- 1vscode中集成gitbash注意事项_terminal.integrated.automationshell.linux (现已弃用)
- 2linux 简化版 设置ip地址,RHEL7.x版本,设置IP地址、网关和DNS的3种方法
- 3Android开源项目【Z_COMIC】---仿照腾讯漫画APP的实现_android开发一个漫画app
- 4《文本上的算法——深入浅出自然语言处理》读书笔记:第8章 理解语言有多难_自然语言处理 ontology
- 5PTA:7-135 过年了,回家吧 (35分)(天梯赛,dijkstra+解析)_python画97位乘客的回家路线
- 6【毕业设计/课程设计】基于php的博客系统设计与实现(源码+文章)_基于 php 的个人博客系统设计与开发
- 7【C++风云录】音频处理与音乐生成的C++库:解锁无限创意_c++ 音频处理
- 8微信小程序的四种弹框_微信小程序弹框
- 9DataStage总结_datastage lookup和join优先选哪个
- 10金三银四第一次面试,被阿里P8测开虐惨了...
机器学习第十六周周报
赞
踩
摘要
不同于VAE的简单高斯分布,flow-based生成模型用的是构造出来的较复杂的后验分布来表征。用一系列的可逆映射将原始分布转换成新的分布,最终达到将简单的高斯分布转换为复杂的真实后验分布的目的,就是用多个比较简单的生成器进行串联,来达到用简单的分布转换成复杂的分布的效果。
Abstract
Different from the simple Gaussian distribution of VAE, the flow-based generation model is characterized by a more complex posterior distribution. The original distribution is