
热门标签
热门文章
- 1你觉得做为一名开发负责人需要具备哪些特质--chatgpt回答_开发项目负责人 需要具备
- 2Django进阶:DRF(Django REST framework)_django drf
- 3Kafka 最佳实践:构建高性能、可靠的数据管道_kafka消费模式最佳实践
- 4python转换成c语言_将Python转换成C语言,然后用Cython编译成exe
- 5记 搭建pycharm远程连接spark的艰难过程_importerror: no module named findspark
- 6从零开始研发GPS接收机连载——3、用HackRF软件无线电平台作为GPS模拟器_gps sdr sim
- 7utf8mb4_0900_ai_ci_utf8mb40900aici
- 8Java项目:客户关系管理系统(java+SpringBoot+layui+html+maven+mysql)_java 管理系统角色划分
- 9Hadoop集群环境配置及安装配置(详细过程包含安装包)_hadoop安装与配置_hadoop 配置
- 10深度学习笔记(九):神经网络剪枝(Neural Network Pruning)详细介绍
当前位置: article > 正文
python读取所有sheet内容到另一个文件中_python 提取excel各sheet固定的内容另存
作者:正经夜光杯 | 2024-06-29 07:27:40
赞
踩
python 提取excel各sheet固定的内容另存
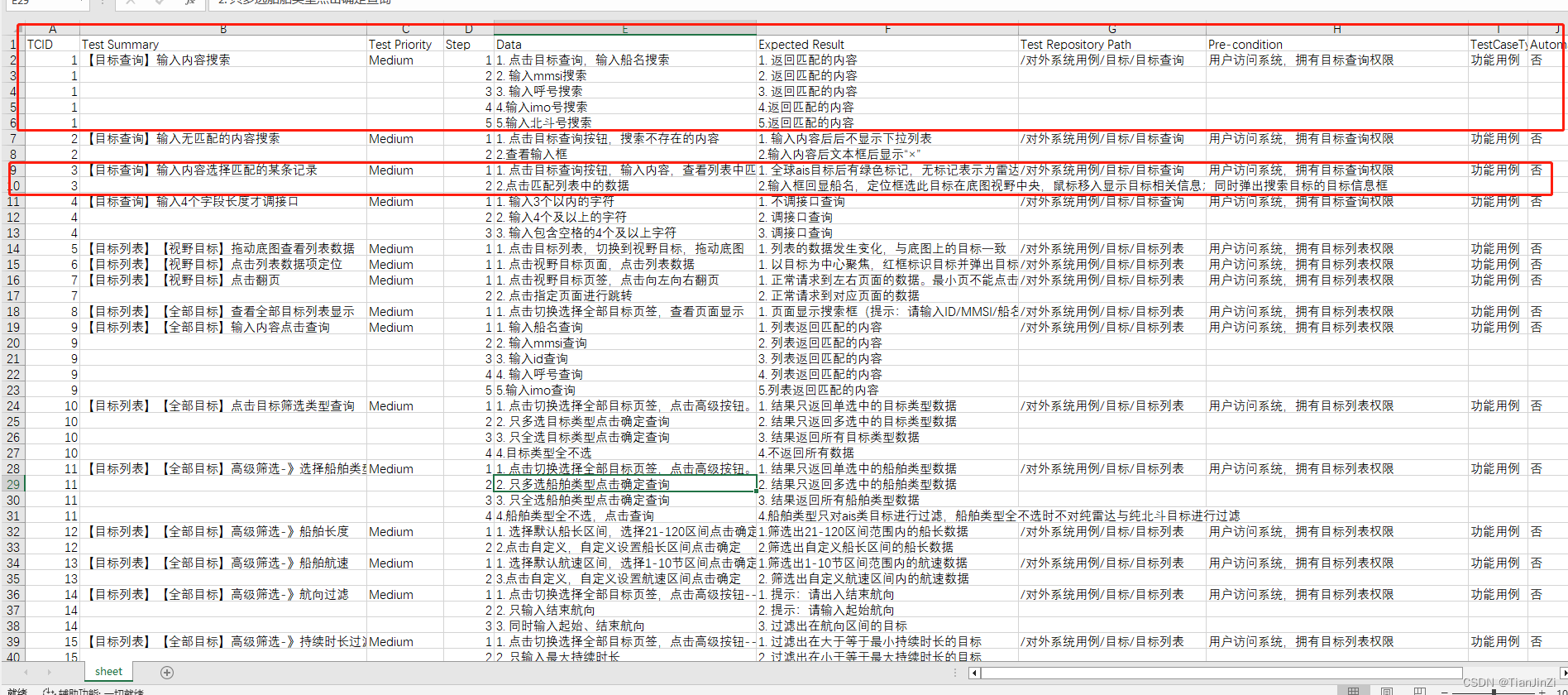
实现效果:
将原excel中的步骤、预期效果列按回车拆成多行数据,其余字段值填充其他数据

实现结果:
- # This is a sample Python script.
