
- 1Android执行带有通配符的shell命令_安卓 文件通配符
- 2短信拦截转发器----Android_短信转发器
- 3TextRank:Gensim使用的文本摘要算法_gensim摘要
- 4Hive小文件问题:如何产生、造成影响,2024年最新阿里p7面试要求_hive小文件产生的原因
- 5数据分析师面试必备,数据分析面试题集锦(二)_数据分析师二面会问什么
- 6解决Xcode7真机调试出现:The account “” has no team with ID “”_在 xcode 的偏好设置的【accounts】中添加 apple id 账号
- 7使用OneNetAI的API实现AI图像识别,安全帽检测_从onenet获取图片进行识别
- 8深入分析 Android Activity (八)
- 9微服务架构了解_arcgis server是微服务架构吗
- 102024年中国AI大模型产业发展报告:开启智能新时代_伴随人工智能技术的加速演进,ai大模型已成为全球科技竞争的新高地、未来产业的新
Spark SQL函数详解:案例解析(第8天)
赞
踩
系列文章目录
1- Spark SQL函数定义(掌握)
2- Spark 原生自定义UDF函数案例解析(掌握)
3- Pandas自定义函数案例解析(熟悉)
4- Apache Arrow框架案例解析(熟悉)
5- spark常见面试题
前言
本文主要通过案例解析工作中常用的Spark SQL函数,以及应用场景
一、Spark SQL函数定义(掌握)
1. 窗口函数
回顾之前学习过的窗口函数:
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])
分析函数可以大致分成如下3类:
1- 第一类: 聚合函数 sum() count() avg() max() min()
2- 第二类: 排序函数 row_number() rank() dense_rank()
3- 第三类: 其他函数 ntile() first_value() last_value() lead() lag()
三个排序函数的区别?
row_number(): 巧记 1234 特点: 唯一且连续
rank(): 巧记 1224 特点: 并列不连续
dense_rank(): 巧记 1223 特点: 并列且连续
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在Spark SQL中使用窗口函数案例:
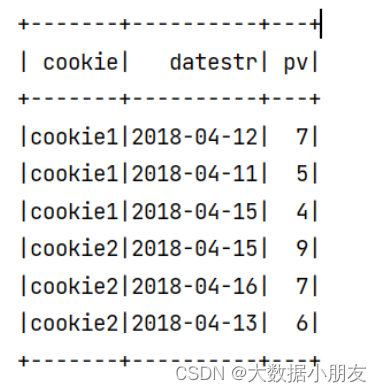
已知数据如下:
cookie1,2018-04-10,1 cookie1,2018-04-11,5 cookie1,2018-04-12,7 cookie1,2018-04-13,3 cookie1,2018-04-14,2 cookie1,2018-04-15,4 cookie1,2018-04-16,4 cookie2,2018-04-10,2 cookie2,2018-04-11,3 cookie2,2018-04-12,5 cookie2,2018-04-13,6 cookie2,2018-04-14,3 cookie2,2018-04-15,9 cookie2,2018-04-16,7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
需求: 要求找出每个cookie中pv排在前3位的数据,也就是分组取TOPN问题
# 导包 import os from pyspark.sql import SparkSession,functions as F,Window as W # 绑定指定的python解释器 os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3' # 创建main函数 if __name__ == '__main__': # 1.创建SparkContext对象 spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate() # 2.数据输入 df = spark.read.csv( path='file:///export/data/spark_project/spark_sql/data/cookie.txt', sep=',', schema='cookie string,datestr string,pv int' ) # 3.数据处理(切分,转换,分组聚合) # 4.数据输出 etldf = df.dropDuplicates().dropna() # SQL方式 etldf.createTempView('cookie_logs') spark.sql( """ select cookie,datestr,pv from ( select cookie,datestr,pv, dense_rank() over(partition by cookie order by pv desc) as rn from cookie_logs ) temp where rn <=3 """ ).show() # DSL方式 etldf.select( 'cookie', 'datestr', 'pv', F.dense_rank().over( W.partitionBy('cookie').orderBy(F.desc('pv')) ).alias('rn') ).where('rn <=3').select('cookie', 'datestr', 'pv').show() # 5.关闭资源 spark.stop()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
运行结果截图:
2. 自定义函数背景
2.1 回顾函数分类标准
SQL函数,主要分为以下三大类:
- UDF函数:普通函数
- 特点:一对一,输入一个得到一个
- 例如:split() …
- UDAF函数:聚合函数
- 特点:多对一,输入多个得到一个
- 例如:sum() avg() count() min() max() …
- UDTF函数:表生成函数
- 特点:一对多,输入一个得到多个
- 例如:explode() …
在SQL中提供的所有的内置函数,都是属于以上三类中某一类函数
2.2 自定义函数背景
思考:有这么多的内置函数,为啥还需要自定义函数呢?
