaps we want to mark the resultStage as failed?
- job.listener.jobFailed(new SparkDriverExecutionException(e))
- }
- }
- case None =>
- logInfo("Ignoring result from " + rt + " because its job has finished")
- }

JobProgressListener.onJobEnd方法负责处理SparkListenerJobEnd事件,代码如下:
- override def onJobEnd(jobEnd: SparkListenerJobEnd): Unit = synchronized {
- val jobData = activeJobs.remove(jobEnd.jobId).getOrElse {
- logWarning(s"Job completed for unknown job ${jobEnd.jobId}")
- new JobUIData(jobId = jobEnd.jobId)
- }
- jobData.completionTime = Option(jobEnd.time).filter(_ >= 0)
-
- jobData.stageIds.foreach(pendingStages.remove)
- jobEnd.jobResult match {
- case JobSucceeded =>
- completedJobs += jobData
- trimJobsIfNecessary(completedJobs)
- jobData.status = JobExecutionStatus.SUCCEEDED
- numCompletedJobs += 1
- case JobFailed(exception) =>
- failedJobs += jobData
- trimJobsIfNecessary(failedJobs)
- jobData.status = JobExecutionStatus.FAILED
- numFailedJobs += 1
- }
- for (stageId <- jobData.stageIds) {
- stageIdToActiveJobIds.get(stageId).foreach { jobsUsingStage =>
- jobsUsingStage.remove(jobEnd.jobId)
- if (jobsUsingStage.isEmpty) {
- stageIdToActiveJobIds.remove(stageId)
- }
- stageIdToInfo.get(stageId).foreach { stageInfo =>
- if (stageInfo.submissionTime.isEmpty) {//Job的Stage没有提交执行,则这个Stage和它对应的Task会标记为skipped stage和skipped task进行统计
- // if this stage is pending, it won't complete, so mark it as "skipped":
- skippedStages += stageInfo
- trimStagesIfNecessary(skippedStages)
- jobData.numSkippedStages += 1
- jobData.numSkippedTasks += stageInfo.numTasks
- }
- }
- }
- }
- }
StageInfo.submissionTime在Stage被分解成TaskSet,并且TaskSet被提交到TaskSetManager之前进行设置,源码如下:
- private def submitMissingTasks(stage: Stage, jobId: Int) {
- logDebug("submitMissingTasks(" + stage + ")")
- // Get our pending tasks and remember them in our pendingTasks entry
- stage.pendingTasks.clear()
-
-
- // First figure out the indexes of partition ids to compute.
- //parititionsToCompute是一个List, 表示一个stage需要compute的所有分区的index
- val partitionsToCompute: Seq[Int] = {
- stage match {
- case stage: ShuffleMapStage =>
- (0 until stage.numPartitions).filter(id => stage.outputLocs(id).isEmpty)
- case stage: ResultStage =>
- val job = stage.resultOfJob.get
- (0 until job.numPartitions).filter(id => !job.finished(id))
- }
- }
-
- val properties = jobIdToActiveJob.get(stage.firstJobId).map(_.properties).orNull
-
- runningStages += stage
- // SparkListenerStageSubmitted should be posted before testing whether tasks are
- // serializable. If tasks are not serializable, a SparkListenerStageCompleted event
- // will be posted, which should always come after a corresponding SparkListenerStageSubmitted
- // event.
- stage.latestInfo = StageInfo.fromStage(stage, Some(partitionsToCompute.size))
- outputCommitCoordinator.stageStart(stage.id)
- listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
-
- // TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.
- // Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast
- // the serialized copy of the RDD and for each task we will deserialize it, which means each
- // task gets a different copy of the RDD. This provides stronger isolation between tasks that
- // might modify state of objects referenced in their closures. This is necessary in Hadoop
- // where the JobConf/Configuration object is not thread-safe.
- var taskBinary: Broadcast[Array[Byte]] = null
- try {
- // For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
- // For ResultTask, serialize and broadcast (rdd, func).
- val taskBinaryBytes: Array[Byte] = stage match {
- case stage: ShuffleMapStage =>
- closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array()
- case stage: ResultStage =>
- closureSerializer.serialize((stage.rdd, stage.resultOfJob.get.func): AnyRef).array()
- }
-
- taskBinary = sc.broadcast(taskBinaryBytes)//将任务信息构造成广播变量,广播到每个Executor
- } catch {
- // In the case of a failure during serialization, abort the stage.
- case e: NotSerializableException =>
- abortStage(stage, "Task not serializable: " + e.toString)
- runningStages -= stage
-
- // Abort execution
- return
- case NonFatal(e) =>
- abortStage(stage, s"Task serialization failed: $e\n${e.getStackTraceString}")
- runningStages -= stage
- return
- }
- //tasks是一个List,它表示一个stage每个task的描述,描述信息为:task所在stage id、task处理的partition、partition所在的主机地址和Executor id
- val tasks: Seq[Task[_]] = try {
- stage match {
- case stage: ShuffleMapStage =>
- partitionsToCompute.map { id =>
- /*
- * 获取task所在的节点,数据所在的节点优先启动任务处理这些数据,在这里用到ShuffleMapStage.
