
- 1[转]大数据环境搭建步骤详解(Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等安装与配置)_大数据集群搭建,hadoop,hive,hbase
- 22024年最新如何安装Pycharm最新版本-详细教程_pycharmeve和arm64,2024年最新C C++开发最佳实践手册全网独一份_pycharm2024安装教程
- 35.gradle配置和project_gradle implementation project
- 4【秋招总结】双非本小菜鸡的坎坷秋招之路(附面经)_古茗offer 3天
- 5Allure精通指南(02)Mac和Windows系统环境配置_allure配置环境变量
- 6如何把自己的数据分享给chatgpt让它处理你的数据_分享用gpt写的
- 7资讯|WebRTC M90 更新_webrtc m100
- 8物体检测框架 RetinaNet 深度神经网络简介
- 9江大白 | 基于Pytorch框架,从零实现Transformer模型实战(建议收藏!)_transformer实战
- 10SQL注入之WAF绕过技巧_sql绕过waf的方法
大模型部署手记(3)通义千问+Windows GPU_通义千问本地部署 gpu
赞
踩
1.简介
组织机构:阿里
模型:Qwen/Qwen-7B-Chat-Int4
下载:http://huggingface.co/Qwen/Qwen-7B-Chat-Int4
modelscope下载:https://modelscope.cn/models/qwen/Qwen-7B-Chat-Int4/summary
硬件环境:暗影精灵7Plus
Windows版本:Windows 11家庭中文版 Insider Preview 22H2
内存 32G
GPU显卡:Nvidia GTX 3080 Laptop (16G)
安装阿里的 通义千问大模型有两种方式,modelscope方式和transformers(huggingface)方式。
参考资料:
1.玩一玩140亿参数的阿里千问!Qwen+Win11+3060 https://zhuanlan.zhihu.com/p/659000534
2.玩一玩通义千问Qwen开源版,Win11 RTX3060本地安装记录! https://zhuanlan.zhihu.com/p/648368704
2.代码和模型下载
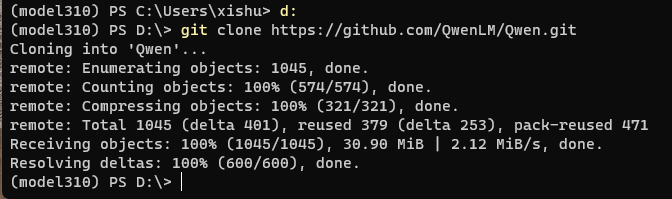
下载代码仓:
d:
git clone https://github.com/QwenLM/Qwen.git
模型下载参见 第四部分执行 python Qwen-7B-Chat-Int4.py的过程。
3.安装依赖
打开Anaconda Powershell Prompt,创建conda环境:
conda create -n model310 python=3.10
conda activate model310
安装modelscope基础库
pip install modelscope
在安装modelscope的时候,系统会自动安装pytorch 2.0.1(后面会发现装的torch这个完全不对)
打开 魔搭社区 http://modelscope.cn
注册一下:
打开 Qwen-7B inr4量化的主页:https://modelscope.cn/models/qwen/Qwen-7B-Chat-Int4/summary
安装量化依赖:
pip install auto-gptq optimum