为了扩充函数功能。在实际使用中,并不能保证所有的操作函数都已经提前的内置好了。很多基于业务处理的功能,其实并没有提供对应的函数,提供的函数更多是以公共功能函数。此时需要进行自定义,来扩充新的功能函数
- 1
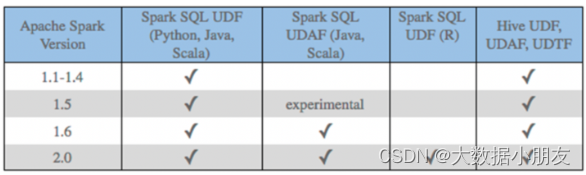
在Spark SQL中,针对Python语言,对于自定义函数,原生支持的并不是特别好。目前原生仅支持自定义UDF函数,而无法自定义UDAF函数和UDTF函数。
在1.6版本后,Java 和scala语言支持自定义UDAF函数,但Python并不支持。
1- SparkSQL原生的时候,Python只能开发UDF函数
2- SparkSQL借助其他第三方组件(Arrow,pandas...),Python可以开发UDF、UDAF函数,同时也提升效率
- 1
- 2
Spark SQL原生UDF函数存在的问题:大量的序列化和反序列
虽然Python支持自定义UDF函数,但是其效率并不是特别的高效。因为在使用的时候,传递一行处理一行,返回一行的方式。这样会带来非常大的序列化的开销的问题,导致原生UDF函数效率不好
早期解决方案: 基于Java/Scala来编写自定义UDF函数,然后基于python调用即可
目前主要的解决方案: 引入Arrow框架,可以基于内存来完成数据传输工作,可以大大的降低了序列化的开销,提供传输的效率,解决原生的问题。同时还可以基于pandas的自定义函数,利用pandas的函数优势完成各种处理操作
- 1
- 2
- 3
- 4
- 5
二、Spark原生自定义UDF函数
1. 自定义函数流程
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可 第二步: 将Python函数注册到Spark SQL中 注册方式一: udf对象 = sparkSession.udf.register(参数1,参数2,参数3) 参数1: 【UDF函数名称】,此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范 参数2: 【自定义的Python函数】,表示将哪个Python的函数注册为Spark SQL的函数 参数3: 【UDF函数的返回值类型】。用于表示当前这个Python的函数返回的类型 udf对象: 返回值对象,是一个UDF对象,可以在DSL中使用 说明: 如果通过方式一来注册函数, 【可以用在SQL和DSL】 注册方式二: udf对象 = F.udf(参数1,参数2) 参数1: Python函数的名称,表示将那个Python的函数注册为Spark SQL的函数 参数2: 返回值的类型。用于表示当前这个Python的函数返回的类型 udf对象: 返回值对象,是一个UDF对象,可以在DSL中使用 说明: 如果通过方式二来注册函数,【仅能用在DSL中】 注册方式三: 语法糖写法 @F.udf(returnType=返回值类型) 放置到对应Python的函数上面 说明: 实际是方式二的扩展。如果通过方式三来注册函数,【仅能用在DSL中】 第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
1.1 自定义演示一
需求1: 请自定义一个函数,完成对 数据 统一添加一个后缀名的操作 , 例如后缀名 ‘_itheima’
效果如下:

# 导包 import os from pyspark.sql import SparkSession,functions as F from pyspark.sql.types import StringType # 绑定指定的python解释器 os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3' # 创建main函数 if __name__ == '__main__': # 1.创建SparkContext对象 spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate() # 2.数据输入 df = spark.createDataFrame( data=[(1,'张三','广州'),(2,'李四','深圳')], schema='id int,name string,address string' ) df.show() # 3.SparkSQL自定义udf函数 # 第一步.自定义python函数 def add_suffix(data): return data+'_itheima' # 第二步.把python函数注册到SparkSQL # ① spark.udf.register注册 dsl1_add_suffix = spark.udf.register('sql_add_suffix',add_suffix,StringType()) # ②F.udf注册 dsl2_add_suffix = F.udf(add_suffix, StringType()) # ③@F.udf注册 @F.udf( StringType()) def candy_add_suffix(data): return data+'_itheima' # 第三步.