
- 1这 5 个实用的 Python 库,你必须要试试!_python实用库
- 2JAVADS——快速排序
- 3H5实现手机扫描二维码识别_h5扫码识别
- 4分布式接口文档聚合,Solon 是怎么做的?
- 5Zookeeper分布式锁的原理_zk锁原理
- 6Python描述 LeetCode 67. 二进制求和_letcode二进制求和python
- 7【小白专用24.6.8】c#异步方法 async task调用及 await运行机制_c# async task using
- 8大数据之Hive(四):Hive计算引擎_hive是一个计算引擎吗
- 9mongodb创建数据库和配置用户
- 10hbase导出数据为文本,csv,html等文件_hbase org.apache.hadoop.hbase.mapreduce.export
基于PPO的强化学习超级马里奥自动通关_ppo马里奥
赞
踩
目录
本文将基于强化学习中的PPO算法训练一个自动玩超级马里奥的智能体,用于强化学习的项目实践
源码及底模放于文末(可自行取用)
一、环境准备
所需环境如下:
- pip install nes-py
- pip install gym-super-mario-bros
- pip install setuptools==65.5.0 "wheel<0.40.0"
- pip install gym==0.21.0
- pip install stable-baselines3【extra】==1.6.0
- pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
注意: 在环境配置方面,nes-py库安装的先决条件是 安装Microsoft Visual C++,其下载地址为:Microsoft C++ Build Tools - Visual Studio
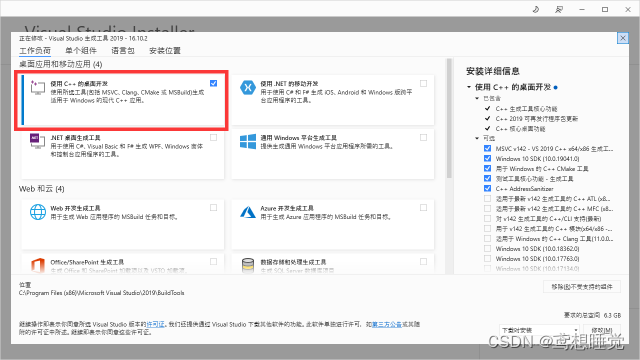
在安装Microsoft Visual C++时需选择桌面开发:
二、训练思路
1.训练初期:
使用了最简单的训练框架,并选择PPO算法中较简单的的CnnPolicy网络(可以尝试MlpPolicy和MultiInputPolicy网络,我没试是因为太懒了)以及马里奥操控中的SIMPLE_MOVEMENT操作模块:

自然,效果是不尽人意的,马里奥在所选关卡的第三根水管处(即最高的那个水管)不断尝试跳跃,直至时间耗尽也未能通过。
2.思路整理及改进:
思路一:
既然训练效果不佳,是否跟训练轮数有关?固将总训练轮数增加至3000000,并尝试训练。跑出来的模型有所改进,马里奥在成功越过所有水管后,遇到了新的难题——越过两个断崖。至此,无论如何增加轮数,马里奥似乎到了一个瓶颈,固继续进行修改。
思路二:
在增加训练轮数的基础上,选择对关卡的环境图像进行预处理——使用GrayScaleObservation转换为灰度观察,并保留通道维度。同时,我们对训练参数进行调整:
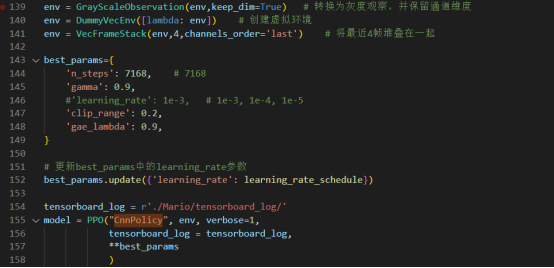
尝试训练后,能够得到一个不稳定越过断崖的新模型,但对断崖之后的环境似乎有些陌生,陷入了前半段关卡的“局部最优解”。
思路三:
由于之前的训练过程中使用了较小的学习率(1e-9),进而使得马里奥在关卡中陷入了局部最优,所以选择对学习率进行微调,使其在最开始的训练阶段使用较大的学习率,在后期减小学习率,从而达到先快速探索参数空间并加速收敛,再提高模型的稳定性和收敛精度。

至此,训练出来的测试模型,奖励反馈有所增长,但实际测试效果与调整前相差不多。
思路四:
在上述尝试无明显效果后,猜测效果的好坏是否与马里奥的奖励机制有关,固在查阅奖励部分代码后,对“抵达终点”的奖励予以提高,希望对效果有所改善。
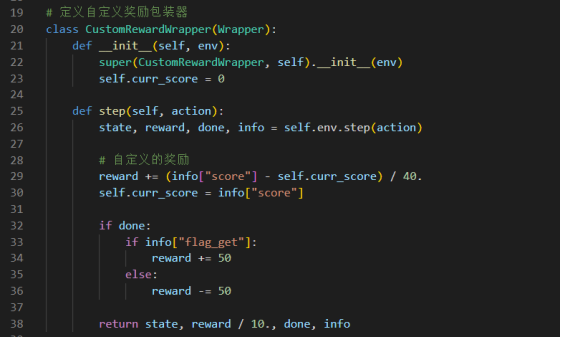
然结果并没有明显改观,更换调整方向。分别尝试马里奥的三套运动方式:
![]()
经过对比,complex_movement的效果远超另外两套,且在前面思路的改动下模型质量有显著提升,固整理上述调整方案,进行底模训练。
3.训练效果:
以奖励折扣率gamma = 0.9、gae_lambda = 0.9、clip_range = 0.2、步长n_steps = 7168,并用1e-3作为开始训练的学习率,并在训练过程中使其动态地在1e-5,1e-7中调整,修改抵达终点的奖励反馈,同时设置训练轮数为4000000,训练动作组为complex_movement进行训练。得到基础奖励回报为1520的底模,并将其继续用于迁移学习,得到2300的新模型。在实际测试后发现,模型确有改观,固继续将新模型用于训练,最终得到3200的最终模型,其能顺利到达终点并进入关卡的下一阶段。
三、结果分析
与之前的训练经验相比,使用复杂的动作组未必比简单的动作组训练出的效果差,学习率的调整也是必要的,先用较大学习率打好基础,再有小学习率继续细化模型。同时,要给足够的训练轮数(足够的训练时间)。若是能够把奖励机制更进一步细化增加奖励细节,对其的训练是会更有帮助的。
四、完整代码
训练代码:
- from nes_py.wrappers import JoypadSpace
- import time
- import os
- import numpy as np
- from datetime import datetime
- from matplotlib import pyplot as plt
- import gym_super_mario_bros
- from gym_super_mario_bros.actions import SIMPLE_MOVEMENT, COMPLEX_MOVEMENT, RIGHT_ONLY
- from gym.wrappers import GrayScaleObservation
- from gym import Wrapper
- from stable_baselines3.common.monitor import Monitor
- from stable_baselines3.common.vec_env import DummyVecEnv
- from stable_baselines3.common.vec_env import VecFrameStack
- from stable_baselines3 import PPO
- from stable_baselines3.common.results_plotter import load_results, ts2xy
- from stable_baselines3.common.callbacks import BaseCallback
-
-
- # 定义自定义奖励包装器
- class CustomRewardWrapper(Wrapper):
- def __init__(self, env):
- super(CustomRewardWrapper, self).__init__(env)
- self.curr_score = 0
-
- def step(self, action):
- state, reward, done, info = self.env.step(action)
-
- # 自定义的奖励
- reward += (info["score"] - self.curr_score) / 40.
- self.curr_score = info["score"]
-
- if done:
- if info["flag_get"]:
- reward += 50
- else:
- reward -= 50
-
- return state, reward / 10., done, info
-
-
- class SaveOnBestTrainingRewardCallback(BaseCallback):
- """
- Callback for saving a model (the check is done every ``check_freq`` steps)
- based on the training reward (in practice, we recommend using ``EvalCallback``).
- :param check_freq: (int)
- :param log_dir: (str) Path to the folder where the model will be saved.
- It must contains the file created by the ``Monitor`` wrapper.
- :param verbose: (int)
- """
-
- def __init__(self, check_freq, save_model_dir, verbose=1):
- super(SaveOnBestTrainingRewardCallback, self).__init__(verbose)
- self.check_freq = check_freq
- self.save_path = os.path.join(save_model_dir, './')
- self.best_model_subdir = os.path.join(self.save_path, 'best_model')
- self.best_mean_reward = -np.inf
- self.best_model_path = None
- self.best_score_model_path = os.path.join(self.save_path, 'pass_customs_model.zip') # 增加通关模型路径
-
- # def _init_callback(self) -> None:
- def _init_callback(self):
- # Create folder if needed
- if self.save_path is not None:
- os.makedirs(self.save_path, exist_ok=True)
-
- # def _on_step(self) -> bool:
- def _on_step(self):
- if self.n_calls % self.check_freq == 0:
- print('self.n_calls: ', self.n_calls)
- model_path1 = os.path.join(self.save_path, 'model_{}'.format(self.n_calls))
- self.model.save(model_path1)
- # Save the best model
- x, y = ts2xy(load_results(monitor_dir), 'timesteps')
- if len(x) > 0:
- mean_reward = np.mean(y[-self.check_freq:])
- if self.verbose > 0:
- print("Num timesteps: {}, Best mean reward: {:.2f}, Last mean reward: {:.2f}".format(
- self.n_calls, self.best_mean_reward, mean_reward))
-
- if mean_reward > self.best_mean_reward:
- if self.best_model_path is not None:
- try:
- os.remove(self.best_model_path) # Delete the old best model
- except OSError:
- pass
- self.best_mean_reward = mean_reward
- # Update path for the new best model
- self.best_model_path = os.path.join(self.save_path, 'best_model.zip')
- # Save the new best model
- self.model.save(self.best_model_path)
-
- if self.verbose > 0:
- print("New best mean reward: {:.2f} - saving best model".format(mean_reward))
-
- # Save the best mean reward to a file
- reward_record_file = './Mario_model_save/model/mario_model/best_mean_reward.txt'
- with open(reward_record_file, 'a') as file:
- # 将最佳平均奖励值和时间戳一同写入文件
- file.write(
- "New best mean reward: {:.2f} - Recorded at {}\n".format(mean_reward, datetime.now()))
-
-
- return True
-
-
- # 总的训练timesteps
- my_total_timesteps = 4000000
- # 需要改变学习率的timestep
- change_lr_timestep = 2000000
-
-
- # 学习率调度函数
- def learning_rate_schedule(progress_remaining):
- """
- 参数 progress_remaining 表示剩下的训练进度(从1开始降低到0)。
- 通过训练进度来动态调整学习率。
- """
- current_timestep = my_total_timesteps * (1 - progress_remaining)
- if current_timestep < change_lr_timestep:
- return 1e-3 # 1e-3
- elif change_lr_timestep <= current_timestep <= int(change_lr_timestep * 1.5):
- return 1e-5
- else:
- return 1e-7
-
-
- env = gym_super_mario_bros.make('SuperMarioBros-1-2-v0')
- env = JoypadSpace(env, COMPLEX_MOVEMENT) # 使用复杂的按键映射
-
- env = CustomRewardWrapper(env) # 应用自定义奖励包装器
-
- monitor_dir = r'./Mario_model_save/monitor_log/'
- os.makedirs(monitor_dir, exist_ok=True)
- env = Monitor(env, monitor_dir) # 将环境包装为监视器
-
- env = GrayScaleObservation(env, keep_dim=True) # 转换为灰度观察,并保留通道维度
- env = DummyVecEnv([lambda: env]) # 创建虚拟环境
- env = VecFrameStack(env, 4, channels_order='last') # 将最近4帧堆叠在一起
-
- best_params = {
- 'n_steps': 7168, # 7168
- 'gamma': 0.9,
- # 'learning_rate': 1e-3, # 1e-3, 1e-4, 1e-5
- 'clip_range': 0.2,
- 'gae_lambda': 0.9,
- }
-
- # 更新best_params中的learning_rate参数
- best_params.update({'learning_rate': learning_rate_schedule})
-
- tensorboard_log = r'./Mario_model_save/tensorboard_log/'
- # 正常训练
- model = PPO("CnnPolicy", env, verbose=1,
- tensorboard_log=tensorboard_log,
- **best_params
- )
- '''
- # 加载预训练模型
- pretrained_model_path = r'D:\python_project\Mario\model\mario_model\pretraining_model_4.zip'
- model = PPO.load(pretrained_model_path, env=env, tensorboard_log=tensorboard_log, **best_params)'''
-
- # 保存模型位置
- save_model_dir = r'./Mario_model_save/model/mario_model/'
- callback1 = SaveOnBestTrainingRewardCallback(10000, save_model_dir)
-
- model.learn(total_timesteps=my_total_timesteps, callback=callback1)
- # model.save("mario_model")

测试代码:
- from nes_py.wrappers import JoypadSpace
- import gym_super_mario_bros
- from gym_super_mario_bros.actions import SIMPLE_MOVEMENT, RIGHT_ONLY, COMPLEX_MOVEMENT
- import time
- from matplotlib import pyplot as plt
- from gym.wrappers import GrayScaleObservation
- from stable_baselines3.common.monitor import Monitor
- from stable_baselines3.common.vec_env import DummyVecEnv
- from stable_baselines3.common.vec_env import VecFrameStack
- import os
- from stable_baselines3 import PPO
-
- from stable_baselines3.common.results_plotter import load_results, ts2xy
- import numpy as np
- from stable_baselines3.common.callbacks import BaseCallback
-
- env = gym_super_mario_bros.make('SuperMarioBros-v0')
- env = JoypadSpace(env, COMPLEX_MOVEMENT)
-
- monitor_dir = r'./Mario/monitor_log/'
- os.makedirs(monitor_dir, exist_ok=True)
- env = Monitor(env, monitor_dir)
-
- env = GrayScaleObservation(env, keep_dim=True)
- env = DummyVecEnv([lambda: env])
- env = VecFrameStack(env, 4, channels_order='last')
-
- save_model_dir = r'model/mario_model/pretraining_model_5.zip'
- # save_model_dir = r'./Mario/model/mario_model/pretraining_model.zip'
-
-
- model = PPO.load(save_model_dir)
-
- obs = env.reset()
- obs = obs.copy()
- done = True
- while True:
- if done:
- state = env.reset()
- action, _states = model.predict(obs)
- obs, rewards, done, info = env.step(action)
- obs = obs.copy()
- # time.sleep(0.01)
- env.render()
-
- env.close()
底模:
最优底模为pretraining_model_5
链接:https://pan.baidu.com/s/1ed9IfgqvPC-uJmbGZMZtMQ?pwd=ru3t
提取码:ru3t

