
热门标签
热门文章
- 1Weblogic上传shell路径_weblogic绝对路径
- 2GitHub Copilot 学生认证_copilot 学生续期
- 3配置本地yum源
- 4互联网晚报 | 奇瑞汽车回应要求员工周六上班;好欢螺回应妇女节争议文案;TVB淘宝首播带货2350万...
- 5大数据最新hadoop3 HA部署(1),已拿offer_hadoop3 ha 集群部署
- 6如何在 Java 中将 String 转换为 int?_java string转int
- 7springMVC的导入导出操作_springmvc实现导入导出
- 8WPF之Prism框架_wpf prism开发框架示例
- 9Excel内置Python:给工作带来的变革
- 10LLaMA 3:大模型之战的新序幕_llama3 15b挑战了scaling law吗
当前位置: article > 正文
大语言模型微调和PEFT高效微调_sft和peft
作者:木道寻08 | 2024-07-16 18:54:26
赞
踩
sft和peft
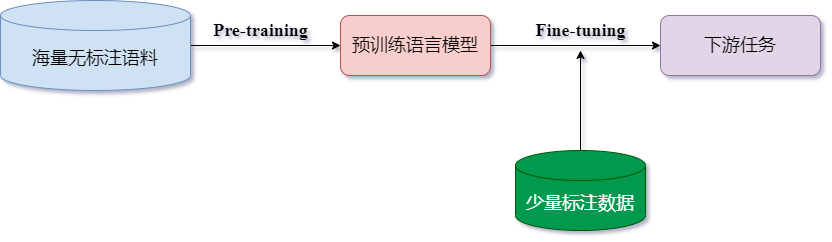
1 解释说明
- 预训练语言模型的成功,证明了我们可以从海量的无标注文本中学到潜在的语义信息,而无需为每一项下游NLP任务单独标注大量训练数据。此外,预训练语言模型的成功也开创了NLP研究的新范式,即首先使用大量无监督语料进行语言模型预训练(
Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成具体NLP任务。
1.1 预训练阶段
- 大模型首先在大量的无标签数据上进行训练,预训练的最终目的是让模型学习到语言的统计规律和一般知识。在这个过程中模型能够学习到词语的语义、句子的语法结构、以及文本的一般知识和上下文信息。需要注意的是,预训练本质上是一个无监督学习过程。
1.2 微调阶段
- 预训练好的模型然后在特定任务的数据上进行进一步的训练。这个过程通常涉及对模型的权重进行微小的调整,以使其更好地适应特定的任务。不同于模型预训练过程可以代入无标签样本,深度学习模型微调过程需要代入有标签的样本来进行训练,微调的本质是一个有监督学习过程。

2 几种微调算法
- 伴随着大模型技术的蓬勃发展,微调技术一跃成为大模型工程师必须要掌握的核心技术,越来越多的微调技术也在不断涌现。大模型微调重要性不言而喻,那么到底有哪些微调方法呢?
2.1 在线微调
- 借助OpenAl提供的在线微调工具进行微调;
- 在线微调API地址
- 按照格式要求,准备并上传数据集;
- 排队、支付费用并等待微调模型训练完成;
- 赋予微调模型API单独编号,调用API即可使用。
2.2 高效微调
- 高效微调,
State-of-the-art Parameter-Efficient Fine-Tuning (SOTA PEFT),特指部分参数的微调方法,这种方法算力功耗比更高,也是目前最为常见的微调方法; - 除此之外,Fine-Tuning也可以代指全部微调方法,同时OpenAl中模型微调API的名称也是Fine-Tuning,需要注意的是,OpenAI提供的在线微调方法也是一种高效微调方法,并不是全量微调。
- 主流高效微调方法包括
LoRA、Prefix Tuning、P-Tuning、Prompt Tuning、AdaLoRA等; - 目前这些方法的实现均已集成至
Hugging Face项目的库中,我们可以通过安装和调用Hugging Face的PEFT(高效微调)库,来快速使用这些方法; - 高效微调仓库
2.2.1 RLHF
RLHF: Reinforcement Learning from Human Feedback,即基于人工反馈机制的强化学习。最早与2022年4月,由OpenAl研究团队系统总结并提出,并在GPT模型的对话类任务微调中大放异彩,被称为ChatGPT“背后的功臣”;- 最早由OpenAl研究团队提出,并用于训练OpenAl的
InstructGPT模型,根据OpenAl相关论文说明,基于RLHF训练的InstructGPT模型,在仅拥有1.3B参数量的情况下,输出效果已经和GPT-3175B模型媲美。这充分说明了RLHF方法的实践效果; - RLHF也是目前为止常用的、最为复杂的基于强化学习的大语言模型微调方法,目前最好的端到端RLHF实现是
DeepSpeedChat库,由微软开源并维护。

- 步骤1:监督微调(
SFT)——使用精选的人类回答来微调预训练的语言模型以应对各种查询; - 步骤2:奖励模型微调——使用一个包含人类对同一查询的多个答案打分的数据集来训练一个独立的(通常比SFT小的)奖励模型(
RW); - 步骤3:RLHF训练——利用
Proximal Policy Optimization(PPO)算法,根据RW模型的奖励反馈进一步微调SFT模型。
2.2.2 LoRA
LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (2021),基于低阶自适应的大语言模型微调方法;- 原理简述:基于大模型的内在低秩特性,增加旁路矩阵来模拟全参数微调。简而言之,是通过修改模型结构进行微调,是一种四两拨千斤的微调方法,是目前最通用、同时也是效果最好的微调方法之一;
- LoRA最早是由微软研究院发布的一项微调技术,LoRA除了可以用于微调大语言模型(LLM)外,目前还有一个非常火爆的应用场景:围绕
diffusion models(扩散模型)进行微调,并在图片生成任务中表现惊艳。
2.2.3 Prefix Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation (2021),基于提示词前缀优化的微调方法,来源于斯坦福大学的一种高效微调方法;- 原理简述:在原始模型基础上,增加一个可被训练的Embedding层,用于给提示词增加前缀,从而让模型更好的理解提示词意图,并在训练过程中不断优化这些参数;
Prefix Tuning既能够在模型结构上增加一些新的灵活性,又能够在模型使用上提供一种自动的、能够改进模型表现的提示机制。
2.2.4 Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning (2021),由谷歌提出的一种轻量级的优化方法;- 原理简述:该方法相当于是Prefix Tuning的简化版本,即无需调整模型参数,而是在已有的参数中,选择一部分参数作为可学习参数,用于创建每个Prompt的前缀,从而帮助模型更好地理解和处理特定的任务;
- 不同于Prefix方法,Prompt Tuning训练得到的前缀是具备可解释性的,我们可以通过查看这些前缀,来查看模型是如何帮我们优化prompt的;
- 该方法在参数规模非常大的模型微调时效果很好,当参数规模达到100亿时和全量微调效果一致。
2.2.5 P-Tuning v2
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks (2022),来源于清华大学团队提出的高效微调方法;- 原理简述:可以理解为Prefix tuning的改进版本,即P-Tuning v2不仅在输入层添加了连续的prompts(可被训练的Embedding层),而且还在预训练模型的每一层都添加了连续的prompts;
- 这种深度的prompt tuning增加了连续prompts的容量,出于某些原因,P-Tuning v2会非常适合
GLM这种双向预训练大模型微调。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/835713
推荐阅读
相关标签