在SparkSQL中调用自定义函数 # SQL方式 df.createTempView('temp') spark.sql( """select id,name,sql_add_suffix(address) as new_address from temp""" ).show() # DSL方式 # 调用dsl1_add_suffix df.select( 'id', 'name', dsl1_add_suffix('address').alias('new_address') ).show() # 调用dsl2_add_suffix df.select( 'id', 'name', dsl2_add_suffix('address').alias('new_address') ).show() # 调用candy_add_suffix df.select( 'id', 'name', candy_add_suffix('address').alias('new_address') ).show() # 4.关闭资源 spark.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
博主友情提醒: 可能遇到的问题如下
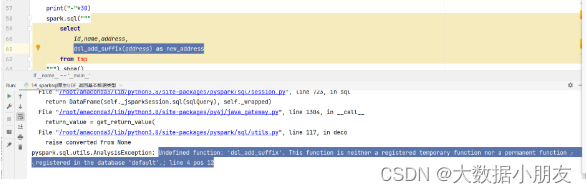
原因: 在错误的地方调用了错误的函数。spark.udf.register参数1取的函数名只能在SQL中使用,不能在DSL中用。
- 1
1.2 自定义演示二
需求2: 请自定义一个函数,返回值类型为复杂类型: 列表
效果如下:

参考代码:
# 导包 import os from pyspark.sql import SparkSession,functions as F from pyspark.sql.types import StringType, ArrayType # 绑定指定的python解释器 os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3' # 创建main函数 if __name__ == '__main__': # 1.创建SparkContext对象 spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate() # 2.数据输入 df = spark.createDataFrame( data=[(1,'张三_广州'),(2,'李四_深圳')], schema='id int,name_address string' ) df.show() # 3.SparkSQL自定义udf函数 # 第一步.自定义python函数 def my_split(data:str): list1 = data.split('_') return list1 # 第二步.把python函数注册到SparkSQL # ① spark.udf.register注册 dsl1_add_suffix = spark.udf.register('sql_add_suffix',my_split,ArrayType(StringType())) # ②F.udf注册 dsl2_add_suffix = F.udf(my_split, ArrayType(StringType())) # ③@F.udf注册 @F.udf(ArrayType(StringType())) def candy_add_suffix(data): list1 = data.split('_') return list1 # 第三步.在SparkSQL中调用自定义函数 # SQL方式 df.createTempView('temp') spark.sql( """select id,sql_add_suffix(name_address) as new_address from temp""" ).show() # DSL方式 # 调用dsl1_add_suffix df.select( 'id', dsl1_add_suffix('name_address').alias('new_name_address') ).show() # 调用dsl2_add_suffix df.select( 'id',dsl2_add_suffix('name_address').alias('new_name_address') ).show() # 调用candy_add_suffix df.select( 'id',candy_add_suffix('name_address').alias('new_name_address') ).show() # 4.关闭资源 spark.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
1.3 自定义演示三
