
热门标签
热门文章
- 1Nginx网站使用CDN之后禁止用户真实IP访问的方法
- 2PyQt(Python+Qt)学习随笔:model/view架构中的两个标准模型QStandardItemModel和QFileSystemModel_qstandarditemmodel qfilesystemmodel
- 3音频变速python版_语音 语速语调 调节 python
- 4mac python3 轻松安装教程
- 5热力图_c++ opencv 热力图
- 6Streamlit+Echarts画出的图表,真的是太精湛了!!_streamlit echarts
- 7成为有钱人的终极秘诀:做到这7步,你也可以成为富人!_成为富人秘诀
- 8【SpringBoot Web框架实战教程(开源)】02 SpringBoot 返回 JSON
- 9【粉丝福利社】《AI高效工作一本通》(文末送书-完结)
- 10【全网唯一】触摸精灵iOS版纯离线本地文字识别插件_tomatoocr文字识别工具,纯本地离线识别
当前位置: article > 正文
爬虫学习笔记(十)数据存储——xml、json、csv 2020.5.9
作者:我家自动化 | 2024-06-27 12:04:09
赞
踩
爬虫学习笔记(十)数据存储——xml、json、csv 2020.5.9
前言
本节学习数据存储的xml、json、csv
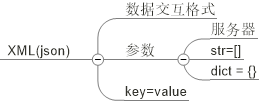
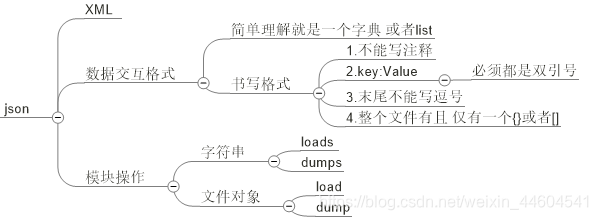
1、json书写格式
如上图所说
例:
{
"name":"张三",
"age":10
}- 1
- 2
- 3
- 4
2、json操作
import json # 1.字符串和 dic list转换 # 字符串(json)----dict list data = '[{"name":"张三","age":20},{"name":"李四","age":18}]' list_data = json.loads(data) print(type(data)) print(type(list_data)) # dict list ---字符串 list2 = [{ "name": "张三", "age": 20}, { "name": "李四", "age": 18}] data_json = json.dumps(list2) print(type(list2)) print(type(data_json)) # 2.文件对象 和 dict list转换 # dict list 写入文件 list2 = [{ "name": "张三", "age": 20}, { "name": "李四", "age": 18}] # fp 是 file path fp = open('02new.json', 'w') json.dump(list2, fp) fp.close() # 读取文件json -----list dict results = json.load(open('02new.json', 'r')) print(results)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
获得的json文件02new.json如下
[{
"name": "\u5f20\u4e09", "age": 20}, {
"name": "\u674e\u56db", "age": 18}]- 1
- 2
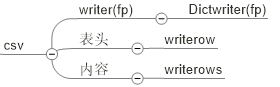
3、csv
将json转换成csv
import json import csv # 需求:json 中的数据转换成 csv 文件 # 1.读json , 创建csv文件 json_fp = open('02new.json', 'r') csv_fp = open('03csv.csv', 'w') # 2.提出表头 , 表内容 data_list = json.load(json_fp) sheet_title = data_list[0].keys() #表头 print(sheet_title) sheet_data = [] for data in data_list: sheet_data.append(data.values()) #表内容 # 3. csv 写入器 writer = csv.writer(csv_fp) # 4. 写入表头 writer.writerow(sheet_title) # 5. 写入内容 writer.writerows(sheet_data) # 6. 关闭两个文件 json_fp.close() csv_fp.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
得到的csv文件

4、例子
import requests from lxml import etree from bs4 import BeautifulSoup import json class BookSpider(object): def __init__(self): self.base_url = 'http://www.allitebooks.com/page/{}' #留下页数替换的位置 self.headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'} self.data_list = [] # 1.构建所有url def get_url_list(self): url_list = [] for i in range(1, 10): url = self.base_url.format(i) url_list.append(url) return url_list # 2.发请求 def send_request(self, url): data = requests.get(url, headers=self.headers).content.decode() print(url) return data # 3.解析数据 xpath 或 bs4 选一个 def parse_xpath_data(self, data): parse_data = etree.HTML(data) # 取出所有的书 book_list = parse_data.xpath('//div[@class="main-content-inner clearfix"]/article') # 解析出每本书的信息,这要一层层找 for book in book_list: book_dict = { } # 书名字 book_dict['book_name'] = book.xpath('.//h2[@class="entry-title"]//text()')[0] # 书的图片url book_dict['book_img_url'] = book.xpath('div[@class="entry-thumbnail hover-thumb"]/a/img/@src')[0] # 书的作者 book_dict['book_author'] = book.xpath('.//h5[@class="entry-author"]//text()')[0] # 书的简介 book_dict['book_info'] = book.xpath('.//div[@class="entry-summary"]/p/text()')[0] self.data_list.append(book_dict) def parse_bs4_data(self, data): bs4_data = BeautifulSoup(data, 'lxml') # 取出所有的书 book_list = bs4_data.select('article') # 解析出 每本书的 信息 for book in book_list: book_dict = { } # 书名字 book_dict['book_name'] = book.select_one('.entry-title').get_text() # 书的图片url book_dict['book_img_url'] = book.select_one('.attachment-post-thumbnail').get('src') # 书的作者 book_dict['book_author'] = book.select_one('.entry-author').get_text()[3:] # 书的简介 book_dict['book_info'] = book.select_one('.entry-summary p').get_text() self.data_list.append(book_dict) # 4.保存数据 def save_data(self): json.dump(self.data_list, open("04book.json", 'w')) with open('book.html','w') as f: f.write(data) # 5.统筹调用 def start(self): url_list = self.get_url_list() # 循环遍历发送请求 for url in url_list: data = self.send_request(url) # self.parse_xpath_data(data) self.parse_bs4_data(data) self.save_data() BookSpider().start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
获取的json
[{
"book_name": "Microsoft Dynamics 365 For Dummies", "book_img_url": "http://www.allitebooks.com/wp-content/uploads/2018/10/Microsoft-Dynamics-365-For-Dummies.jpg", "book_author": " Renato Bellu", "book_info": "Accelerate your digital transformation and break down silos with Microsoft Dynamics 365 It\u2019s no secret that running a business involves several complex parts like managing staff, financials, marketing, and operations\u2014just to name a few. That\u2019s where Microsoft Dynamics 365, the most profitable business management tool, comes in. In\u00a0Microsoft\u2026"}, {
"book_name": "Android Phones & Tablets For Dummies", "book_img_url": "http://www.allitebooks.com/wp-content/uploads/2018/10/Android-Phones-Tablets-For-Dummies.jpg", "book_author": " Dan Gookin", "book_info": "Outsmart your new Android Getting a smartphone or tablet can be intimidating for anyone, but this user-friendly guide is here to help you to get the most out of all your new gadget has to offer! Whether you\u2019re upgrading from an older model or totally new to the\u2026"}, {
"book_name": "CCNA Security 640-554 Official Cert Guide", "book_img_url": "http://www.allitebooks.com/wp-content/uploads/2018/10/CCNA-Security-640-554-Official-Cert-Guide.jpg"- 1
- 2
- 3
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/762458
推荐阅读
相关标签