- * */
- val locs = getPreferredLocs(stage.rdd, id)
- val part = stage.rdd.partitions(id)
- new ShuffleMapTask(stage.id, taskBinary, part, locs)//taskBinary是广播变量
- }
-
- case stage: ResultStage =>
- val job = stage.resultOfJob.get
- partitionsToCompute.map { id =>
- val p: Int = job.partitions(id)
- val part = stage.rdd.partitions(p)
- val locs = getPreferredLocs(stage.rdd, p)
- new ResultTask(stage.id, taskBinary, part, locs, id)
- }
- }
- } catch {
- case NonFatal(e) =>
- abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}")
- runningStages -= stage
- return
- }
-
- if (tasks.size > 0) {
- logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
- stage.pendingTasks ++= tasks
- logDebug("New pending tasks: " + stage.pendingTasks)
- taskScheduler.submitTasks(
- new TaskSet(tasks.toArray, stage.id, stage.newAttemptId(), stage.firstJobId, properties))
- stage.latestInfo.submissionTime = Some(clock.getTimeMillis())//设置StageInfo的submissionTime成员,表示这个TaskSet会被执行,不会被skipped
- } else
Job的Stage没有分解成TaskSet提交执行,则这个Stage和它对应的Task会标记为skipped stage和skipped task进行统计显示。
那种Stage不会分解成TaskSet分解执行呢?
Spark在提交Job的时候,会发送JobSubmitted事件,DAGScheduler.doOnReceive接收到JobSubmitted事件之后,会调用DAGScheduler.handleJobSubmitted方法处理任务提交。
DAGScheduler.handleJobSubmitted首先调用DAGScheduler.newResultStage方法创建最后一个Stage,DAGScheduler.newResultStage通过以下一系列函数调用最终会调用到DAGScheduler.registerShuffleDependencies,这个方法将这个RDD所有的祖宗Stage加入到DAGScheduler.jobIdToStageIds这个HashMap中。然后获取这个Job的每个Stage对应的StageInfo,转换成一个Seq,发送SparkListenerJobStart事件。
DAGScheduler.newResultStage->
DAGScheduler.getParentStagesAndId->
DAGScheduler.getParentStagesAndId->getParentStages
DAGScheduler.getParentStagesAndId->getShuffleMapStage
DAGScheduler.registerShuffleDependencies
DAGScheduler.registerShuffleDependencies首先调用DAGScheduler.getAncestorShuffleDependencies找到当前rdd所有祖宗的rdd依赖,包括父辈、爷爷辈,以致更高辈分的rdd依赖,然后调用DAGScheduler.newOrUsedShuffleStage创建每个祖宗rdd依赖对应的ShuffleMapStage,
- private def registerShuffleDependencies(shuffleDep: ShuffleDependency[_, _, _], firstJobId: Int) {
- val parentsWithNoMapStage = getAncestorShuffleDependencies(shuffleDep.rdd)//获取所有祖宗rdd依赖,包括父辈、爷爷辈等
- while (parentsWithNoMapStage.nonEmpty) {
- val currentShufDep = parentsWithNoMapStage.pop()
- //根据ShuffleDependency和jobid生成Stage,由于是从栈里面弹出,所以最先添加的是Root stage,依次类推,最先添加的Stage shuffleId越小
- val stage = newOrUsedShuffleStage(currentShufDep, firstJobId)
- shuffleToMapStage(currentShufDep.shuffleId) = stage
- }
- }
- private def newOrUsedShuffleStage(
- shuffleDep: ShuffleDependency[_, _, _],
- firstJobId: Int): ShuffleMapStage = {
- val rdd = shuffleDep.rdd
- val numTasks = rdd.partitions.size
- val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)//创建stage
- if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
- val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
- val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
- for (i <- 0 until locs.size) {
- stage.outputLocs(i) = Option(locs(i)).toList // locs(i) will be null if missing
- }
- stage.numAvailableOutputs = locs.count(_ != null)
- } else {
- // Kind of ugly: need to register RDDs with the cache and map output tracker here
- // since we can't do it in the RDD constructor because # of partitions is unknown
- logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
- mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.size)
- }
- stage
- }
DAGScheduler.newOrUsedShuffleStage会调用DAGScheduler.newShuffleMapStage创建stage。
DAGScheduler.newShuffleMapStage方法创建了stage之后,调用DAGScheduler.updateJobIdStageIdMaps方法将新创建的stage.id加入到DAGScheduler.jobIdToStageIds中。源码如下:
- private def updateJobIdStageIdMaps(jobId: Int, stage: Stage): Unit = {
- def updateJobIdStageIdMapsList(stages: List[Stage]) {
- if (stages.nonEmpty) {
- val s = stages.head
- s.jobIds += jobId
- jobIdToStageIds.getOrElseUpdate(jobId, new HashSet[Int]()) += s.id//将stage id加入到jobIdToStageIds中
- val parents: List[Stage] = getParentStages(s.rdd, jobId)
- val parentsWithoutThisJobId = parents.filter { ! _.jobIds.contains(jobId) }
- updateJobIdStageIdMapsList(parentsWithoutThisJobId ++ stages.tail)
- }
- }
- updateJobIdStageIdMapsList(List(stage))
- }
DAGScheduler.handleJobSubmitted源码如下:
- private[scheduler] def handleJobSubmitted(jobId: Int,
- finalRDD: RDD[_],
- func: (TaskContext, Iterator[_]) => _,
- partitions: Array[Int],
- allowLocal: Boolean,
- callSite: CallSite,
- listener: JobListener,
- properties: Properties) {
- var finalStage: ResultStage = null
- try {
- // New stage creation may throw an exception if, for example, jobs are run on a
- // HadoopRDD whose underlying HDFS files have been deleted.