需求3: 请自定义一个函数,返回值类型为复杂类型: 字典
效果如下:

注意: 注意: 如果是字典类型,StructType中列名需要和字典的key值一致,否则是null补充
- 1
# 导包 import os from pyspark.sql import SparkSession,functions as F from pyspark.sql.types import StringType, ArrayType, StructType # 绑定指定的python解释器 os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3' # 创建main函数 if __name__ == '__main__': # 1.创建SparkContext对象 spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate() # 2.数据输入 df = spark.createDataFrame( data=[(1,'张三_广州'),(2,'李四_深圳')], schema='id int,name_address string' ) df.show() # 3.SparkSQL自定义udf函数 # 第一步.自定义python函数 def my_split(data:str): list1 = data.split('_') return {'name':list1[0],'address':list1[1]} # 第二步.把python函数注册到SparkSQL # 注意: 如果是字典类型,StructType中列名需要和字典的key值一致,否则是null t = StructType().add('name',StringType()).add('address',StringType()) # ① spark.udf.register注册 dsl1_add_suffix = spark.udf.register('sql_add_suffix',my_split,t) # ②F.udf注册 dsl2_add_suffix = F.udf(my_split, t) # ③@F.udf注册 @F.udf(t) def candy_add_suffix(data): list1 = data.split('_') return {'name':list1[0],'address':list1[1]} # 第三步.在SparkSQL中调用自定义函数 # SQL方式 df.createTempView('temp') spark.sql( """select id,sql_add_suffix(name_address) as new_name_address from temp""" ).show() # DSL方式 # 调用dsl1_add_suffix df.select( 'id', dsl1_add_suffix('name_address').alias('new_name_address') ).show() # 调用dsl2_add_suffix df.select( 'id',dsl2_add_suffix('name_address').alias('new_name_address') ).show() # 调用candy_add_suffix df.select( 'id',candy_add_suffix('name_address').alias('new_name_address') ).show() # 4.关闭资源 spark.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
三、Pandas的自定义函数
1. Apache Arrow框架
Apache Arrow是Apache旗下的一款顶级的项目。是一个跨平台的在内存中以列式存储的数据层,它的设计目标就是作为一个跨平台的数据层,来加快大数据分析项目的运行效率
Pandas 与 Spark SQL 进行交互的时候,建立在Apache Arrow上,带来低开销 高性能的UDF函数
如何安装? 三个节点建议都安装(注:集群搭建后续会更新)
检查服务器上是否有安装pyspark
pip list | grep pyspark 或者 conda list | grep pyspark
如果服务器已经安装了pyspark的库,那么仅需要执行以下内容,即可安装。例如在 node1安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark[sql]
如果服务器中python环境中没有安装pyspark,建议执行以下操作,即可安装。例如在 node2 和 node3安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyarrow==16.1.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Arrow并不会自动使用,在某些情况下,需要配置 以及在代码中需要进行小的更改才可以使用
