
热门标签
热门文章
- 12024年第九届数维杯大学生数学建模挑战赛C 题解题思路1.0版本_数维赛c
- 2【阅读总结】AlphaFold3 unedited version 通读 + 服务器使用总结_alphafold3论文
- 3TensorFlow学习--卷积神经网络CNN_tensorflow卷积神经网络cnn
- 4超详细Redis下载安装图文教程(Win和Linux版)_redis下载教程
- 5《敏捷软件开发:原则、模式与实践》7-12章读书笔记_《敏捷软件开发:原则、模式与实践》7-12章读书笔记
- 6常用机器学习算法训练预测模型的常规流程
- 7红黑树&平衡二叉搜索树(AVL)_红黑树的平衡因子
- 8Github与VisualStudio的结合操作_如何在vs中把github上的项目在自己电脑上运行
- 9so的封装和使用_linux 第三方.so封装
- 10(保姆级攻略)怎么注册hithub并且将eclipse的文件放入github中(添加了Mac电脑可能会遇到的问题)_hithpb
当前位置: article > 正文
爬虫案例—根据四大名著书名抓取并存储为文本文件_爬取四大名著beautifulsoup
作者:木道寻08 | 2024-06-24 02:18:18
赞
踩
爬取四大名著beautifulsoup
爬虫案例—根据四大名著书名抓取并存储为文本文件
诗词名句网:https://www.shicimingju.com
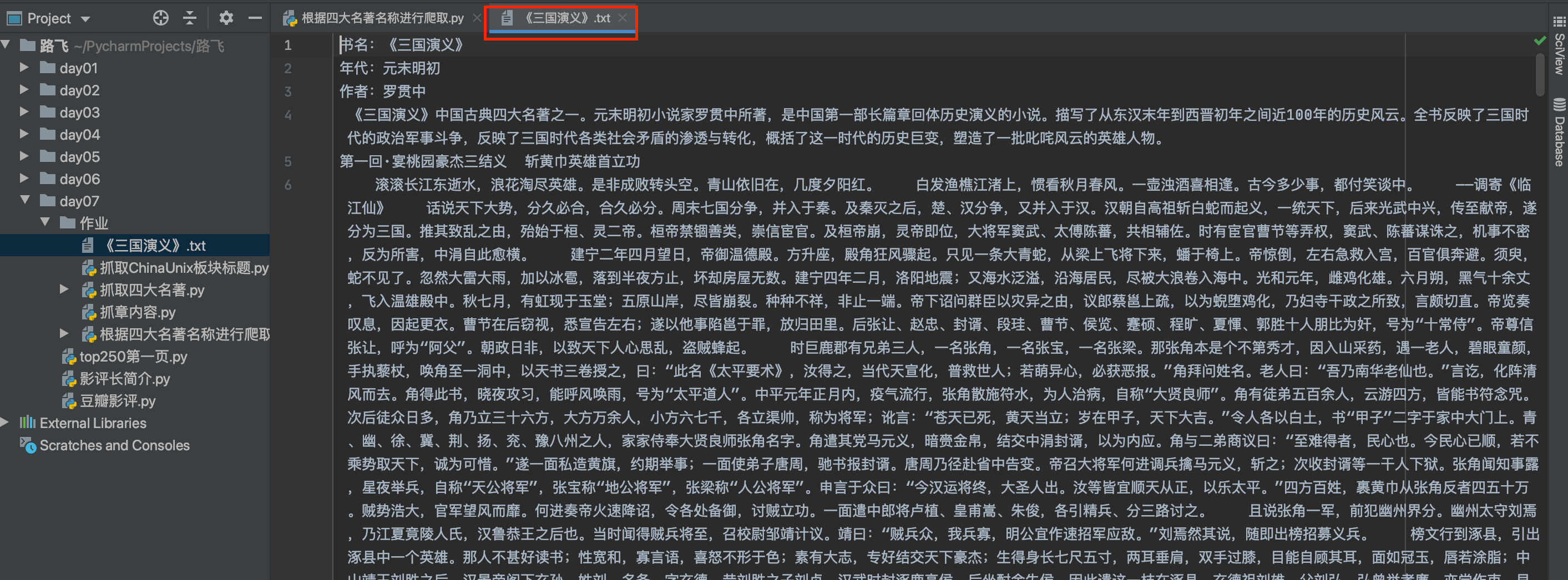
目标:输入四大名著的书名,抓取名著的全部内容,包括书名,作者,年代及各章节内容
诗词名句网主页如下图:

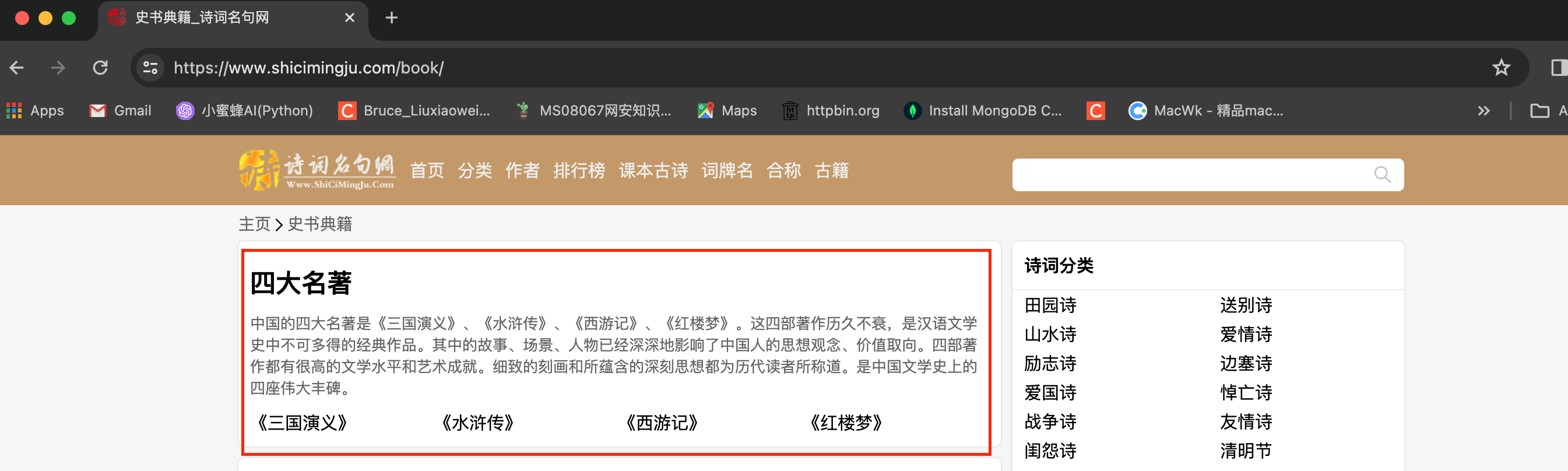
今天的案例是抓取古籍板块下的四大名著,如下图:
 案例源码如下:
案例源码如下:
import time import requests from bs4 import BeautifulSoup import random headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36', } # 获取响应页面,并返回实例化soup def get_soup(html_url): res = requests.get(html_url, headers=headers) res.encoding = res.apparent_encoding html = res.content.decode() soup = BeautifulSoup(html, 'lxml') return soup # 返回名著的书名及对应的网址字典 def get_book_url(page_url): book_url_dic = {} soup = get_soup(page_url) div_tag = soup.find(class_="card booknark_card") title_lst = div_tag.ul.find_all(name='li') for