
- 1【SQL知识】SQL中的join操作总结:内连接、外连接(左右全)
- 2肿瘤HRR和HRD 简单记录_jshrd
- 3必须要掌握的【Hbase Shell】_create 'scores2',{name=>'course',versions=>3},{nam
- 4学习Python比较好的书籍推荐_自学python推荐书
- 5年报情感分析词表
- 6Lambda表达式_lamda表达式 java 强类型
- 7没有 4K 和新处理器,任天堂的新 Switch 为什么还能吸引圈外玩家买单?
- 8Kafka vs RocketMQ—— Topic数量对单机性能的影响-转自阿里中间件_kafka topic数量不会影响性能
- 9Kafka架构介绍_kafka有主从吗
- 10Spark - 一文搞懂 Partitioner_spark partitioner
Elasticsearch(Es搜索(简单使用、全文查询、复合查询)、地理位置查询、特殊查询、聚合操作、桶聚合、管道聚合)_es search
赞
踩
Elasticsearch(三)——Es搜索(简单使用、全文查询、复合查询)、地理位置查询、特殊查询、聚合操作、桶聚合、管道聚合
一、Es搜索
这里的 Es 数据博主自己上网找的,为了练习 Es 搜索。
1、Elasticsearch 搜索入门
搜索分为两个过程:
- 当向索引中保存文档时,默认情况下,es 会保存两份内容,一份是 _source 中的数据,另一份则是通过分词、排序等一系列过程生成的倒排索引文件,倒排索引中保存了词项和文档之间的对应关系。
- 搜索时,当 es 接收到用户的搜索请求之后,就会去倒排索引中查询,通过的倒排索引中维护的倒排记录表找到关键词对应的文档集合,然后对文档进行评分、排序、高亮等处理,处理完成后返回文档。
2、简单搜索
a、match_all——查询所有
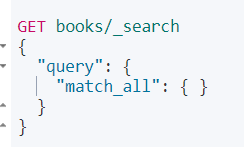
简写:
结果:

因为没有设置查询条件,所有最大的得分是 1.0。
这里并没有把所有的数据都展示出来,因为默认是有分页功能的。
b、词项查询
即 term 查询,就是根据词去查询,查询指定字段中包含给定单词的文档,term 查询不被解析,只有搜索的词和文档中的词精确匹配,才会返回文档。应用场景如:人名、地名等等。
查询包含化学的:

结果:

这里是按照查询出来的分数从高到低排序。最上面是得分最高的,也就是匹配度最高的。
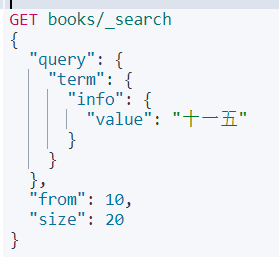
c、分页
默认返回前 10 条数据,es 中也可以像关系型数据库一样,给一个分页参数:
from:从第几条开始。
size:多少条数据。
d、过滤返回字段
如果返回的字段比较多,又不需要这么多字段,此时可以指定返回的字段:
这里指定返回 name 字段:

效果:

e、最小评分
有的文档得分特别低,说明这个文档和我们查询的关键字相关度很低。我们可以设置一个最低分,只有得分超过最低分的文档才会被返回。
最低分要高于 1.78 :

结果:

f、高亮
查询关键字高亮:

3、Es 全文查询
a、match query
match query 会对查询语句进行分词,分词后,如果查询语句中的任何一个词项被匹配,则文档就会被索引到。
前面都是输入词进行查询,这里可以输入一句话来查询了:

效果:

这里是传一句话进去,只要能有一个词能匹配,这条记录就算是相关记录会返回来。
如果想要两个词都包含,那么可以使用 operator 的 and (默认是 or):

b、match_phrase query
match_phrase query 也会对查询的关键字进行分词,但是它分词后有两个特点:
- 分词后的词项顺序必须和文档中词项的顺序一致
- 所有的词都必须出现在文档中
示例如下:

结果:
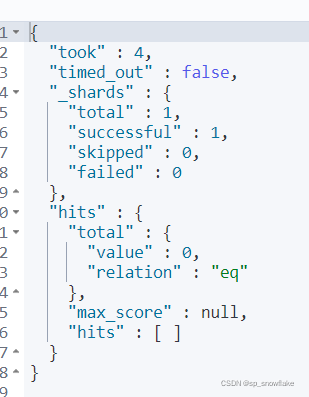
结果是什么都没有搜到。
因为这两个词分词之后是挨着的。但现在想要查询十一五和计算机这两个词不要挨在一起,中间可以隔着其他东西。所以这里可以通过 slop 配置中间可以隔多少字符:

效果:

query 是查询的关键字,会被分词器进行分解,分解之后去倒排索引中进行匹配。
slop 是指关键字之间的最小距离,但是注意不是关键之间间隔的字数。文档中的字段被分词器解析之后,解析出来的词项都包含一个 position 字段表示词项的位置,查询短语分词之后 的 position 之间的间隔要满足 slop 的要求。
c、match_phrase_prefix query(效率低,了解即可)
这个类似于 match_phrase query,只不过这里多了一个通配符,match_phrase_prefix 支持最后一个词项的前缀匹配,但是由于这种匹配方式效率较低,因此大家作为了解即可。

这个查询过程,会自动进行单词匹配,会自动查找以计开始的单词,默认是 50 个,可以自己控制:

match_phrase_prefix 是针对分片级别的查询,假设 max_expansions 为 1,可能返回多个文档,但是只有一个词,这是我们预期的结果。有的时候实际返回结果和我们预期结果并不一致,原因在于这个查询是分片级别的,不同的分片确实只返回了一个词,但是结果可能来自不同的分片,所以最终会看到多个词。
d、multi_match query
match 查询的升级版,可以指定多个查询域(意思就是查询多个字段):

效果:

这种查询方式还可以指定字段的权重:
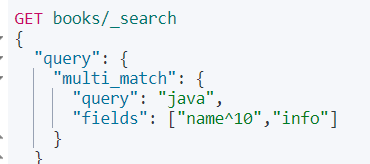
意思就是更在意 name 中是否有 java ;加到其他字段也就是更在意哪些字段有 java。
结果:
e、query_string query
query_string 是一种紧密结合 Lucene 的查询方式,在一个查询语句中可以用到 Lucene 的一些查询语法:

f、simple_query_string
这个是 query_string 的升级,可以直接使用 +、|、- 代替 AND、OR、NOT 等。

g、term query
词项查询。词项查询不会分析查询字符,直接拿查询字符去倒排索引中比对。

h、terms query
词项查询,但是可以给多个关键词。

i、range query
范围查询,可以按照日期范围、数字范围等查询。
range query 中的参数主要有四个:
- gt
- lt
- gte
- lte
查询价格大于等于 10,小于等于 20 的书:

效果:

因为都在价格范围内,没有说谁分高分低。
根据价格排序:

效果:

j、exists query
exists query 会返回指定字段中至少有一个非空值的文档:

注意,空字符串也是有值。null 是空值。
k、prefix query
前缀查询,效率略低,除非必要,一般不太建议使用。
给定关键词的前缀去查询:

l、wildcard query
wildcard query 即通配符查询。支持单字符和多字符通配符:
- ? 表示一个任意字符。
- * 表示零个或者多个字符。