如何使用呢? 默认不会自动启动的, 一般建议手动配置
spark.conf.set('spark.sql.execution.arrow.pyspark.enabled',True)
- 1
2. 基于Arrow完成Pandas和Spark的DataFrame互转
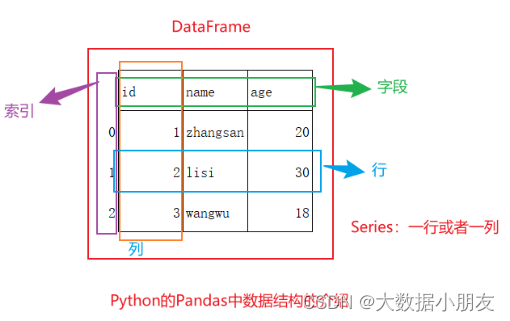
Pandas中DataFrame:
DataFrame:表示一个二维表对象,就是表示整个表
字段、列、索引;Series表示一列
Spark SQL中DataFrame:
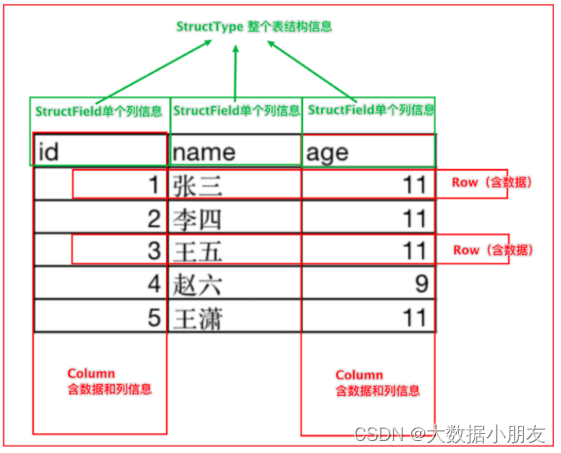
使用场景:
1- Spark的DataFrame -> Pandas的DataFrame:当大数据处理到后期的时候,可能数据量会越来越少,这样可以考虑使用单机版的Pandas来做后续数据的分析
2- Pandas的DataFrame -> Spark的DataFrame:当数据量达到单机无法高效处理的时候,或者需要和其他大数据框架集成的时候,可以转成Spark中的DataFrame
Pandas的DataFrame -> Spark的DataFrame: spark.createDataFrame(data=pandas_df)
Spark的DataFrame -> Pandas的DataFrame: init_df.toPandas()
- 1
- 2
示例:
# 导包 import os from pyspark.sql import SparkSession # 绑定指定的python解释器 os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3' # 创建main函数 if __name__ == '__main__': # 1.创建SparkContext对象 spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate() # TODO: 手动开启arrow框架 spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True) # 2.数据输入 df = spark.createDataFrame( data=[(1,'张三_广州'),(2,'李四_深圳')], schema='id int ,name_address string' ) df.show() print(type(df)) print('------------------------') # 3.数据处理(切分,转换,分组聚合) # 4.数据输出 # spark->pandas pd_df = df.toPandas() print(pd_df) print(type(pd_df)) print('------------------------') # pandas->spark df2 = spark.createDataFrame(pd_df) df2.show() print(type(df2)) # 5.关闭资源 spark.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
3. 基于Pandas自定义函数
基于Pandas的UDF函数来转换为Spark SQL的UDF函数进行使用。底层是基于Arrow框架来完成数据传输,允许向量化(可以充分利用计算机CPU性能)操作。
Pandas的UDF函数其实本质上就是Python的函数,只不过函数的传入数据类型为Pandas的类型
基于Pandas的UDF可以使用自定义UDF函数和自定义UDAF函数
3.1 自定义函数流程
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可 第二步: 将Python函数包装成Spark SQL的函数 注册方式一: udf对象 = spark.udf.register(参数1, 参数2) 参数1: UDF函数名称。此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范 参数2: Python函数的名称。表示将哪个Python的函数注册为Spark SQL的函数 使用: udf对象只能在DSL中使用。参数1指定的名称只能在SQL中使用 注册方式二: udf对象 = F.pandas_udf(参数1, 参数2) 参数1: 自定义的Python函数。表示将哪个Python的函数注册为Spark SQL的函数 参数2: UDF函数的返回值类型。用于表示当前这个Python的函数返回的类型对应到Spark SQL的数据类型 udf对象: 返回值对象,是一个UDF对象。仅能用在DSL中使用 注册方式三: 语法糖写法 @F.pandas_udf(returnType) 放置到对应Python的函数上面 说明: 实际是方式二的扩展。仅能用在DSL中使用 第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可 基于pandas方式还支持自定义UDAF函数 注意: 如果要用于自定义UDAF函数,理论上只能用上述注册方式三语法糖方式,也就意味着理论只能DSL使用 注意: 如果还想同时用SQL方式和DSL方式,可以把加了语法糖的函数,再传入到方式register注册,就可以使用了!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.2 自定义UDF函数
