
- 1【100个 Unity实用技能】☀️ | Unity读取本地文件(Json,txt等)的三种方法示例
- 2使用mpvue框架开发小程序入门系列_mpvue小程序可以用idea打开吗
- 3【鸿蒙开发】第九章 ArkTS语言UI范式-状态管理(一)_鸿蒙artts对象数组中数据怎么更新
- 4Juno markets:特斯拉FSD登陆中国市场,自动驾驶能否颠覆传统出行?
- 5ONLYOFFICE 桌面编辑器 8.1使用体验分享
- 6基于Flask的Web应用框架_flask 前端框架
- 75大技巧教你快速找到最感兴趣的文章
- 8ssh: command not found的解决办法_ssh报错command 'roslaunch' not found, but can be ins
- 9Elasticsearch 之 commit point | Segment | refresh | flush 索引分片内部原理_在 elasticsearch 中,commit 操作做了什么
- 10matlab读取cvs文件的几种方法_matla中怎么完整读入csv文件
2024年Python最新python爬虫入门:批量爬取网站图片并保存_python爬虫图片(3),面试成功了又不想去了怎么拒绝_爬图工具
赞
踩
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
打开anaconda prompt,这是anaconda的交互界面,很多指令在该界面直接输入,便可直接下载众多函数库。
conda install lxml
conda install requests
- 1
- 2
- 3
目标网页
引入库
import os
import requests
from lxml import etree
- 1
- 2
- 3
- 4
隐藏爬虫身份
如今很多网站设置了反爬系统,我们对爬虫身份进行隐藏,将其隐藏为正常的用户访问,具体操作如下:
首先,我们随意打开一个网站,右键点击检查:
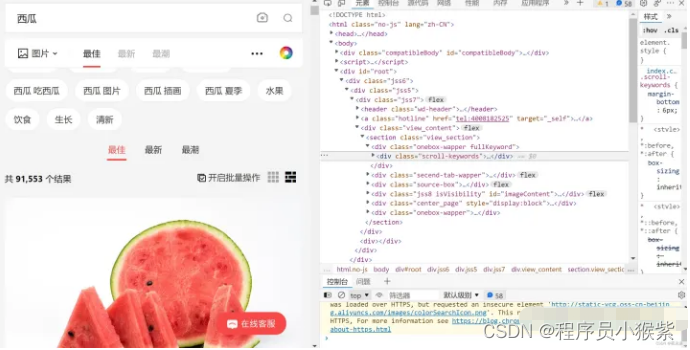
打开后,点击网络,并且ctrl+r刷新:
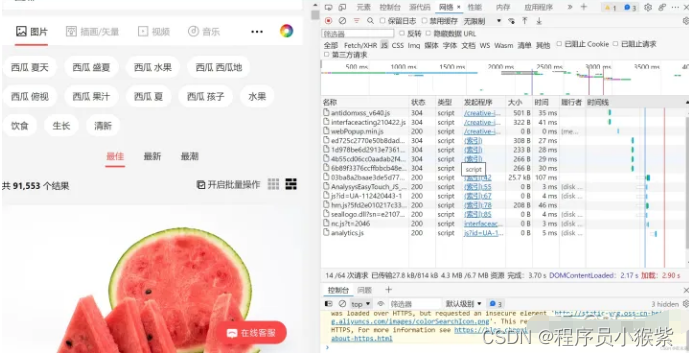
刷新后随机点一个名称从标头往下翻,一般可以在请求标头上找到User-Agent并且复制(没有就换个名称接着找):
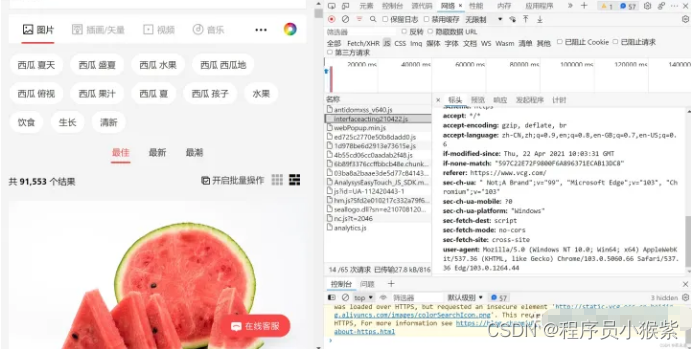
随后在代码中添加如下:
#输入网站的地址
url = https://pic.netbian.com/4kdongman/
#隐藏爬虫身份
header = {
'User_Agent':'粘贴复制的user-agent'
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
获取目标地址
在元素这一栏中找到(在页面中选择一个元素进行检查)这个图标,选择你想要爬取的照片,会自动帮你定位到该图片所在的标签。
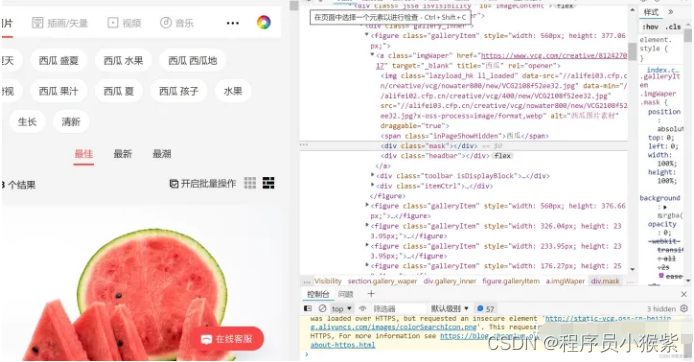
还是这张图片,找到要下载的图片地址在a标签下的img src中,再次进行匹配。
网页抓取
通过requests库对网页的地址进行访问申请
response = requests.get(url,header)
- 1
- 2
此时我们可以通过对page的状态码查看来判断是否访问成功(返回值为200代表访问成功)
