
- 1HarmonyOS/OpenHarmony应用开发-HDC环境变量设置_hdc环境变量配置
- 2RabbitMQ的远程Web管理与监控工具_mqviewer
- 3cocos2dx lua中异步加载网络图片,可用于显示微信头像
- 4分享一个好用的AI 动漫图片工具 - AI Anime Generator,输入文字,1分钟生成动漫图片_AI绘画工具
- 5error pulling image configuration: Get https://registry-1.docker.io/v2/library/redis/blobs/sha256:7e_github error pulling image configuration
- 6速盾:如何评估 CDN 对网络安全的影响?
- 7springboot引入kafka
- 8RabbitMQ的Windows版安装教程_windows安装rabbitmq
- 9TON区块链之Hello World_ton钱包 连接 api
- 10idea 把一个git分支的部分提交记录合并到当前分支上比较两个分支的代码区别_idea将其它分支上的部分合并到当前分支
C# 网络爬虫+HtmlAgilityPack+Xpath+爬虫工具类的封装的使用_c# xpath
赞
踩
目录
1 工具准备
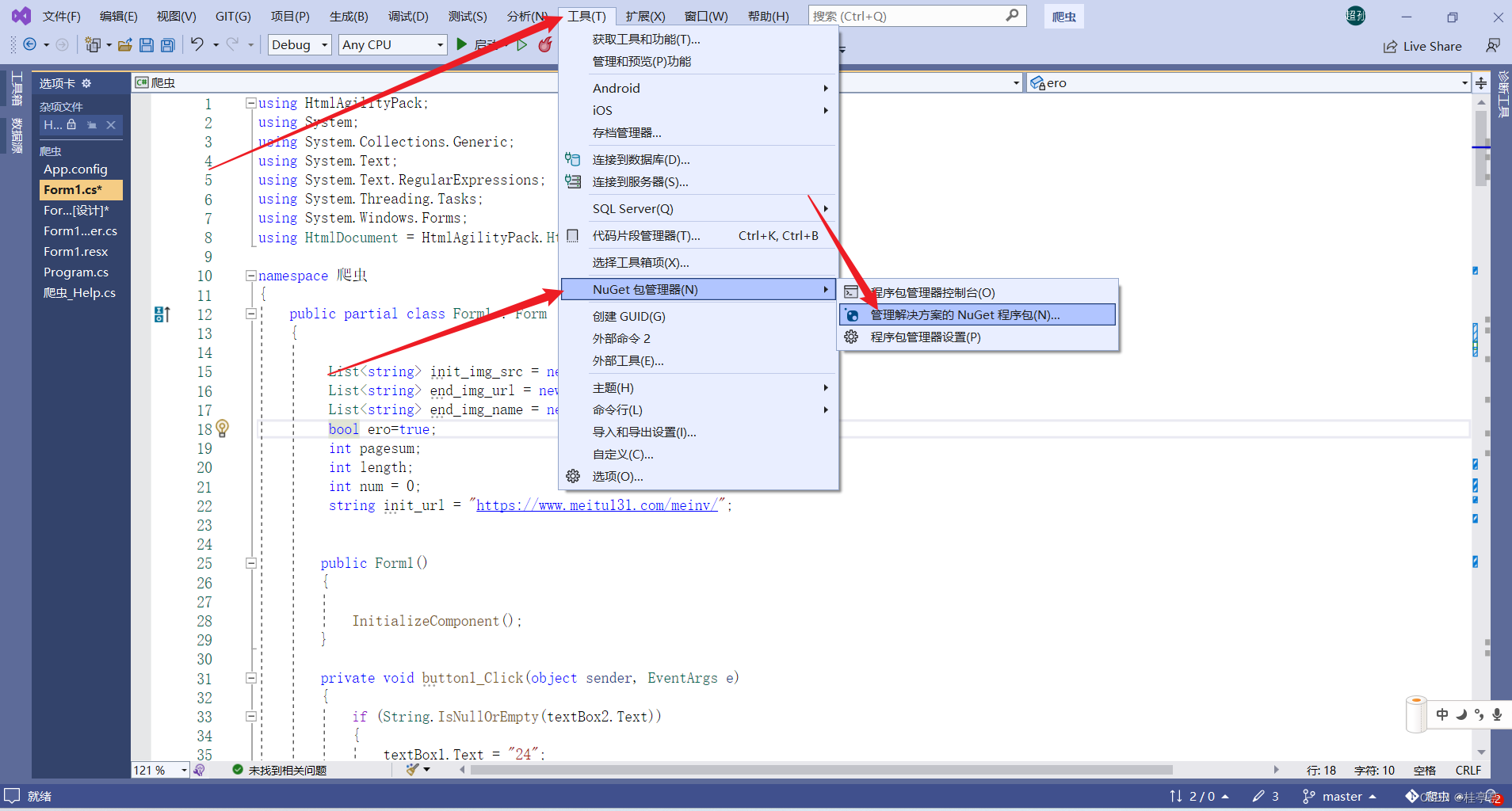
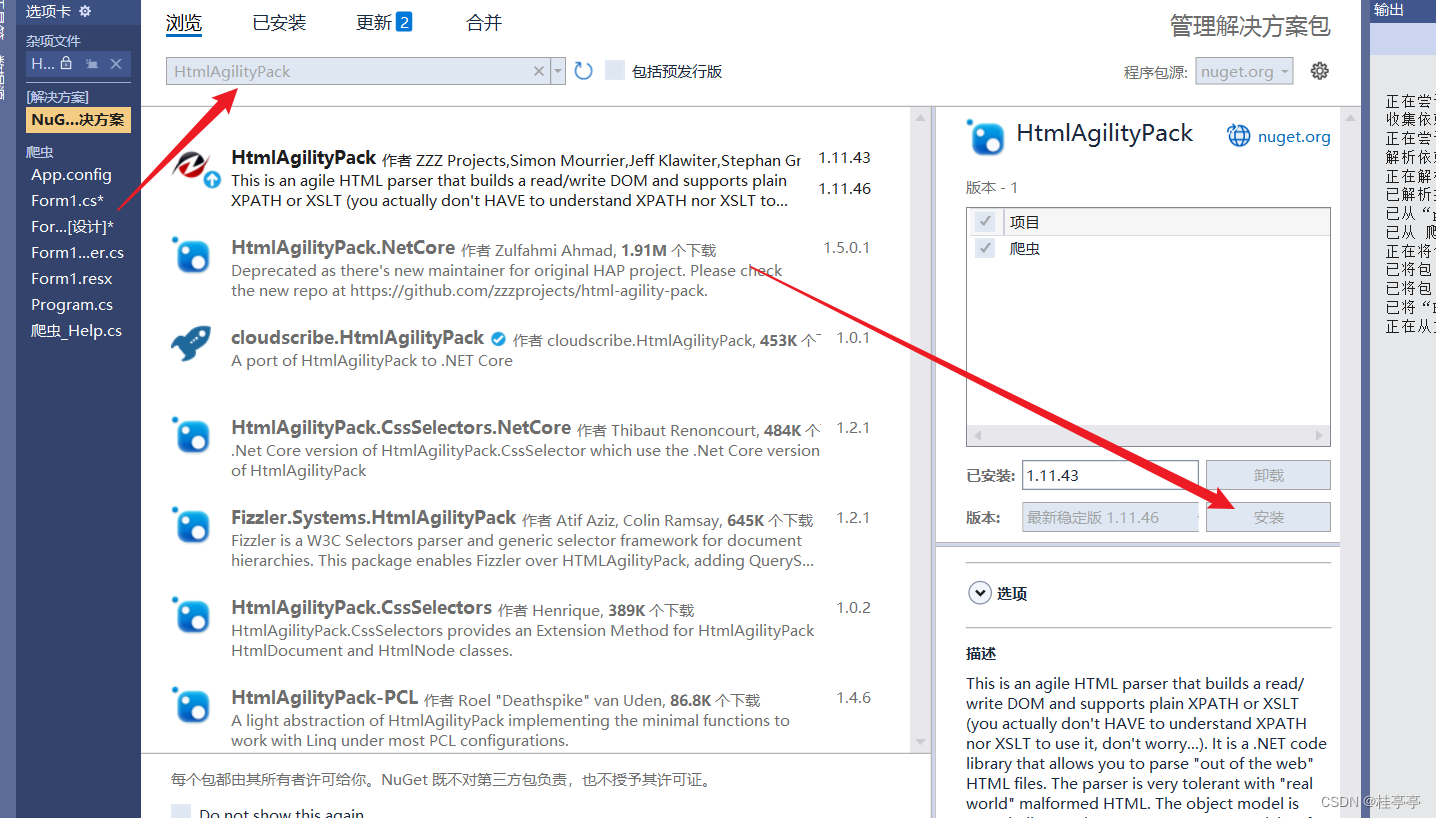
1 Visual Studio 需要安装包 HtmlAgilityPack
2 命名空间的引入
在新建的程序头顶加入
3 注备好一双可以复制粘贴的小手,和一个还能跑的电脑,咯咯~
2 思路准备
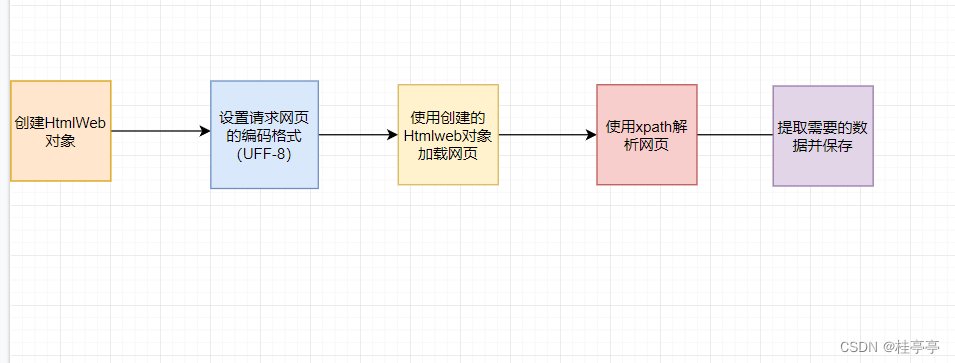
图我已经给各位画好了,请参看
3 附加知识准备——XPath
简述
XPath 是一门在 XML 文档中查找信息的语言,虽然是被设计用来搜寻 XML 文档的,但是它也能应用于 HTML 文档,并且大部分浏览器也支持通过 XPath 来查询节点。在 Python 爬虫开发中,经常使用 XPath 查找提取网页中的信息,因此 XPath 非常重要。
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是沿着路径(path)或者步(steps)来选取的。