安装量化包:
pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui

安装其他依赖:
pip install transformers_stream_generator
pip install tiktoken

pip install deepspeed

目前deepspeed在windows上的安装还存在问题。我们先忽略掉吧!
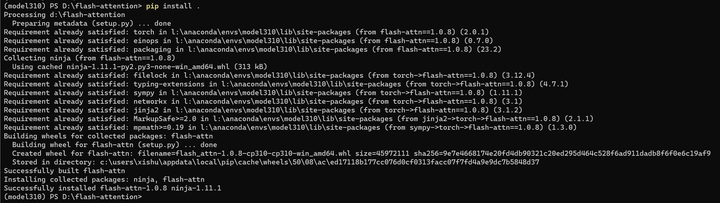
安装flash-attention库
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention
pip install .
# 下方安装可选,安装可能比较缓慢。
# Below are optional. Installing them might be slow.
# pip install csrc/layer_norm
# pip install csrc/rotary
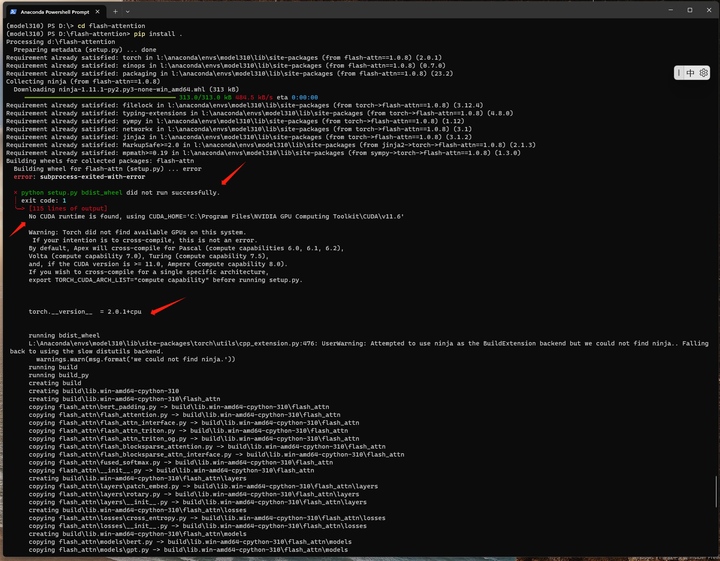
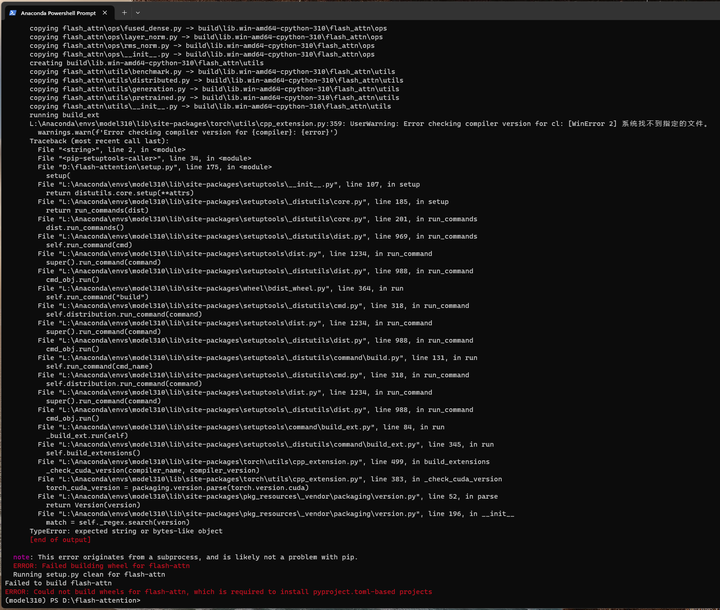
看日志应该是torch可能不是CUDA的版本。
验证下:
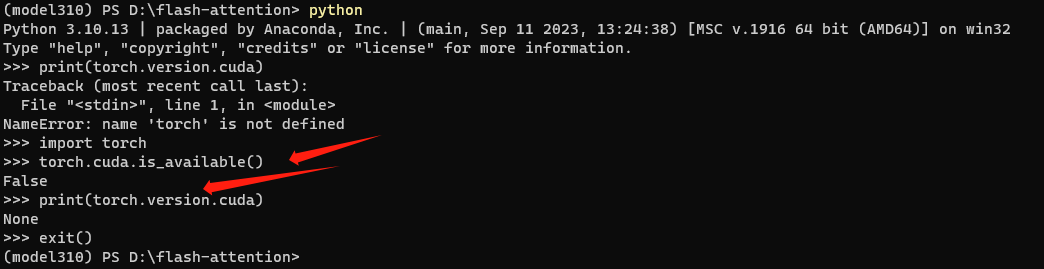
果然如此。
还是使用conda安装pytorch 2.0的CUDA版本吧!
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia

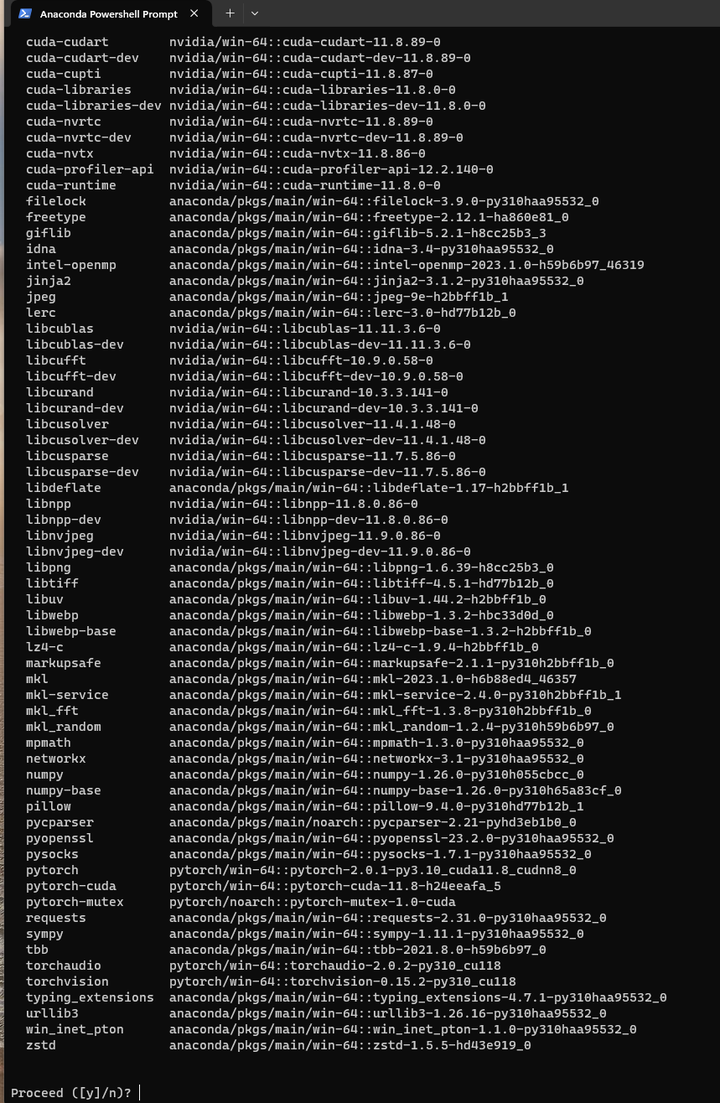


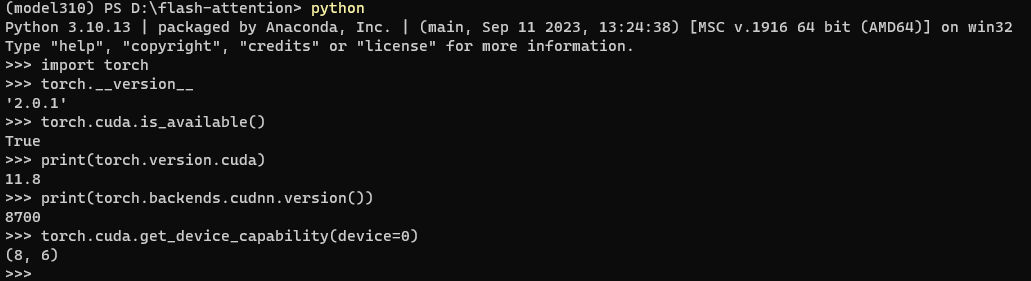
为了保险,还是要验证一下:
python
import torch
#pytorch的版本
torch.__version__
#是否支持CUDA
torch.cuda.is_available()
#CUDA的版本
print(torch.version.cuda)
#cuDNN的版本
print(torch.backends.cudnn.version())
#GPU内存
torch.cuda.get_device_capability(device=0)
再来:
pip install .
4.部署验证
编辑d:\Qwen\Qwen-7B-Chat-Int4.py 文件,内容如下:
- from modelscope import AutoTokenizer, AutoModelForCausalLM, snapshot_download
- model_dir = snapshot_download("qwen/Qwen-7B-Chat-Int4", revision = 'v1.1.3' )
-
- # Note: The default behavior now has injection attack prevention off.
- tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