transformed into a new distribution by a series of reversible mappings, and finally the simple Gaussian distribution is converted into a complex real posterior distribution, that is, a series of relatively simple generators are used to achieve the effect of converting a simple distribution into a complex distribution.
一、Flow-based Generative Models
前面介绍的各个生成模型,都存在一定的问题:
- 对于PixelRNN这类模型来说,就是从左上角的像素开始一个个地进行生成,那么这个生成顺序是否合理,每一个像素是否只与它前面的像素有关,这就是其问题
- VAE的问题在前文就已经提到,它只能够学会模仿训练集中的例子,无法真正做到“创造”
- 对于GAN来说可能是生成方面最好的模型,但是实在是太难训练了
因此我们接下来要介绍的流形生成模型,就是用多个比较简单的生成器进行串联,来达到用简单的分布转换成复杂的分布的效果。
1.Generator
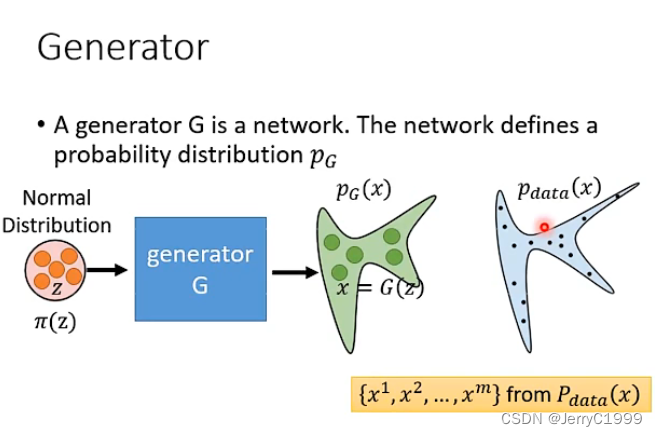
一般来说,生成器是一个神经网络,其定义了一个概率分布。例如我们有一个生成器G如下图,那么我们输入一个z,就可以得到输出x;而z我们可以看成是从简单的正态分布中采样得来的,而最终得到的x的分布则可以认为跟生成器G相关,因此定义该分布为PG(x)。这里可以将x称为观测变量,也就是我们实际能够得到的样本;将z称为隐变量,其对于样本的生成式至关重要的。因此可以认为观测变量x的真实分布为Pdata(x),如下图:
那么我们调整生成器的目的就是希望PG(x)和Pdata(x)能够越接近越好,即:
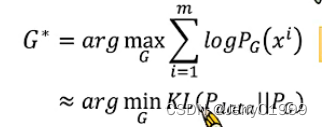
其中,xi是从Pdata中采样得到的。那么求解生成器G也就是极大似然的求解,也就是最大化每个样本被采样得到的概率,这相当于极小化那两个分布的KL散度,是满足我们的预期的。
2.Math Background
(1)Jacobian Matrix
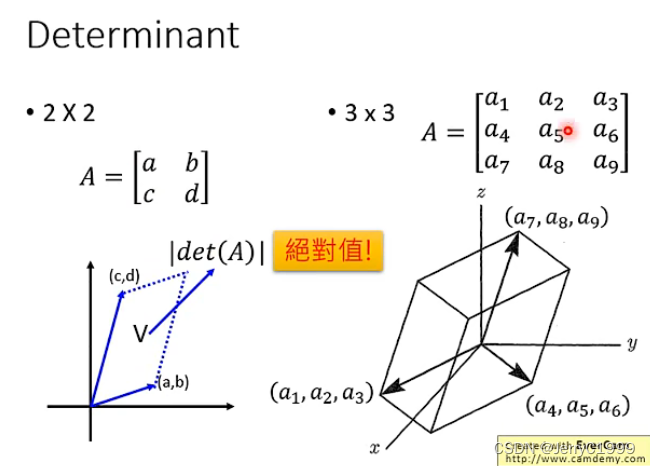
雅可比矩阵可以通过下图来简单理解:

将矩阵的每一行都当成一个向量,并在对应维度的空间中展开,那么形成的那个空间的“体积“就是行列式的绝对值,如下图的二维的面积和三维的体积:
(2)Change of Variable Theorem
根据前面的描述,我们已知了z的分布,假设当前也知道了x的分布,那么我们想要的是求出来生成器G,或者说求出来怎么从z的分布转换到x的分布,如下图:
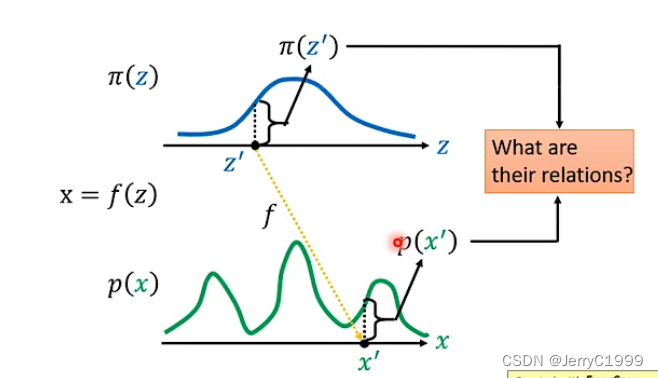
我们先从最简单的情形来介绍我们具体解决问题的方式。
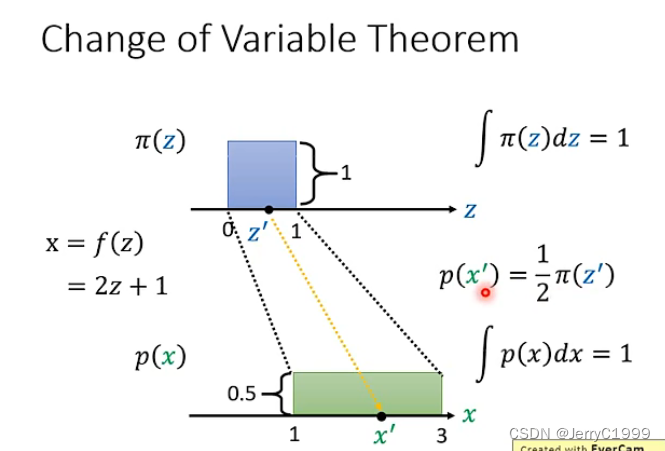
假设当前z满足的分布为一个0到1之间的均匀分布,而z和x之间的关系已知,为x=f(z)=2z+1,那么就可以得到下面的图形。而由于两者都是概率分布,因此两者的积分都应该为1(面积相同),因此可以解出来x的分布对应的高度为0.5。
那么假设z和x的分布都为更加复杂的情况,那我们可以在某点z′上取一定的增量Δz,那么对应映射到x的分布上就也有x′和Δx。那么假设Δz很小,可以使得在该段之内的p(z)都相同,p(x)也同理相等,再根据这两部分的面积相同即可得到:
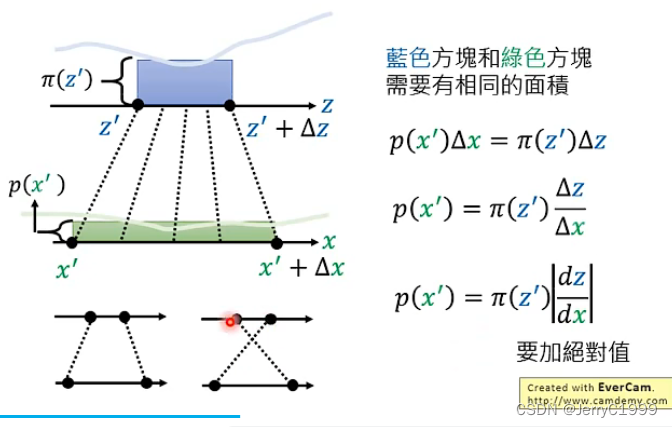