-
自定义Python函数的要求:SeriesToSeries
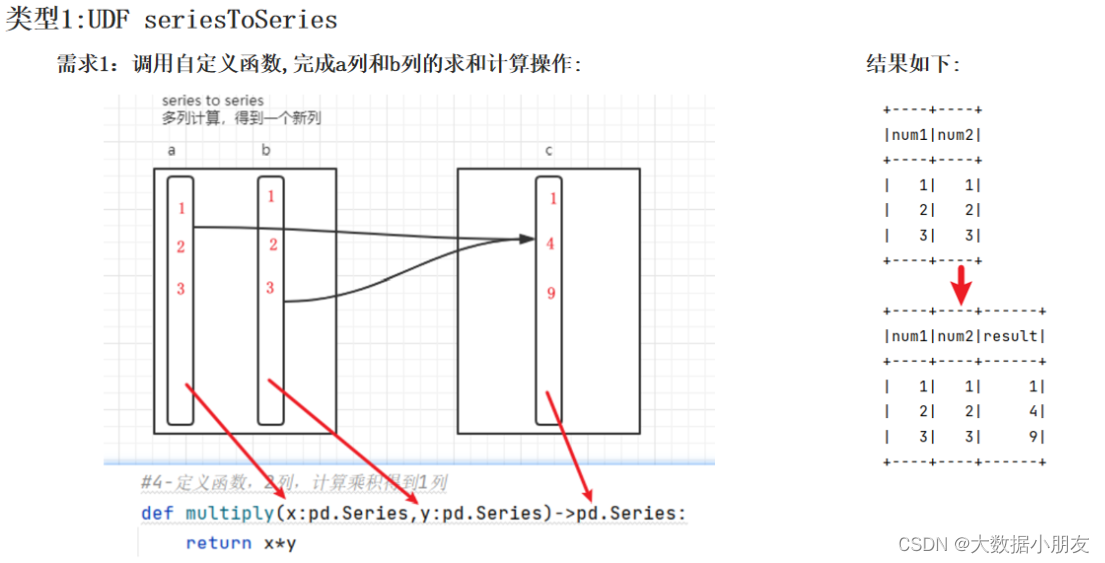
# 导包 import os from pyspark.sql import SparkSession,functions as F import pandas as pd # 绑定指定的python解释器 from pyspark.sql.types import LongType, IntegerType os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3' # 创建main函数 if __name__ == '__main__': # 1.创建SparkContext对象 spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate() # TODO: 开启Arrow的使用 spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', 'True') # 2.数据输入 df = spark.createDataFrame( data = [(1,1),(2,2),(3,3)], schema= 'num1 int,num2 int' ) df.show() # 3.基于pandas自定义函数 :SeriesTOSeries # 第一步: 自定义python函数 def multiply(num1:pd.Series,num2:pd.Series)->pd.Series: return num1*num2 # 第二步: 把python注册为SparkSQL函数 # ①spark.udf.register注册 dsl1_multiply = spark.udf.register('sql_multiply',multiply) # ②F.pandas_udf注册 dsl2_multiply = F.pandas_udf(multiply,IntegerType()) # ③@F.pandas_udf注册 @F.pandas_udf(IntegerType()) def candy_multiply(num1: pd.Series, num2: pd.Series) -> pd.Series: return num1 * num2 # 第三步: 在SparkSQL中调用注册后函数 # SQL方式 df.createTempView('temp') spark.sql( """select num1,num2,sql_multiply(num1,num2) as result from temp""" ).show() # DSL方式 #调用dsl1_multiply df.select( 'num1','num2',dsl1_multiply('num1','num2').alias('result') ).show() # 调用dsl2_multiply df.select( 'num1', 'num2', dsl2_multiply('num1', 'num2').alias('result') ).show() # 调用candy_multiply df.select( 'num1', 'num2', candy_multiply('num1', 'num2').alias('result') ).show() # 4.关闭资源 spark.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
3.3 自定义UDAF函数
-
自定义Python函数的要求:Series To 标量
表示:自定义函数的输入数据类型是Pandas中的Series对象,返回值数据类型是标量数据类型。也就是Python中的数据类型,例如:int、float、bool、list…
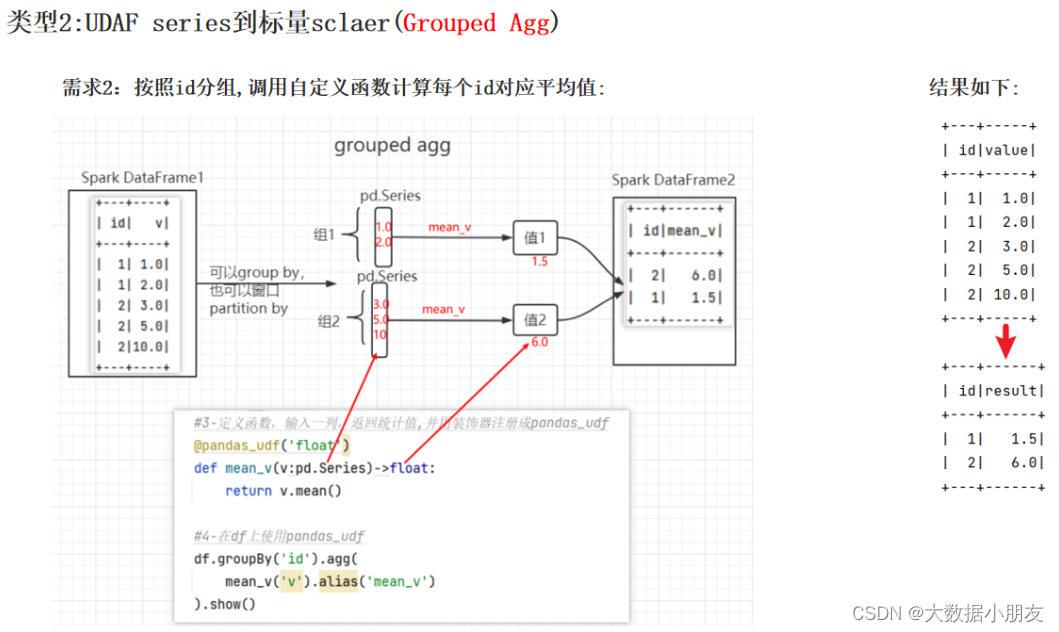
基于pandas方式还支持自定义UDAF函数
注意: 如果要用于自定义UDAF函数,理论上只能用上述注册方式三语法糖方式,也就意味着理论只能DSL使用
注意: 如果还想同时用SQL方式和DSL方式,可以把加了语法糖的函数,再传入到方式register注册,就可以使用了!
- 1
- 2
- 3
