
热门标签
热门文章
- 1mysql数据结构_mysql一行数据的数据结构
- 2android字符串数组定义,在Android中对字符串的数组列表进行排序
- 3微服务架构系列主题:会员服务优雅上下线实践_会员 微服务
- 4[Unity2D入门教程]简单制作仿植物大战僵尸游戏之②搭建游戏场景+制作动画_complete c# unity game developer 2d
- 5快人一步!利用LLM实现数据处理自动化
- 6应用宝shangjia安全评估报告_《安全评估报告》提交指引
- 7opencv小工具-绘制resnet50热力图和灰度图-伪彩色映射_opencv 热力图
- 8React Native项目运行与调试--安卓_怎么运行已有的react native项目
- 9Linux下root用户安装单机Hadoop+Hive_hadoop hive安装
- 10sql:常用:join、left join、right join、outer join、inner join、full join、cross join_outer join和full join
当前位置: article > 正文
IDEA中运行Scala-Spark程序_idea scala本地运行
作者:煮酒与君饮 | 2024-06-22 13:24:03
赞
踩
idea scala本地运行
IDEA中运行Scala-Spark程序
- 前提条件:保证本地已经安装Spark、Hadoop、IDEA
- 测试版本:IDEA 2020.1、spark 2.4.6 hadoop 2.7.3
Step1:安装Scala-IDEA插件
方法一:(在线安装)
打开IDEA,选择File->Setting,搜索Scala安装

方法二:本地安装(由于下载文件在国外服务器可能存在下载速度缓慢问题)
进入IDEA-Scala插件,下载符合自己IDEA版本的插件,找到下图位置安装即可

Step2:创建Scala项目
新建Project

选择新建Maven项目

之后修改项目名称->Next->Finish
Step3: 配置Java环境
在Settings中将编译环境设置为java 8,然后apply->ok

Step4:修改pom.xml文件

pom.xml文件内容示例
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>test</artifactId> <version>1.0-SNAPSHOT</version> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.11.8</scala.version> <spark.version>2.4.6</spark.version> <hadoop.version>2.7.3</hadoop.version> </properties> <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </pluginRepository> </pluginRepositories> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.11</artifactId> <version>${spark.version}</version> </dependency> </dependencies> </project>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
此时需要根据本地环境修改配置文件中的Spark,Scala,Hadoop版本
修改pom.xml后右键找到Maven->Reimport,等待下方进度条完成导入

注意:导入过程中若是出现了问题,可以到mvnrepository寻找匹配的版本
Step5:写出一个Scala-Spark程序
新建一个Scala Class

选择创建Object
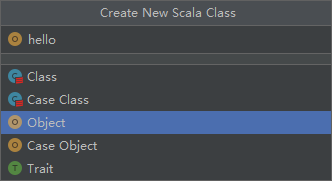
测试代码如下:
package org.example import org.apache.spark.sql.SparkSession object hello { def main(args: Array[String]) { //构建Spark对象 val ss = SparkSession .builder() .master("local[*]") .appName("movie") .getOrCreate() val sc = ss.sparkContext val data_path = "file:/C:/Users/yeyu/Desktop/data/word.txt" val data = sc.textFile(data_path) data.map(_.split(",")).map(f => (f(0), f(1), f(2))).foreach(println(_)) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
我在本地桌面创建了如下文本文件
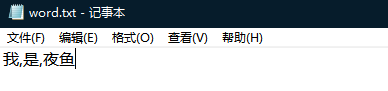
右键运行可以看到输出结果

至此已经完成了Scala-Spark程序的本地编写和运行
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/746654
推荐阅读
相关标签

