
热门标签
当前位置: article > 正文
机器学习——决策树及其可视化
作者:我家自动化 | 2024-07-07 00:05:27
赞
踩
机器学习——决策树及其可视化
1、决策树概念
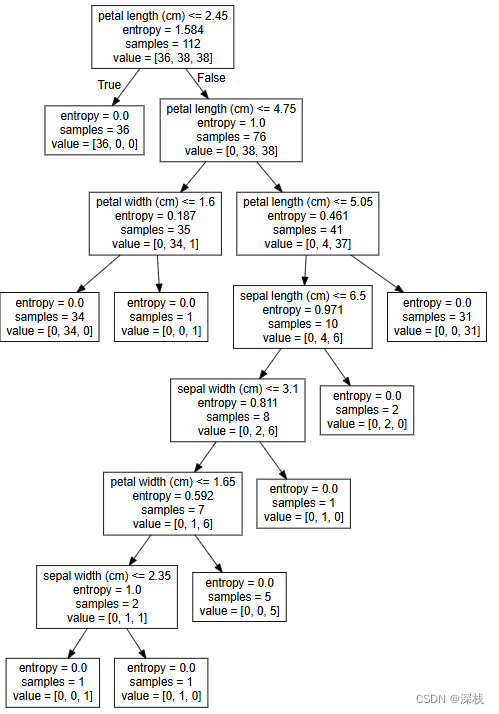
顾名思义,决策树是利用数据结构中树结构来进行判断,每一个结点相当于一个判断条件,叶子结点即是最终的类别。以鸢尾花为例,可以得到如下的决策树:
2、决策树分类的依据是什么?
根据前面分析,我们知道,决策树每个非叶子节点相当于一个判断条件,那如何来选择这些条件呢?举个简单的例子,给定两个样本,如果判断条件不同,那么分类的次数和结果可能就不同。为了方便选择,常用的方法有以下三种:
1)信息增益:根据信息的定义之一:信息是可以减少不确定性的东西(香农—信息论奠基人),信息增益是基于熵(Entropy)的度量,熵是一个集合中数据的不确定性或混乱程度。信息增益衡量的是在某个特征上划分数据后,数据的不确定性减少了多少。信息增益越大,特征越好。
公式:

2)基尼系数
基尼指数是一种衡量集合纯度的度量,基尼指数越低,数据纯度越高。在决策树中,我们选择基尼指数最小的特征进行划分。
公式:

3)增益率
增益率是对信息增益的一种改进,旨在解决信息增益偏向于选择取值较多的特征的问题。增益率通过对信息增益进行归一化处理来减少这种偏好。
通常使用基尼系数和信息增益来衡量分类的依据。
3、根据天气决策是否打网球案例。(使用决策树)
import pandas as pd data = { 'Outlook': ['Sunny', 'Sunny', 'Overcast', 'Rain', 'Rain', 'Rain', 'Overcast', 'Sunny', 'Sunny', 'Rain', 'Sunny', 'Overcast', 'Overcast', 'Rain'], 'Temperature': ['Hot', 'Hot', 'Hot', 'Mild', 'Cool', 'Cool', 'Cool', 'Mild', 'Cool', 'Mild', 'Mild', 'Mild', 'Hot', 'Mild'], 'Humidity': ['High', 'High', 'High', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'High'], 'Windy': [False, True, False, False, False, True, True, False, False, False, True, True, False, True], 'PlayTennis': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No'] } data = pd.DataFrame(data) X = data[['Outlook', 'Temperature', 'Humidity', 'Windy']] y = data['PlayTennis'] x=pd.get_dummies(X) # 转化成独热码 from sklearn.tree import DecisionTreeClassifier estimator = DecisionTreeClassifier(criterion='gini') # criterion为选择标准,默认为gini,即基尼系数,entropy为信息增益 estimator.fit(x,y) # 输入十个案例进行判断 test_data = [ {"Outlook": "Rain", "Temperature": "Hot", "Humidity": "High", "Windy": True, "PlayTennis": "No"}, {"Outlook": "Sunny", "Temperature": "Mild", "Humidity": "High", "Windy": True, "PlayTennis": "No"}, {"Outlook": "Overcast", "Temperature": "Mild", "Humidity": "High", "Windy": False, "PlayTennis": "Yes"}, {"Outlook": "Sunny", "Temperature": "Cool", "Humidity": "Normal", "Windy": False, "PlayTennis": "Yes"}, {"Outlook": "Rain", "Temperature": "Cool", "Humidity": "High", "Windy": False, "PlayTennis": "Yes"}, {"Outlook": "Sunny", "Temperature": "Hot", "Humidity": "Normal", "Windy": True, "PlayTennis": "No"}, {"Outlook": "Overcast", "Temperature": "Hot", "Humidity": "Normal", "Windy": True, "PlayTennis": "Yes"}, {"Outlook": "Rain", "Temperature": "Mild", "Humidity": "Normal", "Windy": True, "PlayTennis": "No"}, {"Outlook": "Overcast", "Temperature": "Cool", "Humidity": "High", "Windy": False, "PlayTennis": "Yes"}, {"Outlook": "Sunny", "Temperature": "Mild", "Humidity": "Normal", "Windy": False, "PlayTennis": "Yes"} ] test_data = pd.DataFrame(test_data) x_test = test_data[['Outlook', 'Temperature', 'Humidity', 'Windy']] x_test = pd.get_dummies((x_test)) estimator.predict(x_test)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
预测结果如下所示:
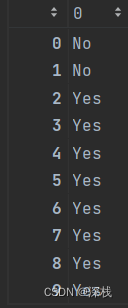
estimator.score(x_test,test_data['PlayTennis']) # 正确率计算,结果为0.8
- 1
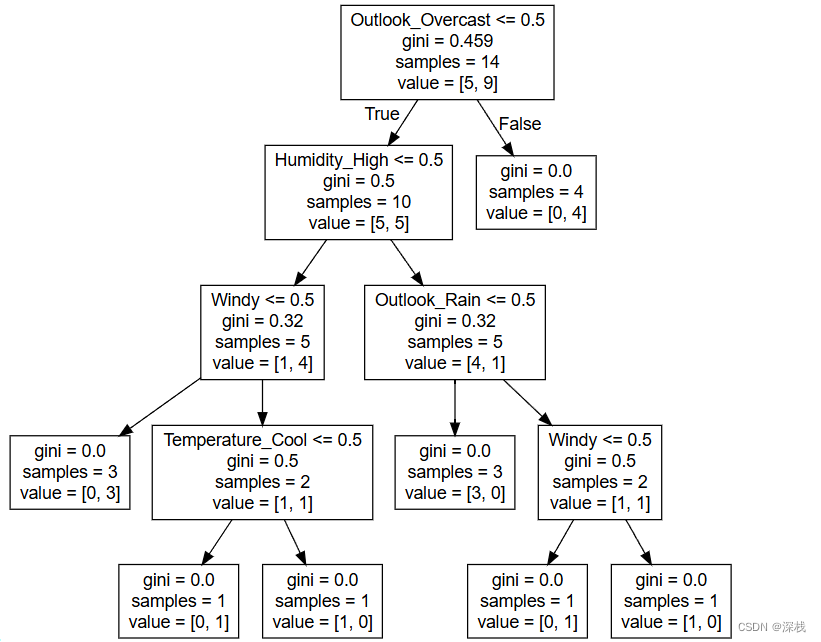
4、决策树的可视化
使用API:sklearn.tree.export_graphviz(estimator, out_file="", feature_names=[","])
out_file后缀需要为.dot文件,feature_names传入对应的特征名称即可,否则显示异常
- 1
最后将生成的.dot文件在决策树可视化网站显示即可,以上述为例:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/794337
推荐阅读
相关标签