# 导包 import os from pyspark.sql import SparkSession, functions as F import pandas as pd # 绑定指定的python解释器 from pyspark.sql.types import LongType, IntegerType, FloatType os.environ['SPARK_HOME'] = '/export/server/spark' os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3' # 创建main函数 if __name__ == '__main__': # 1.创建SparkContext对象 spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate() # TODO: 开启Arrow的使用 spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', 'True') # 2.数据输入 df = spark.createDataFrame( data=[(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)], schema='id int,value float' ) df.show() # 3.基于pandas自定义函数 :SeriesTOSeries # 第一步: 自定义python函数 # ③@F.pandas_udf注册 注意: 理论上UDAF只能用注册方式三语法糖方式,也就意味着只能DSL使用 @F.pandas_udf(FloatType()) def candy_mean_v(value: pd.Series) -> float: return value.mean() # 第二步: 注意: 如果还想同时用SQL方式和DSL方式,可以把加了语法糖的函数,再传入到方式一register注册 # ①spark.udf.register注册 dsl1_mean_v = spark.udf.register('sql_mean_v', candy_mean_v) # 第三步: 在SparkSQL中调用注册后函数 # DSL方式 # 调用candy_mean_v df.groupBy('id').agg( candy_mean_v('value').alias('result') ).show() # 调用dsl1_mean_v df.groupBy('id').agg( dsl1_mean_v('value').alias('result') ).show() # SQL方式 df.createTempView('temp') spark.sql( """select id,sql_mean_v(value) as result from temp group by id""" ).show() # 4.关闭资源 spark.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
四、Spark常见面试题
1. Spark client 和Spark cluster的区别?
区别是driver 进程在哪运行,client模式driver运行在master节点上,不在worker节点上;cluster模式
driver运行在worker集群某节点上,不在master节点上。
一般来说,如果提交任务的节点(即Master)和Worker集群在同一个网络内,此时client mode比较合
适。
如果提交任务的节点和Worker集群相隔比较远,就会采用cluster mode来最小化Driver和Executor之间
的网络延迟。
yarn client模式:driverzai当前提交任务的节点上,可以打印任务运行的日志信息。
yarn cluster模式:driver在AppMaster所有节点上,分布式分配,不能再提交任务的本机打印日志信
息。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2. Spark常用端口号
Spark-shell任务端口:4040
内部通讯端口:7077
查看任务执行情况端口:8080
历史服务器:18080
Oozie端口号:11000
- 1
- 2
- 3
- 4
- 5
3. Repartitons和Coalesce区别
- 关系:两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方 法:
coalesce(numPartitions, shuffle = true) - 区别:repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle 一般情况
下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用 coalesce。

