
- 1git查看用户名和邮箱 -切换用户和邮箱_gitchax用户名和邮箱
- 2大数据-hadoop之MR_hadoop中mr程序是什么
- 3解决turtle无法使用的问题_python3.9 turtle用不了
- 4为什么面向对象的设计方法逐渐减少
- 5解放程序员生产力的AI代码助手重磅来袭_eclipse 人工智能
- 610.javaSE基础_JDBC编译程序(Driver+Statement+Connection+mysql数据库连接)
- 7C++中ios::in, ios::out, ios::trunc使用
- 8【Launcher3系列】 Android 10 11 12 Launcher3 双层改成单层_android 11.0 launcher3双层改成单层
- 9springcloud
- 10springboot基于微信小程序的在线办公系统+java+uinapp+Mysql_uniapp小程序+springboot+mysql使用到的技术框架
重新定义流计算:第三代流处理系统 RisingWave 的 2024 年展望_risingwave 三种部署方式
赞
踩
流处理技术在过去的 20 年里经历了从学术概念到商业应用的演变。流处理系统从无到有,我们见证了从第一代数据流管理系统如 IBM System S、Oracle CQL、Esper 等,到第二代基于 MapReduce 思想发展出的分布式流计算平台,如 Apache Spark Streaming、Apache Flink 等,再到如今的第三代云原生流处理系统,如 RisingWave。这一发展标志着流处理技术的普及和简化,已成为众多行业中不可或缺的关键技术。
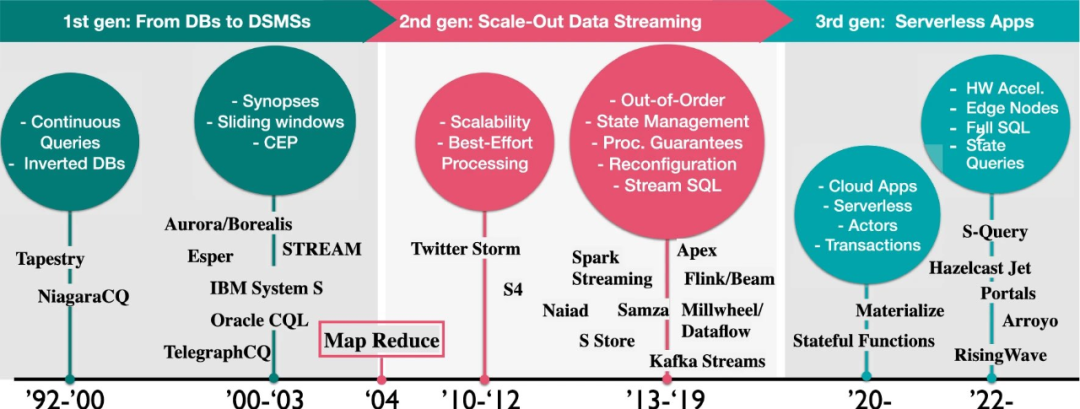
图片来源:Fragkoulis, Marios, et al. "A survey on the evolution of stream processing systems." The VLDB Journal (2023): 1-35.