需要注意的是转换成微分之后需要加上绝对值,因为微分可正可负。
那么接下来拓展到二维空间,假设当前的π(z′)处对于两个方向都进行了增量,那么映射到x之中将会有四个增量:其中Δx11表示z1改变的时候x1的改变量,Δx12表示z1改变的时候x2的改变量,以此类推,因此在x的空间中就扩展为一个菱形。
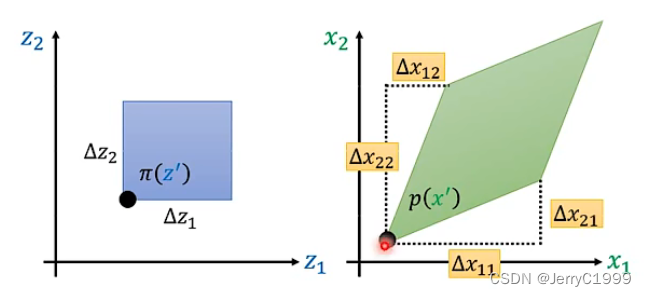
那么它们之间存在的关系从面积相等拓展到了体积相等,即:
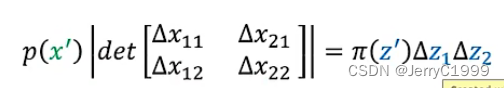
也就是两个图形的面积和在对应点的取值的乘积相等。那么对上式进行推导:

3.Flow-based Model
经过上面的各种推导,我们可以将目标函数进行转换:
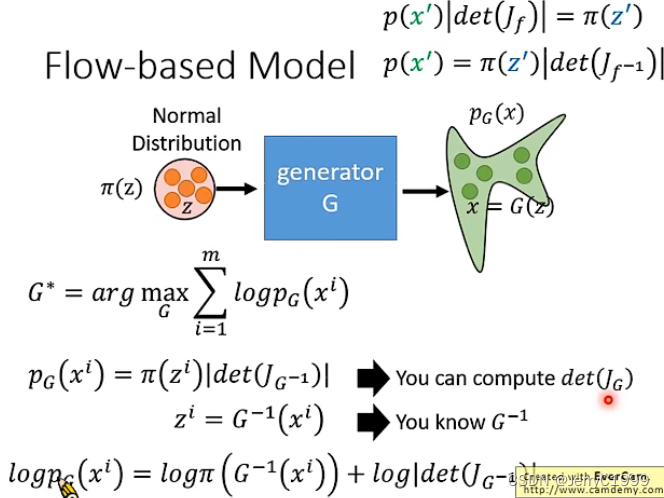
而我们如果要最大化最下面的式子,我们首先需要知道怎么算雅克比矩阵的行列式,这在当矩阵的大小很大的时候是非常耗时的;其次是要知道怎么算生成器G的逆G−1,这个会要求输入的维度和输出的维度必须是一样的,因此我们要巧妙地设计网络的架构,使其能够方便计算雅克比矩阵的行列式和生成器的逆G−1。而在实际的Flow-based Model中,G可能不止一个。因为上述的条件意味着我们需要对G加上种种限制。那么单独一个加上各种限制就比较麻烦,我们可以将限制分散于多个G,再通过多个G的串联来实现,这也是称为流形的原因之一:
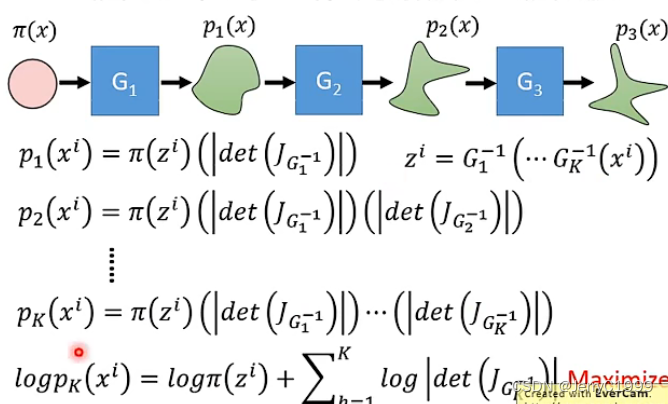
因此要最大化的目标函数也变成了:
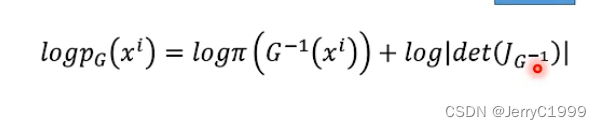
可以发现上述要最大化的目标函数中只有G−1,因此在训练的时候我们可以只训练G−1,其接受x作为输入,输出为z;而在训练完成后就将其反过来,接受z作为输入,输出为x。