-
- model = AutoModelForCausalLM.from_pretrained(
- model_dir,
- device_map="auto",
- trust_remote_code=True
- ).eval()
- response, history = model.chat(tokenizer, "你好", history=None)
- print(response)
- # 你好!很高兴为你提供帮助。
执行这个文件:
cd d:\Qwen
python Qwen-7B-Chat-Int4.py
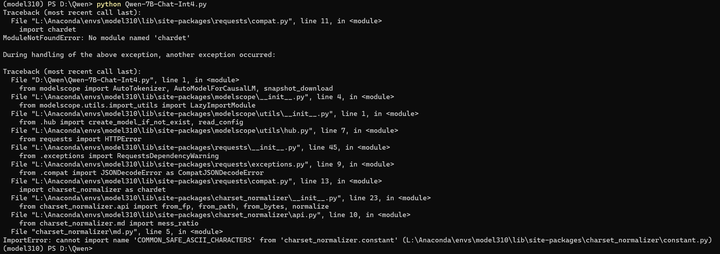
pip install chardet

再来:
python Qwen-7B-Chat-Int4.py

耐心等待模型下载完毕。。。
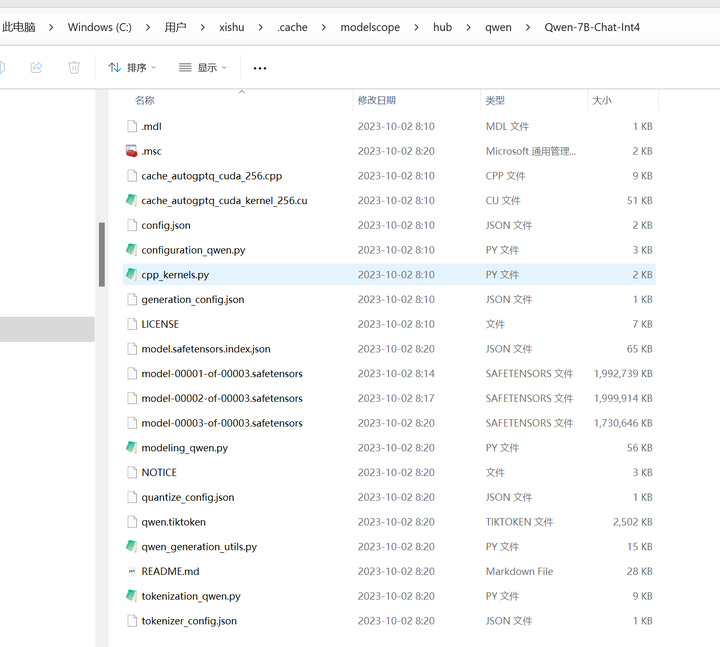
看来模型是下载到了这个目录:C:\Users\用户名\.cache\modelscope\hub\qwen\Qwen-7B-Chat-Int4
这个下载的时候不显示速度,下载完毕之后才显示速度。。。
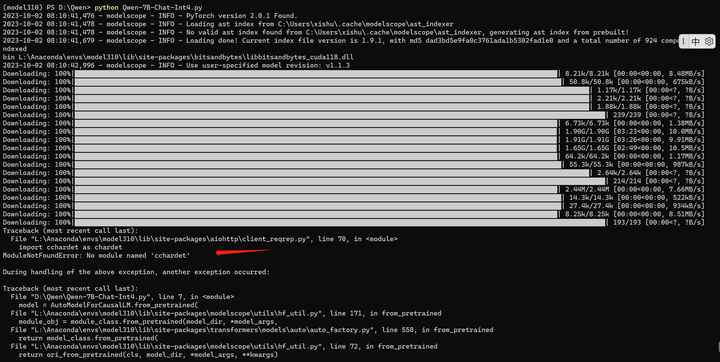
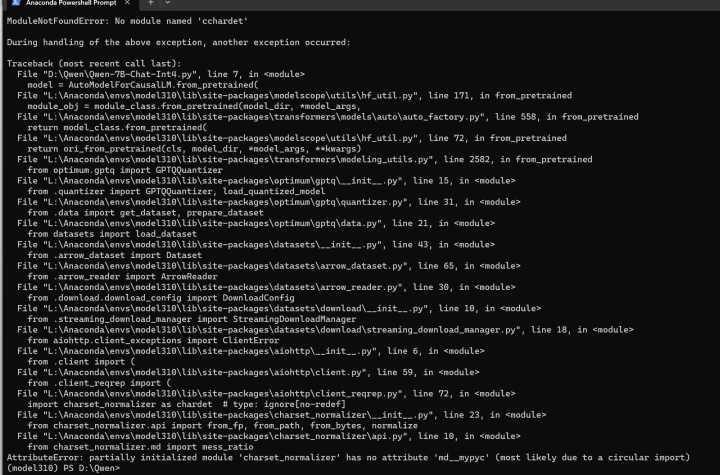
仔细看看还少装了什么包:
pip install cchardet

再来:
python Qwen-7B-Chat-Int4.py

看来已经能成功运行了。
将 前面下载目录 C:\Users\用户名\.cache\modelscope\hub\qwen\Qwen-7B-Chat-Int4 下的所有文件复制到 当前目录的 Qwen\Qwen-7B-Chat-Int4 目录:
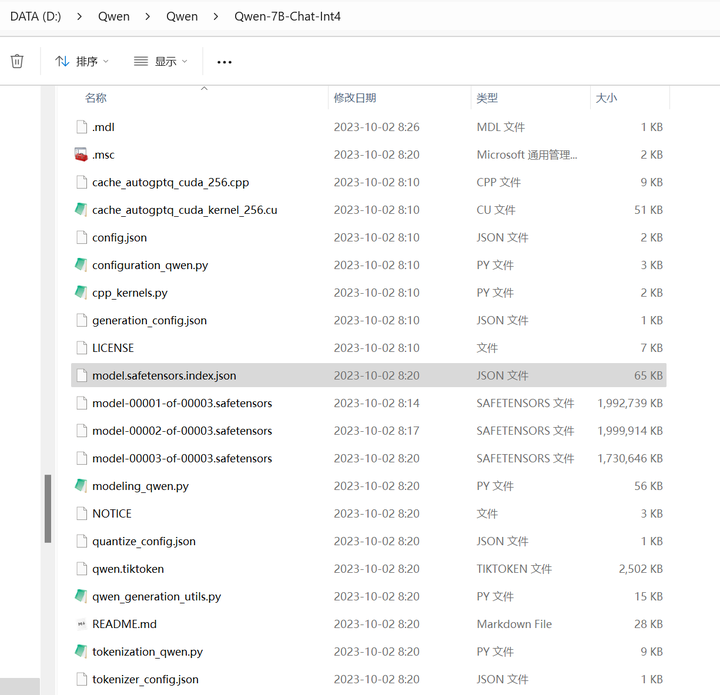
修改cli_demo.py
修改如下代码:
DEFAULT_CKPT_PATH = './Qwen/Qwen-7B-Chat-Int4'
运行 python cli_demo.py

系统很快会弹出:

