
- 1Fastjson 反序列化漏洞(CVE-2017-18349)_fastjson 反序列化 cve-2017
- 2迁移学习之TCA算法_tca迁移学习
- 3链表的回文结构_链表回文结构
- 4VMware17虚拟机安装macos Sequoia 15.0 Beta教程以及镜像CDR/ISO下载_vmware macos镜像下载
- 5AI人工智能 Agent:在新零售中的应用_ai+agent+零售行业
- 6记一次因敏感信息泄露而导致的越权+存储型XSS_鹰图平台如何搜索学校网站
- 7Android基础教程(非常详细)从零基础入门到精通,看完这一篇就够了_安卓开发菜鸟教程
- 8晋升为CTO了
- 9独家揭秘!最新博客与新浪文章,科技前沿、健康养生、职场发展等精彩内容一网打尽
- 10JavaScript青少年简明教程:语法基础
【Pandas】Python中None、null和NaN_pandas空值怎么表示
赞
踩
经常混淆。
空值一般表示数据未知、不适用或将在以后添加数据。缺失值指数据集中某个或某些属性的值是不完整的。
在python中有这些空值缺失值表示:['nan', '', 'None', None, np.nan]
一般空值使用None表示,缺失值使用NaN表示。
注意: python中没有null,但是有和其意义相近的None。
pd.isnull不仅可以检测np.nan也可以检测None。
注意:pd.isnull是不可以检测字符串的,比如’',‘nan’,‘None’。这个也很好理解,字符串有字符串的判断方式。我就踩了None和'None'的坑。。。
目录
1. None
- c = None
- if isinstance(c, str):
- print('ok')
- else:
- print(type(c))
-
- # 代码输出
- # <class 'NoneType'>
None表示空值,它是一个特殊 Python 对象, None的类型是NoneType。None 是 NoneType 数据类型的唯一值,我们不能再创建其它 NoneType 类型的变量,但是可以将 None 赋值给任何变量。
- >>> type(None)
- <class 'NoneType'>
该对象在Python解释器启动时自动创建,解释器停止时销毁。
特点
- None 不支持任何运算
- None 和任何其他的数据类型比较永远返回False
- None 有自己的数据类型NoneType,不能创建其他NoneType对象(它只有一个值None)
- None 与0、空列表、空字符串不一样
- 可以将None赋值给任何变量,也可以给None值变量赋值
- None是没有像len,size等属性的,要判断一个变量是否为None,直接使用
- >>> None == 0
- False
- >>> None == ''
- False
- >>> None == False
- False
作为没有return关键函数的返回值
对于所有没有 return 语句的函数定义,Python 都会在末尾加上 return None,使用不带值的 return 语句(也就是只有 return 关键字本身),那么就返回 None。
def func()没有写返回值,那么返回值就是None
- >>> def function():
- print('hanshu')
-
- result = function()
- print(result)
- hanshu
- None
特别说明,表格中None有两种情况:
(1)空值类型的None。(2)字符串类型的“None”,是真实存在的。
1.1 None 与 'None'
1.1.1 处理空值类型的None
- df.dropna(how='all')#删除所有内容均为缺失值的行
- df.dropna(axis=1) #丢弃有缺失值的列
- df.dropna(axis=1, how = 'all') #丢弃所有列中所有值均缺失的列
- df.dropna(axis=0, subset=['datetime', 'values'])#丢弃datetime和values这两列中有缺失值的行
1.1.2 处理字符串类型的None
可以先将“None”值replace为pandas可读取的空值,如nan,然后再用dropna()去掉即可。
df.replace(to_replace='None', value=np.nan).dropna()
但我用这个没生效。。。
2. NaN
当使用Numpy或者Pandas处理数据的时候,经常会遇到条目中没有没有数据,然后当我们在去打印的时候就会出现NaN。
- NaN是没有办法和任何数据进行比较。
- 它和任何值都不相等,包括他自己。
- 它的类型是float,但是和任何值做计算的结果都是NaN
- import pandas as pd
- df = pd.read_excel('/Users/mac/Desktop/test.xlsx',header=None)
- df
- 0 1 2
- 0 1 2.0 3
- 1 4 NaN 6
- 2 7 8.0 9
原数据为下图:

- >>> num = df.loc[1,1]
- >>> num
- nan
- >>> result = num + 2 # nan+2是nan哦
- >>> result
- >>> nan
nan和np.nan的关系是?一样的。
3. Pandas特别说明
- 在pandas中的空值是""(直接一对双引号);空字符串:" ",中间多了一个空格
- 缺失值在DataFrame指的是NaN或者NaT,在Series中指的是none或者nan
- 当我们需要人为指定一个缺失值的时候,默认用None和np.nan来表示

其次,我们看看Pandas中None和NaN的关联:np.nan就是NaN,数据类型float64
- 在我们创建的时候,默认二者是相同的;
如果我们指定赋值为None,在Series中依然会变成none,并且是以float64的数据类型显示。

下面截图有问题,None不允许赋值。
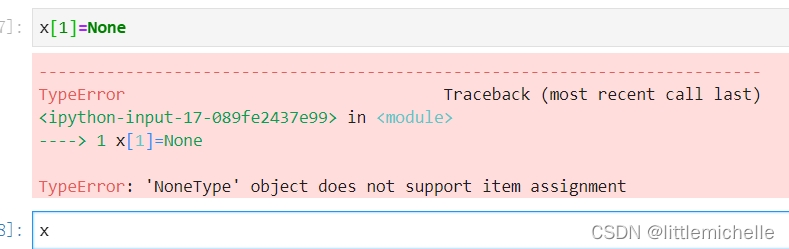
有问题

判断缺失值方法
Pandas中提供了一些用于
检查或处理空值和缺失值的函数或方法
- 使用
isnull()和notnull()函数可以判断数据集中是否存在空值和缺失值 - 对于
缺失数据可以使用dropna()和fillna()方法对缺失值进行删除和填充,如果是None则不生效。
4. Pandas如何检测None和Nan
- None是Python的特殊类型,NoneType对象,它只有一个值None。它不支持任何运算也没有任何内建方法。None和任何其他的数据类型比较永远返回False。None有自己的数据类型NoneType。你可以将None复制给任何变量,但是你不能创建其他NoneType对象。
- >>>type(None)
- <class 'NoneType'>
- python 中Nan是not a number(非数)它即不是无穷大, 也不是无穷小,无穷大减无穷大会导致NaN,无穷大乘以0或无穷小或除以无穷大会导致NaN,有NaN参与的运算, 其结果也一定是NaN,NaN != NaN
- >>>type(np.nan)
- <class 'float'>
- NULL 空字符串(python里没有null这个类型)
- >>>type('')
- <class ''str'>
4.1 如何检测
个人感觉最好用的是pd.isnull(或pd.isna)
isnull和isna区别
isnull是isna的别名,既然一样为什么要搞两个名字?Pandas dataframe是根据R的dataframe设计的,而R语言中na和null是两种不同的数据类型,因此有isna和isnull,python就保留了这两个方法,isnull是isna的别名而已;另一方面,pandas是建立在numpy之上的,numpy中又没有na或null值,而是用np.nan来表示缺失值,
所以pd.isnull不仅可以检测np.nan也可以检测None。
注意
pd.isnull是不可以检测字符串的,比如’',‘nan’,‘None’。这个也很好理解,字符串有字符串的判断方式。
比较全面的判断这些与空值有关的方法
- i == '' or
- pd.isnull(i) or
- pd.isnull(float('nan')) (或者 i =='nan') or
- i =='None'
举例
- list = ['nan', '', 'None', None, np.nan]
- for i in list:
- if i == '' or pd.isnull(i) or pd.isnull(float('nan')) or i == 'None':
- print(i)
-
- # ----------------------------
- nan
-
- None
- None
- nan
5. 个人理解的等式
- NULL(数据库)=None(python列表)=NaN(pandas)
- 空字符(数据库)=空字符(python列表)=空字符(pandas)
- 从csv中获取数据时:空值(csv)=NULL(数据库)=NaN(pandas)
- 转为csv数据时:数据库中的NULL\空字符和pandas中的NaN\空字符,都变成csv中的空值。
参考:
图解pandas缺失值处理_pandas none赋值_尤尔小屋的猫的博客-CSDN博客
https://blog.csdn.net/Android_xue/article/details/121257528