因为我们在训练的时候就会从分布中采样得到x,然后代入得到z,并且根据最大化上式来调整G−1。那么如果只看上式的第一项,因为π(t)是正态分布,因此当t取零向量的时候其会达到最大值,因此如果只求第一项的最大化的话会使得我们输出的z向量都变成零向量。但是这会导致雅克比矩阵全为0(因为z都是零向量,因此没有变化的梯度),那么第二项将会冲向负无穷,因此这两项之间是相互约束的关系!第一项使得所有的z向量都往零向量附近靠近,第二项使得z向量都全部为零向量。
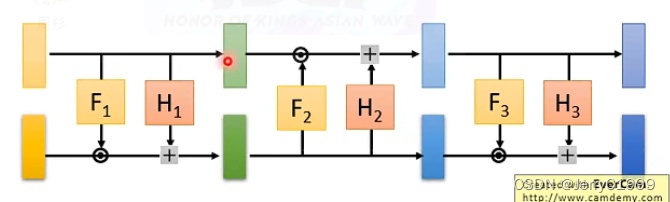
4.Coupling Layer
为了能够方便计算雅克比矩阵,因此我们采用Coupling Layer这种思想,即我们假设z和x之间满足这种关系:
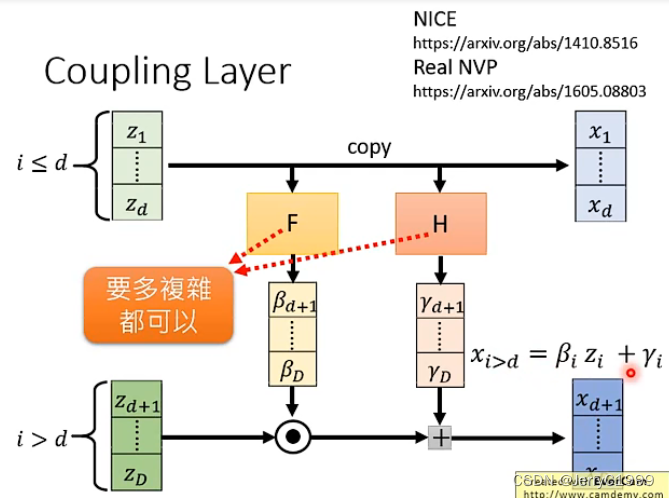
其中F和H是两个函数,进行向量的变换而已,它有多复杂都是可以的。而上图是正向的过程,因为我们训练的时候是训练G-1,因此我们需要负向的过程,即如下:
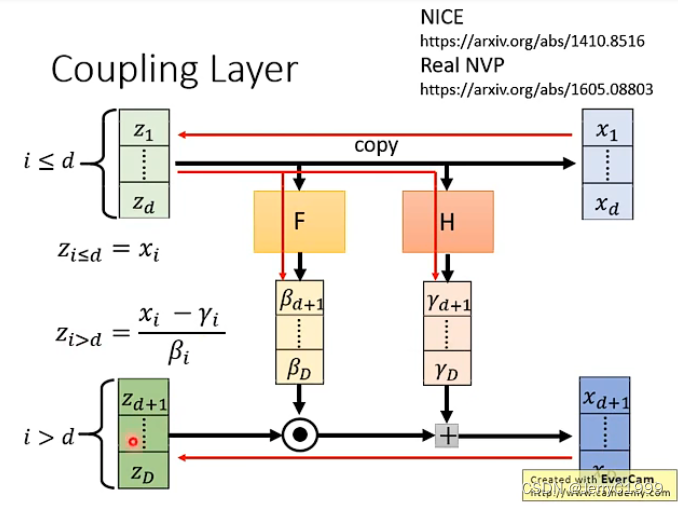
因此满足了上述关系之后,雅克比矩阵的计算就变得很方便了:
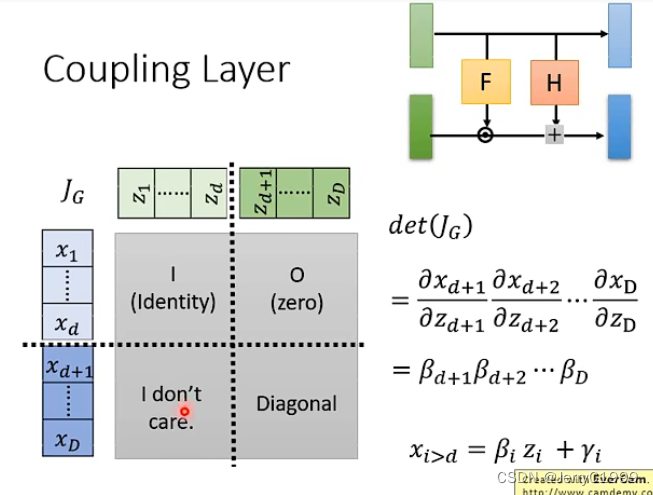
首先解释一下为什么左下角那个复杂的块矩阵我们不用注意:因为右上角是零矩阵,因此在计算行列式的时候只会关注右下角矩阵的值而不会管左下角矩阵的值是多少。
因此对于这种关系的变换我们就可以很方便的求出雅克比矩阵行列式的值。
再接下来我们就可以将多个Coupling Layer串在一起,但如果正向直接串的话就会发现前d维度的值是直接拷贝的,从头到尾都相同,这并不是我们想要的结果,我们不是希望前d维度的值一直保持不变:
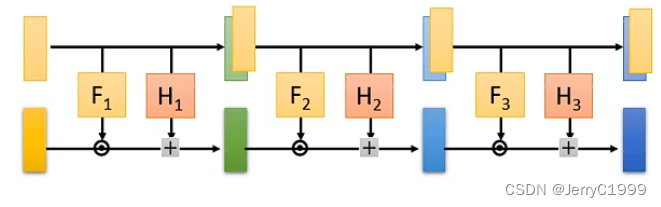
那么可能的解决办法是反向串: