
热门标签
热门文章
- 1Unity学习笔记_steam音频监听
- 2机器学习(26)回顾gan+文献阅读
- 3从0开始搭建FPS游戏 (附源代码)【OpenGL | 开发思路分享】_游戏源码搭建
- 4口碑公认:盘点2024年性价比超凡的四款电脑桌面管理软件_电脑桌面管理软件那个好
- 5AIGC专题:生成式AI(GenAI)赋能供应链之路_aigc genai
- 6Python系列 - pip管理工具_pip工具怎么打开
- 7[数据结构] 用两个栈实现队列详解
- 8ReiBoot(iOS系统修复工具)v6.9.5.0官方版_reiboot需要付费?
- 9Android学习笔记之AndroidManifest.xml文件解析_framework解析androidmanifast.xml
- 10你一定要狠狠的幸福,那个凶丫头_草后妈
当前位置: article > 正文
LLAMA3==shenzhi-wang/Llama3-8B-Chinese-Chat。windows安装不使用ollama
作者:我家自动化 | 2024-07-29 20:37:17
赞
踩
llama3-8b-chinese-chat
创建环境:
conda create -n llama3_env python=3.10
conda activate llama3_env
conda install pytorch torchvision torchaudio cudatoolkit=11.7 -c pytorch
安装Hugging Face的Transformers库:
pip install transformers sentencepiece
下载模型
https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat/tree/main
编写代码调用
- import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
-
- # 检查CUDA是否可用,并设置设备
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
- print(torch.cuda.is_available())
- print(device)
-
- # 加载模型和tokenizer
- model_name = "F:\\ollama_models\\Llama3-8B-Chinese-Chat"
- model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
- tokenizer = AutoTokenizer.from_pretrained(model_name)
-
- # 编写推理函数
- # def generate_text(prompt):
- # inputs = tokenizer(prompt, return_tensors="pt").to(device)
- # outputs = model.generate(inputs['input_ids'], max_length=100)
- # return tokenizer.decode(outputs[0], skip_special_tokens=True)
- #
- # # 示例使用
- # prompt = "写一首诗吧,以春天为主题"
- # print(generate_text(prompt))
-
- messages = [
- {"role": "user", "content": "写一首诗吧"},
- ]
-
- input_ids = tokenizer.apply_chat_template(
- messages, add_generation_prompt=True, return_tensors="pt"
- ).to(model.device)
-
- outputs = model.generate(
- input_ids,
- max_new_tokens=8192,
- do_sample=True,
- temperature=0.6,
- top_p=0.9,
- )
- response = outputs[0][input_ids.shape[-1]:]
- print(tokenizer.decode(response, skip_special_tokens=True))


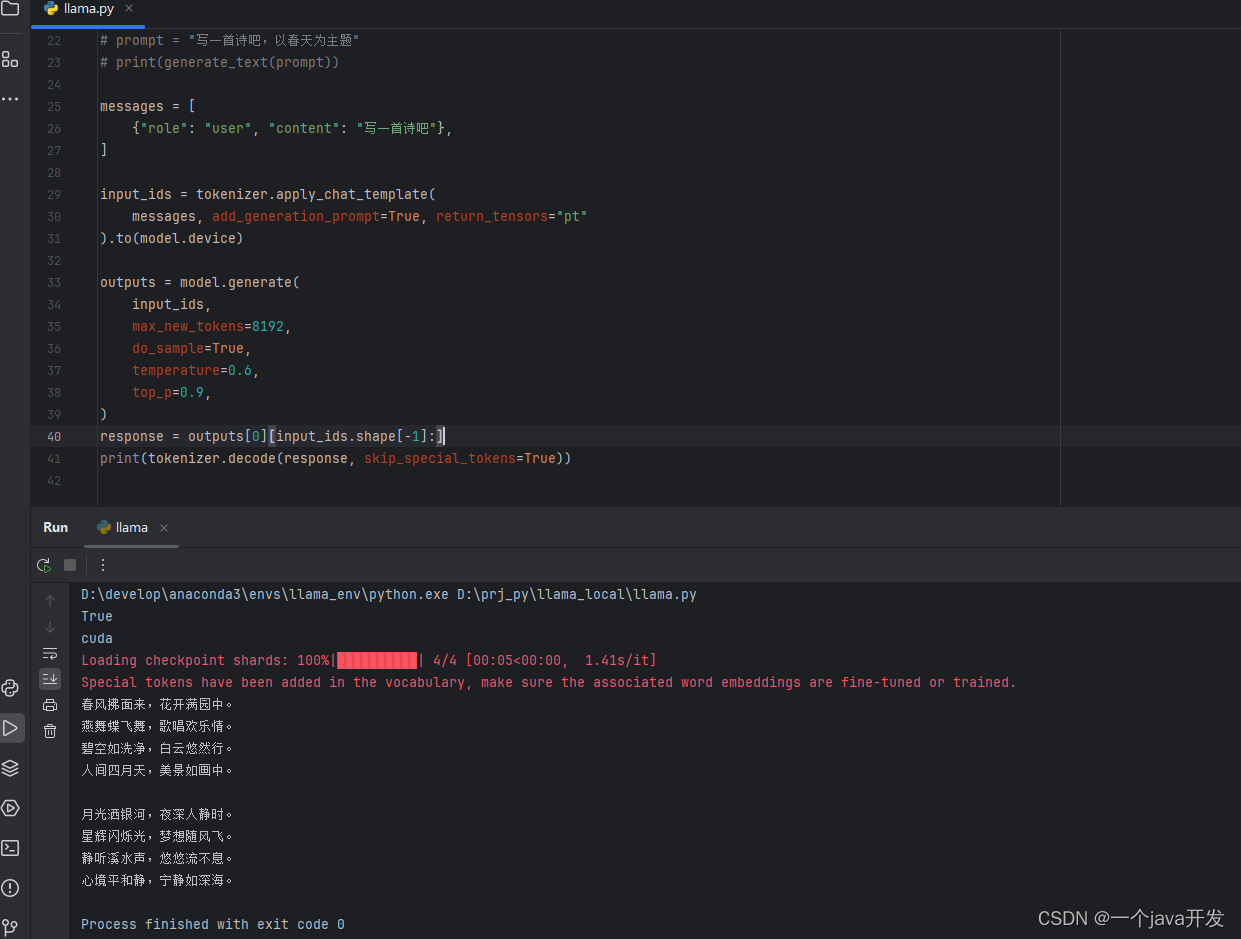
非常慢,大概用了一两分钟回答一个问题。
还是老实用ollama跑qwen吧
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/900490
推荐阅读
相关标签

