
热门标签
热门文章
- 1AI让老照片动起来,日赚500+,爆火项目拆解近,AI技术让老照片动起来火爆网络。_ai老照片动起来是什么模型
- 2银河麒麟v10安装前端环境(Node、vue、Electron+vite)_麒麟系统安装nodejs
- 3当机器学习遇到基因组选择_机器学习 基因组
- 4软考中级信息系统监理师(第二版)-第4章信息资源系统_信息系统监理师第2版
- 5【ZooKeeper】ZooKeeper快速入门
- 6这是我见过 AI 大模型面试题超全汇总了!_java ai大模型面试题
- 7高级前端面试题及详解
- 8Apollo使用(3):分布式docker部署_appllo docker
- 9按摩上门预约小程序源码系统 开发组合:PHP+MySQL 附带完整的搭建教程_php预约上门源码
- 10SVM和随机森林的特点归纳_svm,随机森林模型的性能
当前位置: article > 正文
Transformer的各个模块_transformer模块
作者:我家自动化 | 2024-08-04 06:47:53
赞
踩
transformer模块
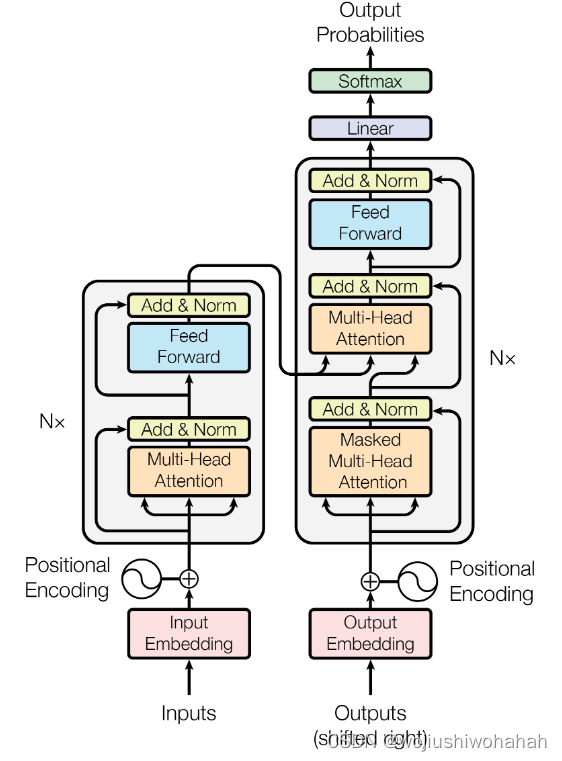
1.Input Embedding
Inputs在字典中找到对应的嵌入表示(batchsize*seqlen*model_dim)
词嵌入矩阵需要根据语料库来确定第一个维度(字典里面有多少个词)
- #已知如下语料,给出其词嵌入
- corpus = ["he is an old worker", "english is a useful tool", "the cinema is far away"]
- cibiao=[]
- for i in corpus:
- for j in i.split():
- cibiao.append(j)
- set(cibiao)#去重
- cibiao_dict={}
-
- #利用enumerate添加索引
- for i in enumerate(set(cibiao)):
- print(i[1])
- cibiao_dict[i[1]]=i[0]#字典的赋值;old赋值为0
- cibiao_dict
定义Input Embedding层
- class Embeddings(nn.Module):
- def __init__(self, d_model, vocab):
- # d_model:词嵌入维度
- # vocab:字典大小
- super(Embeddings, self).__init__()
- self.lut = nn.Embedding(vocab, d_model)
- self.d_model = d_model
- def forward(self, x):#根据索引找到对应的词向量
- return self.lut(x) * math.sqrt(self.d_model)
我们现在确定了字典里面有1000个词;此时batchsize*seqlen*model_dim=2*4*512
- d_model = 512 # embedding_size
- vocab = 1000 # 词典大小
- x=torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]], dtype=torch.long)
- emb = Embeddings(d_model, vocab)
- embr = emb(x)
- print(embr.shape)
2.position Embedding层
非常强硬的加入了所在的位置信息,其中pos表示行的信息,单词在句子中所在的位置(从0到seqlen-1)
i表示列的信息(从0到model_dim/2-1)
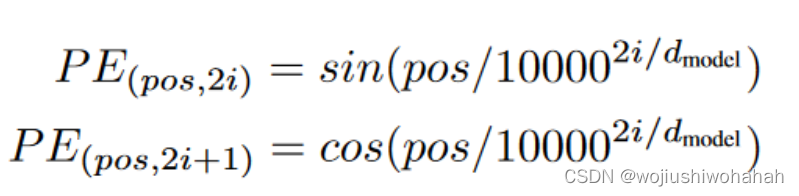
可以利用循环得到这个矩阵
- import numpy as np
- import matplotlib.pyplot as plot
-
- def getPositionEncoding(seq_len,dim,n=10000):
- PE = np.zeros(shape=(seq_len,dim))
- #PE=np.zeros((seq_len,dim))
- for pos in range(seq_len):
- for i in range(int(dim/2)):
- denominator=np.power(n,2*i/dim)
- PE[pos,2*i]=np.sin(pos/denominator)
推荐阅读
相关标签