接下来介绍如何选取节点,首先了解一下常用的路径表达式,来进行节点的选取,如下表所示:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 选择任意位置的某个节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
看看例子
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
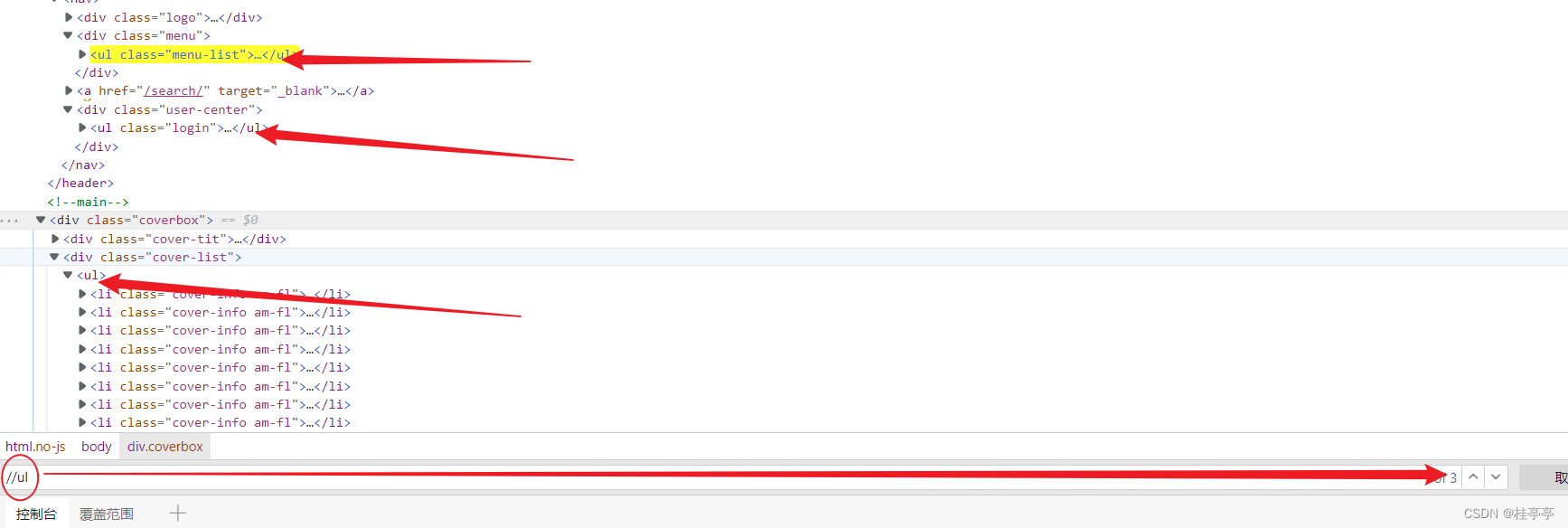
用XPath来寻找标签
获取所有同名的标签
我们只需要用: //标签名
即可,比如看下图我们使用了//ul寻找到了所有名为ul的标签了
获取指定标签
那么我们想要去选取具体的那个标签怎么办那?
有童鞋可能会想到,直接加下表访问但是!!在有时候是行不通的,
很简单,我们先将获取的的所以ul块对象存在数组中,然后使用下标访问就好了
只是这些我们要在C#中进行操作了,不能直接在网络控制台上进行操作了,咯咯~
/html/body/div[1]/div[2]/ul一个实例
我们使用这串Xpath代码就可以获取到所有在指定位置下的li标签了
/html/body/div[1]/div[2]/ul/li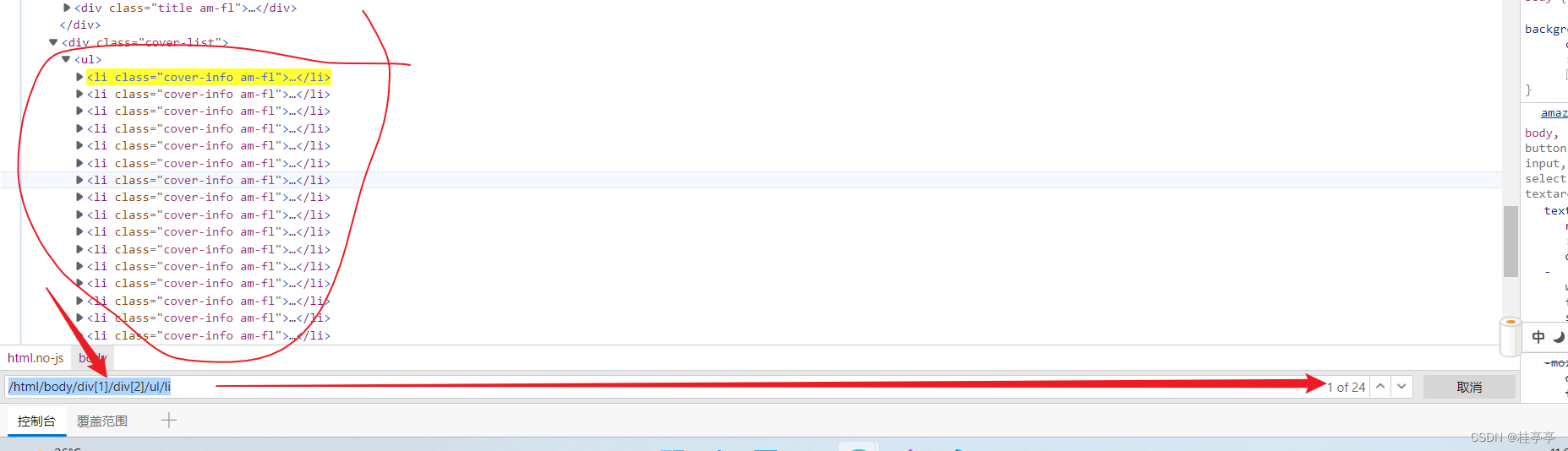
最后的补充
XPath 在进行节点选取的时候可以使用通配符*匹配未知的元素,同时使用操作符|一次选取多条路径,使用示例如下表所示。
| XPath路径表达式 | 含义 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素 |
| //* | 选取文档中的所有元素 |
//title[@*] | 选取所有带有属性的 title 元素 |
| //book/title 丨 //book/price | 选取 book 元素的所有 title 和 price 元素 |
| //title 丨 //price | 选取文档中的所有 title 和 price 元素 |
| /bookstore/book/title 丨 //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素 |
4 代码实现
其实有了上面的基础知识,就可以自由发挥了,我这里抛砖引玉一下。
我们以美女图片大全_高清美女图片_性感美女写真_极品美女图片 - 美图131为例对MV图片的源地址,以及标签进行提取。
以下代码我们只用理解逻辑以及方法即可,可能也有很多漏洞与BUG,但这些不是重点滴!