response_status = response.status_code
print(response_status)
- 1
- 2
- 3
获取网页文本并将文本解析
page_text = response.text
tree = etree.HTML(page_text)
- 1
- 2
- 3
文本匹配
首先观察,发现所有的图片地址都在figure标签中,所有的figure标签又都存在于 div class=“gallery_inner” 中,所以我们先匹配到div这个标签。
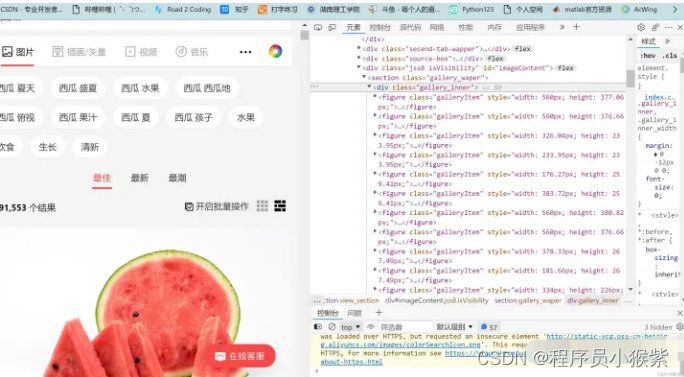
在xpath中//表示在该本文中搜索所有的div标签,[@class=“gallery_inner”]则将div标签限定,再通过/figure找到所有的标签。
xpath进行匹配:
figure_list = tree.xpath('//div[@class="gallery_inner"]/figure')
- 1
- 2
接着我们对所有的li标签进行循环,依次对每个图片地址进行操作。
for figure in figure_list:
img_src = figure.xpath('./a/img/@data-src')[0]
img_src = 'https:' + img_src
img_name = img_src.split('/')[-1]
img_data = requests.get(url=img_src,headers=header).content
img_path = 'piclitl/' + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
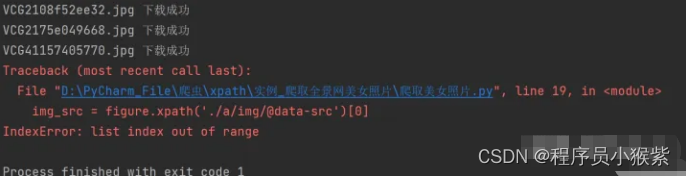
大致框架搭好后运行,发现了两个报错:
一、在对figure标签请求时,匹配没有结果出现列表超出范围的报错。
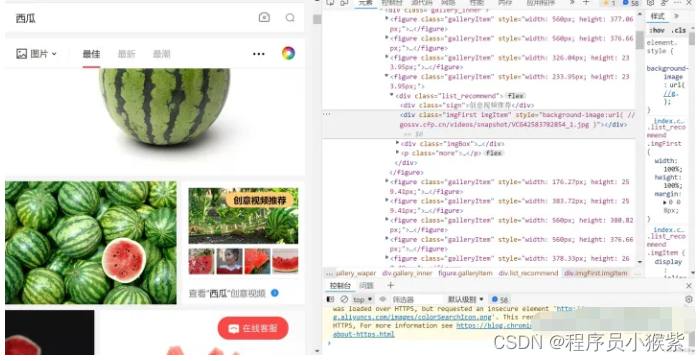
通过对网站的分析,我们发现图中创意视频推荐也在figure标签中,所以但其实际上没有a和img标签,所以匹配没有结果,导致程序直接报错停止。
这里采用try…expect…语句让程序遇到此类报错时直接跳过
try:
img_src = figure.xpath('./a/img/@data-src')[0]
except(IndexError):
print('未成功匹配到字段')
- 1
- 2
- 3
- 4
- 5
二、当匹配没有结果时,我们选择跳过,所以此时对图片数据申请时没有结果
try:
img_data = requests.get(url=img_src, headers=header).content
except(requests.exceptions.InvalidURL):
print('没有访问地址')
- 1
- 2
- 3
- 4
- 5
以上便是利用python网络爬虫对图片进行批量爬取,如果你对爬虫感兴趣,不妨以本文为案例,打开爬虫世界的大门。
完整代码
### 最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
#### 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/759125
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