-
- # Press Shift+F10 to execute it or replace it with your code.
- # Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
-
-
- # def print_hi(name):
- # # Use a breakpoint in the code line below to debug your script.
- # print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
- #
- #
- # # Press the green button in the gutter to run the script.
- # if __name__ == '__main__':
- # print_hi('PyCharm')
- #
- # # See PyCharm help at https://www.jetbrains.com/help/pycharm/
-
- import openpyxl, re
-
-
- def SplitLine():
- book = openpyxl.load_workbook(file_path + "\\" + raw_excel) # 读取原excel
- wb = book.active
- book_2 = openpyxl.load_workbook(file_path + "\\" + "result.xlsx") # 读取新建的result
- wb_2 = book_2.active
-
- name = ["TCID", "Test Summary", "Test Priority", "Step", "Data", "Expected Result", "Test Repository Path",
- "Pre-condition", "TestCaseType", "Automation", "LinkType", "LinkIssue"]
- # name = ["所属模块(*)", "用例标题(*)", "前置条件", "步骤", "预期结果", "优先级"] # result表格的首行内容
- for a in range(1, len(name) + 1):
- wb_2.cell(row=1, column=a, value=name[a - 1]) # 写入result的首行
-
- j = 2 #新建excel的行数
- k = 0 #回车数量
- b = 2
-
- #遍历所有的sheet
- for sheet_name in book.sheetnames:
- print(book.sheetnames)
- sheet = book[sheet_name]
- a = sheet.cell(2,2).value
- print(a)
- print(sheet)
-
-
- print(sheet.max_row)
- with open(file_path + "\\" + "result.xlsx",encoding='utf-8') as f:
- for i in range(2, sheet.max_row+1):
-
- # 读取原excel的每行内容
- Test_Repository_Path = sheet.cell(i, 1).value
-
-
- try:
- Test_Repository_Path = "/对外系统用例/"+sheet_name+"/"+Test_Repository_Path
- except:
- print("继续执行")
- # print(wb.cell(1, 1).value)
- print(Test_Repository_Path)
- Test_Summary = sheet.cell(i, 2).value
- Pre_condition = sheet.cell(i, 3).value
- Data = sheet.cell(i, 4).value
- print(Data)
- Expected_Result = sheet.cell(i, 5).value
-
-
- # 将内容写入result中
- wb_2.cell(row=j, column=7, value=Test_Repository_Path)
- wb_2.cell(row=j, column=2, value=Test_Summary)
- wb_2.cell(row=j, column=3, value="Medium")
- wb_2.cell(row=j, column=8, value=Pre_condition)
- wb_2.cell(row=j, column=5, value=Data)
- wb_2.cell(row=j, column=6, value=Expected_Result)
- wb_2.cell(row=j, column=9, value="功能用例")
- wb_2.cell(row=j, column=10, value="否")
- wb_2.cell(row=j, column=1, value=b-1)
- wb_2.cell(row=j, column=4, value=1)
-
-
- try:
- # 对Data中的内容进行识别
- if '\n' in Data:
- k = Data.count("\n")
- k = k + 1 # 数据量比“;”的个数多一个
- Data_2 = []
- Expected_Result_2 = []
- #循环所有的回车数量,分隔到每一行中
- for p in range(0, k):
- Data_2.append(re.split(r"[\n]\s*", Data.split("\n")[p]))
- Expected_Result_2.append(re.split(r"[\n]\s*", Expected_Result.split("\n")[p]))
-
- # print(Data_2)
- # print(Data_2[p][0])
- # # print(Data_2[0][p])
- wb_2.cell(row=j, column=5, value=str(Data_2[p][0]))
- wb_2.cell(row=j, column=6, value=str(Expected_Result_2[p][0]))
- wb_2.cell(row=j, column=4, value=p+1)
- wb_2.cell(row=j, column=1, value=b - 1)
-
- # print(wb_2.cell(row=j, column=4).value)
- j = j + 1
- else:
- wb_2.cell(row=j, column=5, value=Data)
- wb_2.cell(row=j, column=6, value=Expected_Result)
- wb_2.cell(row=j, column=1, value=b - 1)
-
- j = j + 1
-
- except:
- print("继续执行")
- b = b + 1
-
-
-
- book_2.save(file_path + "\\" + "result.xlsx") # 保存excel
-
-
-
- if __name__ == "__main__":
- file_path =r'C:\Users\12133\Desktop'
- raw_excel ='对外系统用例.xlsx'
- # file_path = input("file_path:")
- # raw_excel = input("excel_name:")
- SplitLine()

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/768650
推荐阅读
相关标签