- public void getdata()
- {
- //----全网首发----//
-
- //建立实例化htmlweb对象用于加载,处理网页
- HtmlWeb htmlWeb = new HtmlWeb();
- //设置为Encoding.UTF8编码,防止乱码
- htmlWeb.OverrideEncoding = Encoding.UTF8;
-
- //初始化网页地址
- String init_url = @"https://www.meitu131.com/meinv/";
-
- 加载网页返回值为HtmlDocument类型,用var也行,哈哈
- HtmlDocument htmlDoc = htmlWeb.Load(init_url);
-
- //打印一下网页的HTML文档,看看效果
- //Console.WriteLine(htmlDoc.Text);
- //使用XPath定位元素
- string xpath = "";
- string init_xpath = "/html/body/div[1]/div[2]/ul/li";
-
- //获取本页所有li的节点数目,这便是本页图集的个数
- int new_page_sum = htmlDoc.DocumentNode.SelectNodes(init_xpath).Count;
- //对每个li节点进行提取,并拼接图集的网址
- for (int a_ = 0; a_ < new_page_sum; a_++)
- {
- xpath = "/html/body/div[1]/div[2]/ul/li[" + (a_ + 1) + "]/div[1]/a";
- init_img_src.Add("https://www.meitu131.com" + htmlDoc.DocumentNode.SelectSingleNode(xpath).Attributes["href"].Value.ToString());
- }
- //对每一页进行遍历,获取
- for (int b_ = 0; b_ < new_page_sum; b_++)
- {
- string temp_src = @init_img_src[b_];
- string temp_paxth_ = "//*[@id='main-wrapper']/div[2]/p/a/img";
- string temp_paxth = "//*[@id='pages']/a[1]";
- HtmlDocument htmlDoc_1 = htmlWeb.Load(temp_src);
- string c = htmlDoc_1.DocumentNode.SelectSingleNode(temp_paxth).InnerHtml.ToString();
-
- //获取当前图集所有页数page_sum[1]
- String[] page_sum = c.Split('/');
- for (int c_ = 0; c_ < 1; c_++)
- {
- string temp_url;
- if (c_ == 0)
- {
- temp_url = temp_src + "index.html";
-
- }
- else
- {
- temp_url = temp_src + "index_" + (c_ + 1) + ".html";
- }
-
- HtmlDocument htmlDoc_2 = htmlWeb.Load(temp_url);
- end_img_url.Add(htmlDoc_1.DocumentNode.SelectSingleNode(temp_paxth_).Attributes["src"].Value.ToString());
- end_img_name.Add(htmlDoc_1.DocumentNode.SelectSingleNode(temp_paxth_).Attributes["alt"].Value.ToString());
- }
- }
- textBox1.AppendText("数据获取完成,开始保存文件......");
- }

5 爬虫工具类的封装
为了更方便的爬虫,我对常用的方法进一步进行了封装,开箱即用。
- using System;
- using System.Collections.Generic;
- using System.Linq;
- using System.Text;
- using System.Threading.Tasks;
- using System.Net;
- using System.IO;
- using System.Diagnostics;
- using HtmlAgilityPack;
- using System.Net.Http;
-
- namespace 爬虫
- {
- public static class pc_Help
- {
- /// <summary>
- /// Url网络资源下载
- /// </summary>
- /// <param name="Download_Path">下载地址</param>
- /// <param name="resource_name">资源名列表</param>
- /// <param name="resource_url">资源Url列表</param>
- /// <param name="Download_Type">下载文件后缀(不加.)</param>
- /// <returns> 毫秒运行时间 float</returns>
- public static string Download_Url(string Download_Path, List<string> resource_name, List<string> resource_url, string Download_Type)
- {
- try
- {
- string Download_Path_ = Download_Path;
- Stopwatch sw = new Stopwatch();
- sw.Start();
-
- int len = resource_name.Count;
- int num = 0;
-
- WebClient wb = new WebClient();