title in title_lst: book_url_dic[title.a.text.strip('《》')] = 'https://www.shicimingju.com' + title.a['href'] return book_url_dic # 输出每一章节内容 def get_chapter_content(chapter_url): chapter_content_lst = [] chapter_soup = get_soup(chapter_url) div_chapter = chapter_soup.find(class_='card bookmark-list') chapter_content = div_chapter.find_all('p') for p_content in chapter_content: chapter_content_lst.append(p_content.text) time.sleep(random.randint(1, 3)) return chapter_content_lst # 主程序 if __name__ == '__main__': # 古籍板块链接 gj_url = 'https://www.shicimingju.com/book' url_dic = get_book_url(gj_url) mz_name = input('请输入四大名著名称: ') mz_url = url_dic[mz_name] soup = get_soup(mz_url) abbr_tag = soup.find(class_="card bookmark-list") book_name = abbr_tag.h1.text f = open(f'{book_name}.txt', 'a', encoding='utf-8') f.write('书名:'+book_name+'\n') print('名著名称:', book_name, end='\n') p_lst = abbr_tag.find_all('p') for p in p_lst: f.write(p.text+'\n') mulu_lst = soup.find_all(class_="book-mulu") book_ul = mulu_lst[0].ul book_li = book_ul.find_all(name='li') for bl in book_li: print('\t\t', bl.text) chapter_url = 'https://www.shicimingju.com' + bl.a['href'] f.write(bl.text+'\n') f.write(''.join(get_chapter_content(chapter_url))+'\n') f.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/751374
推荐阅读
相关标签