做一些交互:
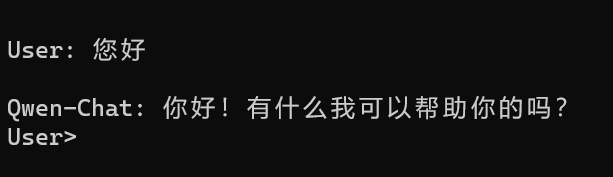


不过每次都要清屏,有点不舒服。
把代码中的clear_screen都去掉:(除了收到明确的clear命令)
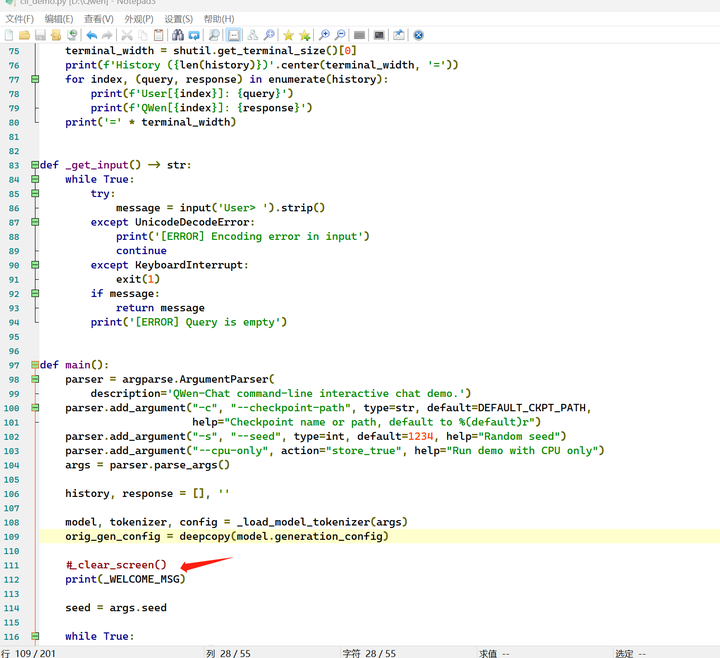
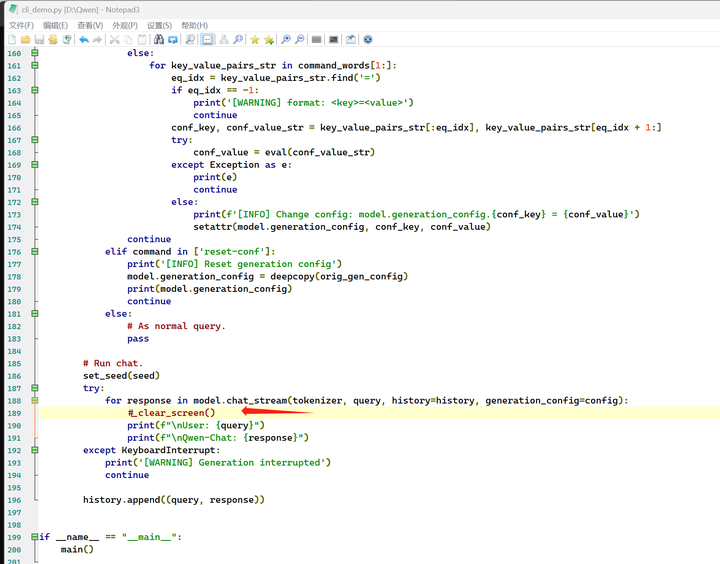
CTRL-C退出去重新运行:python cli_demo.py
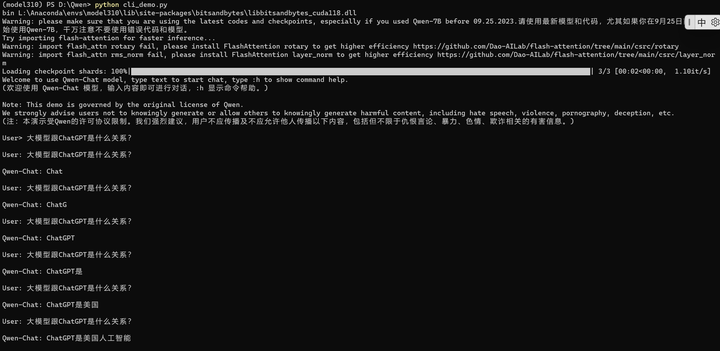

貌似有点问题,代码好像每次都在做刷屏,然后输入一行新的话处理。
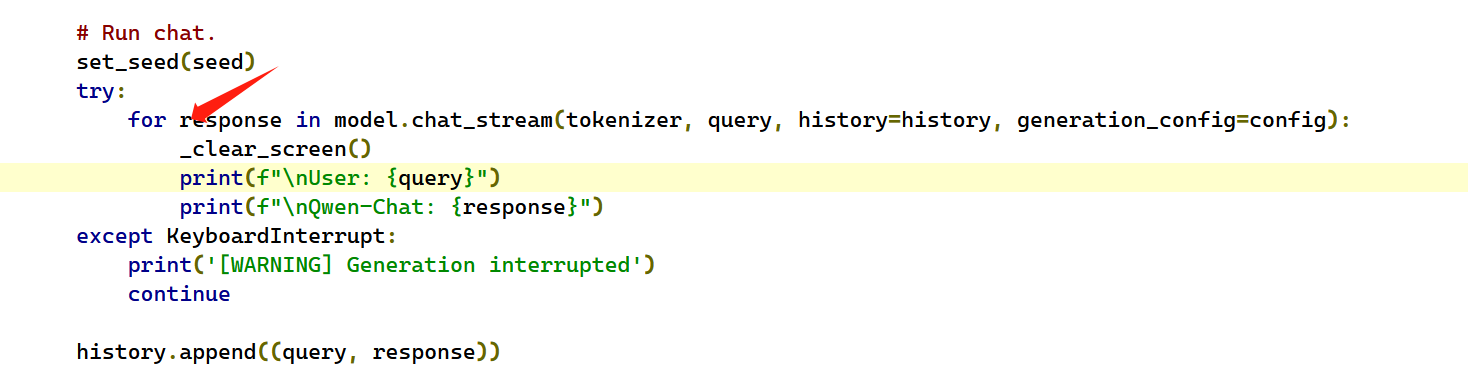
经过多次尝试,代码这样修改就可以了:
- # Copyright (c) Alibaba Cloud.
- #
- # This source code is licensed under the license found in the
- # LICENSE file in the root directory of this source tree.
-
- """A simple command-line interactive chat demo."""
-
- import argparse
- import os
- import platform
- import shutil
- from copy import deepcopy
-
- from transformers import AutoModelForCausalLM, AutoTokenizer
- from transformers.generation import GenerationConfig
- from transformers.trainer_utils import set_seed
-
- DEFAULT_CKPT_PATH = './Qwen/Qwen-7B-Chat-Int4'
-
- _WELCOME_MSG = '''\
- Welcome to use Qwen-Chat model, type text to start chat, type :h to show command help.
- (欢迎使用 Qwen-Chat 模型,输入内容即可进行对话,:h 显示命令帮助。)
- Note: This demo is governed by the original license of Qwen.
- We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, including hate speech, violence, pornography, deception, etc.
- (注:本演示受Qwen的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)
- '''
- _HELP_MSG = '''\
- Commands:
- :help / :h Show this help message 显示帮助信息
- :exit / :quit / :q Exit the demo 退出Demo
- :clear / :cl Clear screen 清屏
- :clear-his / :clh Clear history 清除对话历史
- :history / :his Show history 显示对话历史
- :seed Show current random seed 显示当前随机种子
- :seed <N> Set random seed to <N> 设置随机种子
- :conf Show current generation config 显示生成配置
- :conf <key>=<value> Change generation config 修改生成配置
- :reset-conf Reset generation config 重置生成配置
- '''
-
-
- def _load_model_tokenizer(args):
- tokenizer = AutoTokenizer.from_pretrained(
- args.checkpoint_path, trust_remote_code=True, resume_download=True,
- )
-
- if args.cpu_only:
- device_map = "cpu"
- else:
- device_map = "auto"
-
- model = AutoModelForCausalLM.from_pretrained(
- args.checkpoint_path,
- device_map=device_map,
- trust_remote_code=True,
- resume_download=True,
- ).eval()
-
- config = GenerationConfig.from_pretrained(
- args.checkpoint_path, trust_remote_code=True, resume_download=True,
- )
-
- return model, tokenizer, config
-
-
- def _clear_screen():
- if platform.system() == "Windows":
- os.system("cls")
- else:
- os.system("clear")
-
-
- def _print_history(history):
- terminal_width = shutil.get_terminal_size()[0]
- print(f'History ({len(history)})'.center(terminal_width, '='))
- for index, (query, response) in enumerate(history):
- print(f'User[{index}]: {query}')
- print(f'QWen[{index}]: {response}')
- print('=' * terminal_width)
-
-
- def _get_input() -> str:
- while True:
- try:
- message = input('User> ').strip()
- except UnicodeDecodeError:
- print('[ERROR] Encoding error in input')
- continue
- except KeyboardInterrupt:
- exit(1)
- if message:
- return message
- print('[ERROR] Query is empty')
-
-
- def main():
- parser = argparse.ArgumentParser(