- DirectoryInfo info = new DirectoryInfo(Download_Path_);
- if (!info.Exists)
- {
- Directory.CreateDirectory(Download_Path_);
- }
- for (int d_ = 0; d_ < len; d_++)
- {
- Download_Path = $@"{Download_Path_}\{(num + 1)}{resource_name[d_]}.{Download_Type}";
-
- num++;
- wb.DownloadFile(resource_url[d_], Download_Path);
- }
- sw.Stop();
- return $"文件保存完成!耗时:{sw.ElapsedMilliseconds/1000}s\r\n";
- }
- catch (Exception e)
- {
- throw new Exception("保存数据出错", e);
- }
- }
-
- /// <summary>
- /// 从Url地址下载HTML页面
- /// </summary>
- /// <param name="url"></param>
- /// <returns></returns>
- public async static ValueTask<HtmlDocument> LoadHtmlFromUrlAsync(string url)
- {
-
- //如果web不是空就异步下载html文档
- HtmlWeb web = new HtmlWeb();
- web.OverrideEncoding = Encoding.UTF8;
- return await web?.LoadFromWebAsync(url);
- }
-
- /// <summary>
- /// 获取单个节点的扩展方法
- /// </summary>
- /// <param name="htmlDocument">文档对象</param>
- /// <param name="xPath">xPath路径</param>
- /// <returns></returns>
- public static HtmlNode GetSingleNode(this HtmlDocument htmlDocument, string xPath)
- {
- return htmlDocument?.DocumentNode?.SelectSingleNode(xPath);
- }
-
- /// <summary>
- /// 获取单个节点扩展方法
- /// </summary>
- /// <param name="htmlDocument">文档对象</param>
- /// <param name="xPath">xPath路径</param>
- /// <returns></returns>
- public static HtmlNode GetSingleNode(this HtmlNode htmlNode, string xPath)
- {
- return htmlNode?.SelectSingleNode(xPath);
- }
-
-
- /// <summary>
- /// 获取多个节点扩展方法
- /// </summary>
- /// <param name="htmlDocument">文档对象</param>
- /// <param name="xPath">xPath路径</param>
- /// <returns>一个列表</returns>
- public static HtmlNodeCollection GetNodes(this HtmlDocument htmlDocument, string xPath)
- {
- return htmlDocument?.DocumentNode?.SelectNodes(xPath);
- }
-
- /// <summary>
- /// 获取多个节点扩展方法
- /// </summary>
- /// <param name="htmlDocument">文档对象</param>
- /// <param name="xPath">xPath路径</param>
- /// <returns>一个列表</returns>
- public static HtmlNodeCollection GetNodes(this HtmlNode htmlNode, string xPath)
- {
- return htmlNode?.SelectNodes(xPath);
- }
-
-
- /// <summary>
- /// 下载图片
- /// </summary>
- /// <param name="url">地址</param>
- /// <param name="filpath">文件路径</param>
- /// <returns>存在即覆盖</returns>
- ///
- //同步完成时的ValueTask<TResult>,<>里可以是任何类型
- public async static ValueTask<bool> DownloadImg(string url, string filpath)
- {
- HttpClient hc = new HttpClient();
- try
- {
- //字节流异步写入
- var bytes = await hc.GetByteArrayAsync(url);
- //存在即覆盖
- using (FileStream fs = File.Create(filpath))
- {
- fs.Write(bytes, 0, bytes.Length);
- }
- return File.Exists(filpath);
- }
- catch (Exception ex)
- {
-
- throw new Exception("下载图片异常", ex);
- }
-
- }
-
-
- }
- }
6 使用爬虫工具类爬虫
这边给个例子,还是以我们以美女图片大全_高清美女图片_性感美女写真_极品美女图片 - 美图131为例
以下代码我们只用理解逻辑以及方法即可,可能也有很多漏洞与BUG,但这些不是重点滴!
- public async ValueTask<bool> getdata_()
- {
- try
- {
- HtmlDocument html_3 = await pc_Help.LoadHtmlFromUrlAsync(init_url);
- string stack_all_page_sum_string = pc_Help.GetSingleNode(html_3, "//*[@id='pages']/a[11]").Attributes["href"].Value.ToString();
- //正则匹配全站所有图集的个数
- Regex regex = new Regex(@"\d{2}");
- int stack_all_page_sum_int = Convert.ToInt32(regex.Match(stack_all_page_sum_string).ToString());
- if (pagesum < 24)
- {
- HtmlDocument htmlDoc;
- htmlDoc = await pc_Help.LoadHtmlFromUrlAsync(init_url);
- string xpath = "";
- //获取此页面上(具有多个图集封面的页面)的所有图集的初始页的数目
- int new_page_sum = pc_Help.GetNodes(htmlDoc, "/html/body/div[1]/div[2]/ul/li").Count;
- //拼接当前页面上(具有多个图集封面的页面)的所有图集的初始页的地址
- for (int a_ = 0; a_ < pagesum; a_++)
- {
- xpath = "/html/body/div[1]/div[2]/ul/li[" + (a_ + 1) + "]/div[1]/a";
- init_img_src.Add("https://www.meitu131.com" + pc_Help.GetSingleNode(htmlDoc, xpath).Attributes["href"].Value.ToString());
- }
-
- for (int b_ = 0; b_ < pagesum; b_++)
- {
- string temp_src = @init_img_src[b_];
- string temp_paxth_ = "//*[@id='main-wrapper']/div[2]/p/a/img";
- string temp_paxth = "//*[@id='pages']/a[1]";
- HtmlDocument htmlDoc_1 = await pc_Help.LoadHtmlFromUrlAsync(temp_src);
- string c = pc_Help.GetSingleNode(htmlDoc_1, temp_paxth).InnerHtml.ToString();
- //获取本图集所有页数page_sum[1]
- string[] page_sum = c.Split('/');
- //Convert.ToInt32(page_sum[1])
- //每个图集页面的拼接,与请求保存图片
- for (int c_ = 0; c_ < length; c_++)
- {
- string temp_url;
- if (c_ == 0)
- {
- temp_url = temp_src + "index.html";
-
- }
- else
- {
- temp_url = temp_src + "index_" + (c_ + 1) + ".html";
- }
-
- HtmlDocument htmlDoc_2 = await pc_Help.LoadHtmlFromUrlAsync(temp_url);
- string src = pc_Help.GetSingleNode(htmlDoc_2, temp_paxth_).Attributes["src"].Value.ToString();
- string alt = pc_Help.GetSingleNode(htmlDoc_2, temp_paxth_).Attributes["alt"].Value.ToString();
- end_img_url.Add(src);
- end_img_name.Add(alt);
- num++;
- textBox1.AppendText($"{num}-->{alt}-->{src}\r\n");
- }
- }
- }
- else
- {
- for (int x_ = 0; x_ < pagesum; x_++)
- {
-
- }
- ero = false;
- MessageBox.Show("待实现中....");
- }
- if (ero)
- {
- textBox1.AppendText("数据获取完成,正在保存文件......\r\n");
- }
- else {
- textBox1.AppendText("数据获取失败......\r\n");
- }
- return true;
- }
-
- catch (Exception ex)
- {
-
- throw new Exception("数据获取异常", ex);
- }
-
- }