RisingWave 诞生于 2021 年初。经过三年的打磨,已然成长为第三代流处理系统中最具代表性的产品。自 2022 年 4 月开源以来,在全球范围内更是增长迅速,互联网、金融、能源、航空航天、供应链、智能汽车等多个领域的生产环境中都得到了落地应用。到今天,RisingWave 的全球日活集群已达上百个。

RisingWave 集群全球部署情况(2023 年 12 月数据)
2024 年对于 RisingWave 来说,是走向成熟阶段的重要转折之年。我们将全力加速推动产品普及化,为全球用户提供更易用、更高效的流处理服务。在本文中,我们将对 RisingWave 的 2024 年做出展望。
1强化易用性与性价比两大特性
RisingWave 诞生之初,便将"使流计算平民化"作为长期发展目标, 致力于强化流处理系统的易用性与高性价比,不断降低流计算学习、使用与维护的门槛。
在易用性方面,RisingWave 实现了与 PostgreSQL 的协议兼容性,能与 PostgreSQL 生态圈的系统进行有效交互。用户能够使用遵循 PostgreSQL 语法规范的 SQL 语句来构建物化视图,进而直接执行流计算操作。此外,RisingWave 支持用户创建层级物化视图,并能确保计算一致性与实时性,显著简化了相对于传统流计算基于"流计算引擎 + 消息队列 + 数据库"组合架构的复杂性,从而在系统开发与维护方面实现成本的大幅降低。
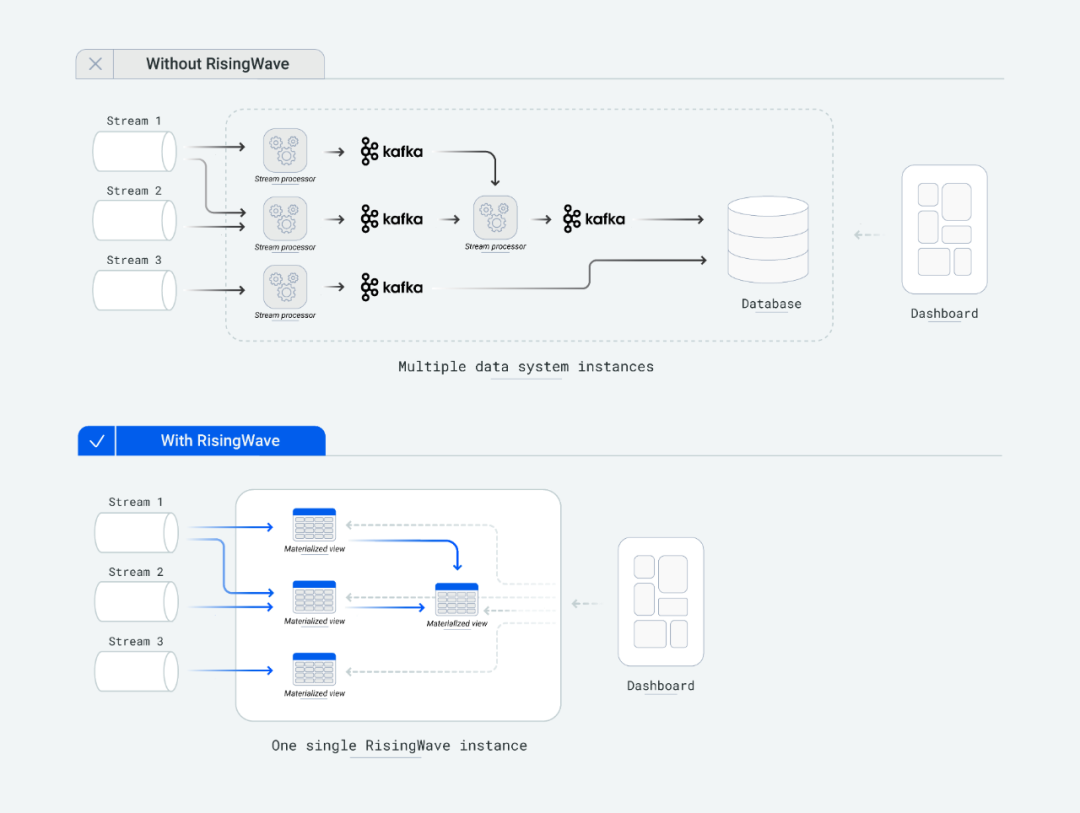
使用 RisingWave 大幅简化流处理应用开发架构复杂度
在性价比方面,RisingWave 持续优化存算分离架构,以稳定且高效地支持大规模状态计算。RisingWave 将远端对象存储作为计算状态的持久化介质,依靠此架构实现了秒级系统故障恢复及弹性扩缩容能力。此外,RisingWave 通过实施分层存储以及智能缓存机制来尽可能避免出现访问远端对象存储的情况,从而缓解远端对象存储访问可能带来的延迟升高问题。
2自动弹性扩缩容与极致性能
RisingWave 采用存算分离架构,实现了无限水平扩展,同时保障了系统的高可用性和弹性扩缩容能力。在 2024 年,我们将加大力度对 RisingWave 的架构和用户体验进行全面升级。
当前,虽然 RisingWave 支持秒级弹性扩缩容,但这一过程仍需用户基于线上负载进行手动调整,这在一定程度上限制了其便利性。为此,RisingWave 计划在近期版本中推出自动扩缩容功能,自主根据集群变化动态调整流计算分布,充分适应集群规模。
此外,RisingWave 将进一步对其分层存储进行优化。由于远端对象存储性能问题,可能会导致 RisingWave 在缓存未命中的情况下出现性能抖动。RisingWave 将进一步优化缓存策略,降低性能抖动出现概率。对于如多流 join 等大计算状态查询,RisingWave 也会进一步对优化器与执行器进行升级,以巩固其在性能方面相较于同类产品的领先地位。
3全面拥抱数据湖
RisingWave 已实现了对多种数据湖格式的读写支持。值得一提的是,RisingWave 与 Apache Iceberg 等社区一同参与贡献了 Apache Iceberg Rust 项目,不仅为 Rust 项目提供了 Iceberg 接口,而且实现了对 Iceberg 格式写入性能的三倍提升。
