
- 1IntelliJ IDEA 统一设置编码为utf-8编码 及 SpringBoot 打 jar 包运行 在windows 平台控制台和日志 乱码解决_idea更改某个项目的编码格式
- 2HBase 配置文件
- 3机器人程序设计——之如何正确入门ROS | 硬创公开课
- 4机器学习辅助的乙醇浓度检测(毕设节选)
- 5【SQL Sever】 函数的创建_sqlsever函数创建
- 6【隐私计算实训营003详解隐私计算框架及技术要点】_隐语计算框架
- 7你对自己的现在的工作满意么?正能量,献给自己和刚刚毕业找到工作的人,在知乎看到的,转载...
- 8Python列表合并技术,让你的代码更具灵活性!_如何将小列表合成大列表
- 9MapReduce总结_mapreduce实验总结和心得
- 10测试工作经验总结1:没需求更要测试!_您是否碰到过没有需求就要求做测试的情况,或者,您认为怎么会没有需求就要做测 试
蛋白质界的 ChatGPT:AlphaFold1 论文必备知识,不会有人还不知道吧
赞
踩
你知道 AlphaFold2 吗?它真正解决了蛋白质三维结构预测的算法困境,堪称蛋白质界的 chat-GPT4,甚至它的意义不是 chat-GPT4 所能够匹敌的。它为世界疾病治疗药物开发以及探究生物生命之谜提供了通向天神的一条道路,未来是生物的世纪!AlphaFold2再登Nature,从业者都懵了:人类98.5%的蛋白质,全都被预测了一遍,现在,它已经公开了超两亿个蛋白质预测的三维结构,免费无偿提供,让我们感谢这一开源精神。当然,我们也可以先了解AF1,从最开始,到后来的改变!
Alphafold 论文目录结构

1-3:介绍 Alphafold 的完成背景与其他模型的优势,以及取得的成就
4-5:介绍 Alphafold 的基本思路,预测核心部件(卷积神经网络)以及梯度程序的思路
6-10:介绍 Alphafold 第一阶段的输出——残基距离分布图,以及第二阶段梯度下降程序效果
11-14:说明了核心部件对应的卷积神经网络的输入特征说明,以及选择一些输入因素的原因
15-23:搭建蛋白质可微几何模型以及梯度下降处理的思路及其效果
23-27:Alphafold 对 T0986s2 蛋白质的预测,达到 TM 分数 0.8,展示了神经网络的输入如何影响最终的预测
残差
残差,是指实际观察值与回归估计值的差。残差分析就是通过残差所提供的信息,分析出数据的可靠性、周期性或其它干扰。残差图的分布趋势可以帮助判明所拟合的线性模型是否满足有关假设。残差有多种形式,上述为普通残差。为了更深入地研究某一自变量与因变量的关系,人们还引进了偏残差。以某种残差为纵坐标,其它变量为横坐标作散点图,即残差图,它是残差分析的重要方法之一。需分析具体情况,探索合适的校正方案,如非线性处理,引入新自变量,或考察误差是否有自相关性。
蛋白质相似性度量
蛋白质结构相似性通常通过RMSD(均方根偏差)分数、GDT(全局距离测试)分数和模板建模分数(TM-score)来衡量。
参考:蛋白质结构相似性与TM评分= 0.5有多显著? |生物信息学 |牛津学术 (oup.com)
RMSD
两种蛋白质结构的最佳叠加后所有等效原子对的均方根偏差(RMSD),然而,由于结构中的所有原子在计算中的权重相等,RMSD的主要缺点之一是,当RMSD值很大时,它对局部结构偏差比对全局拓扑更敏感。例如,即使核心部分的全局拓扑相同,如果尾部或某些环具有不同的方向,则两种蛋白质结构的RMSD可能很高;仅根据 RMSD 值,这无法与两个结构具有完全不同的拓扑的情况区分开来。很少使用到。
越高越不相似
TM-scores
TM评分是评估蛋白质结构拓扑相似性的指标。它使用Levitt-Gerstein权重计算所有残基对。TM 分数对全局拓扑比局部变化更敏感。此外,由于它采用蛋白质大小依赖性量表来归一化残基距离,因此随机蛋白质对的TM评分的大小与蛋白质大小无关
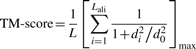
其中L是目标蛋白的长度,Lali是两种蛋白质中等效残基的数量。d i 是两个结构之间等效残基的第 i 对的距离,取决于叠加矩阵;“max”表示确定使公式(1)中的总和最大化的最佳叠加矩阵的过程。规模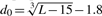 定义为标准化 TM 评分,即随机蛋白质对的平均 TM 评分的大小与蛋白质的大小无关。
定义为标准化 TM 评分,即随机蛋白质对的平均 TM 评分的大小与蛋白质的大小无关。
TM 分数保持在 (0, 1) 中,值越高表示相似性越强。
GDT 分数
GDT 分数被广泛用于社区范围的CASP和CAFASP实验,以评估蛋白质结构预测的建模准确性,随机结构对的GDT和MaxSub评分的大小与蛋白质长度具有幂律依赖性(Zhang和Skolnick,[2004](javascript:声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