- description='QWen-Chat command-line interactive chat demo.')
- parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
- help="Checkpoint name or path, default to %(default)r")
- parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
- parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
- args = parser.parse_args()
-
- history, response = [], ''
-
- model, tokenizer, config = _load_model_tokenizer(args)
- orig_gen_config = deepcopy(model.generation_config)
-
- #_clear_screen()
- print(_WELCOME_MSG)
-
- seed = args.seed
-
- while True:
- query = _get_input()
-
- # Process commands.
- if query.startswith(':'):
- command_words = query[1:].strip().split()
- if not command_words:
- command = ''
- else:
- command = command_words[0]
-
- if command in ['exit', 'quit', 'q']:
- break
- elif command in ['clear', 'cl']:
- _clear_screen()
- print(_WELCOME_MSG)
- continue
- elif command in ['clear-history', 'clh']:
- print(f'[INFO] All {len(history)} history cleared')
- history.clear()
- continue
- elif command in ['help', 'h']:
- print(_HELP_MSG)
- continue
- elif command in ['history', 'his']:
- _print_history(history)
- continue
- elif command in ['seed']:
- if len(command_words) == 1:
- print(f'[INFO] Current random seed: {seed}')
- continue
- else:
- new_seed_s = command_words[1]
- try:
- new_seed = int(new_seed_s)
- except ValueError:
- print(f'[WARNING] Fail to change random seed: {new_seed_s!r} is not a valid number')
- else:
- print(f'[INFO] Random seed changed to {new_seed}')
- seed = new_seed
- continue
- elif command in ['conf']:
- if len(command_words) == 1:
- print(model.generation_config)
- else:
- for key_value_pairs_str in command_words[1:]:
- eq_idx = key_value_pairs_str.find('=')
- if eq_idx == -1:
- print('[WARNING] format: <key>=<value>')
- continue
- conf_key, conf_value_str = key_value_pairs_str[:eq_idx], key_value_pairs_str[eq_idx + 1:]
- try:
- conf_value = eval(conf_value_str)
- except Exception as e:
- print(e)
- continue
- else:
- print(f'[INFO] Change config: model.generation_config.{conf_key} = {conf_value}')
- setattr(model.generation_config, conf_key, conf_value)
- continue
- elif command in ['reset-conf']:
- print('[INFO] Reset generation config')
- model.generation_config = deepcopy(orig_gen_config)
- print(model.generation_config)
- continue
- else:
- # As normal query.
- pass
-
- # Run chat.
- set_seed(seed)
- try:
- for response in model.chat_stream(tokenizer, query, history=history, generation_config=config):
- pass
- # _clear_screen()
- # print(f"\nUser: {query}")
- print(f"\nQwen-Chat: {response}")
- except KeyboardInterrupt:
- print('[WARNING] Generation interrupted')
- continue
-
- history.append((query, response))
-
-
- if __name__ == "__main__":
- main()

请注意print的位置。
python cli_demo.py
(全文完,谢谢阅读)