在 2024 年,RisingWave 计划与各大数据湖社区紧密合作,进一步加强与各大数据湖的集成。这将显著提升 RisingWave 对数据湖的直接读写能力,使用户能通过 RisingWave 进行实时数据湖写入,并直接在数据湖上构建物化视图,根据数据湖变更直接为用户呈现实时计算结果。这也意味着用户可以直接通过 RisingWave 对实时流数据与历史批数据进行统一分析。
同时,RisingWave 将联合主流数据湖以及实时分析系统厂商一起构建流式湖仓,为用户带来更低成本、更加实时的数据管理体验。
4显著提升在线数据服务体验
RisingWave 定位为流数据库,而非流计算引擎。这意味着用户会经常将 RisingWave 使用于在线数据服务中,为传统操作型数据库(如 MySQL、PostgreSQL、MongoDB 等)提供功能增强。典型场景比如:使用 RisingWave 直接消费操作型数据库 CDC,构建实时物化视图,为用户应用直接提供在线数据查询服务。
在 2024 年,RisingWave 将投入更多资源来提升在线数据服务应用的体验。从数据导入方面,将为更多应用开发直连数据导入能力,使用户更加轻松的将数据实时传输至 RisingWave;在数据存储方面,RisingWave 计划引入新型表结构,对数据进行高效压缩以节省存储成本,同时允许外部引擎直接访问 RisingWave 数据;在数据服务方面,RisingWave 将添加轻量级全文检索等功能,进一步优化高并发查询响应能力,使用户更加稳定高效地构建在线数据应用。
5归于开源,回馈社区
RisingWave 流数据库能够在流处理领域占有一席之地,离不开近 150 位开源贡献者及近 3000 名社区成员的支持与贡献。RisingWave 始终倾听社区声音,积极响应用户反馈,虚心采纳用户意见。在未来的一年里,RisingWave 将举办多场线上、线下社区活动,以进一步推广流计算系统应用。
为了更好地服务中文用户,我们将在 2024 年初上线全新中文文档,让更多中文用户了解与使用 RisingWave,并推动中文社区蓬勃发展。
RisingWave 期望与社区成员一道,共同打造下一代流处理系统,推动流计算技术的繁荣和普及。
往期推荐
RisingWave 1.5 发布!更完善数据库管理功能,更全面的 JSON 支持,新版 MySQL CDC 连接器
![]()
RisingWave是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于降低流计算使用门槛。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,帮助用户轻松快速搭建稳定高效的流计算系统。使用 RisingWave 处理流数据的方式类似使用 PostgreSQL,通过创建实时物化视图,让用户能够轻松编写流计算逻辑,并通过访问物化视图来进行即时、一致的查询流计算结果。了解更多:
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