- finalStage = newResultStage(finalRDD, partitions.size, jobId, callSite)//创建ResultStage,在这个方法里面会将这个Job执行过程中,需要可能经历的Stage全部放入到
- } catch {
- case e: Exception =>
- logWarning("Creating new stage failed due to exception - job: " + jobId, e)
- listener.jobFailed(e)
- return
- }
- if (finalStage != null) {
- val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties)
- clearCacheLocs()
- logInfo("Got job %s (%s) with %d output partitions (allowLocal=%s)".format(
- job.jobId, callSite.shortForm, partitions.length, allowLocal))
- logInfo("Final stage: " + finalStage + "(" + finalStage.name + ")")
- logInfo("Parents of final stage: " + finalStage.parents)
- logInfo("Missing parents: " + getMissingParentStages(finalStage))
- val shouldRunLocally =
- localExecutionEnabled && allowLocal && finalStage.parents.isEmpty && partitions.length == 1
- val jobSubmissionTime = clock.getTimeMillis()
- if (shouldRunLocally) {
- // Compute very short actions like first() or take() with no parent stages locally.
- listenerBus.post(
- SparkListenerJobStart(job.jobId, jobSubmissionTime, Seq.empty, properties))
- runLocally(job)
- } else {
- jobIdToActiveJob(jobId) = job
- activeJobs += job
- finalStage.resultOfJob = Some(job)
- val stageIds = jobIdToStageIds(jobId).toArray//获取一个Job对应的所有的Stage id,Job的所有Stage在执行newResultStage的时候会创建,所以在这里能获取成功
- val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))//获取每个Stage对应的StageInfo
- listenerBus.post(
- SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))//发送Job启动事件SparkListenerJobStart
- submitStage(finalStage)
- }
- }
- submitWaitingStages()
- }
JobProgressListener.onJobStart负责接收处理SparkListenerJobStart事件。它会把 DAGScheduler.handleJobSubmitted方法创建的所有StageInfo信息放到JobProgressListener.stageIdToInfo这个HashMap中。
至此可以得出结论:JobProgressListener.onJobEnd方法中,处理的obProgressListener.stageIdToInfo信息是执行DAGScheduler.handleJobSubmitted产生的。在Job对应的所有Stage分解成Task之前就已经产生了。
根据本人的
Spark storage系列------3.Spark cache数据块之后对后继Job任务调度的影响,以及后继Job Task执行的影响
文章可以知道,在将Stage分解成TaskSet的时候,如果一个RDD已经Cache到了BlockManager,则这个RDD对应的所有祖宗Stage都不会分解成TaskSet进行执行,所以这些祖宗Stage对应的StageInfo.submissionTime.isEmpty就会返回true,所以这些祖宗Stage和它们对应的Task就会在Spark ui上显示为skipped
Stage执行完成之后,会执行JobProgressListener.onStageCompleted将Stage信息保存到JobProgressListener.stageIdToInfo,源码如下:
- override def onStageCompleted(stageCompleted: SparkListenerStageCompleted): Unit = synchronized {
- val stage = stageCompleted.stageInfo
- stageIdToInfo(stage.stageId) = stage//保存Stage的信息,便于跟踪显示
- val stageData = stageIdToData.getOrElseUpdate((stage.stageId, stage.attemptId), {
- logWarning("Stage completed for unknown stage " + stage.stageId)
- new StageUIData
- })
Stage对应的TaskSet中所有任务成功执行后,会将Stage对应的StageInfo反馈到JobProgressListener.stageIdToInfo,这样这些任务就不会显示为skipped了

