
- 1Java工具类 - 根据左上角坐标和右下角坐标裁剪图片_w5h.cc
- 2[AIGC] 分布式锁及其实现方式详解与Python代码示例_python分布式锁机制
- 3MySQL如何跳过密码认证进行重置密码_mysql跳过密码验证修改密码
- 4【数智化人物展】数势科技创始人兼CEO黎科峰:数智化时代To B软件行业面临颠覆与重塑...
- 5推荐系统相关技术_做推荐系统需要哪些技术
- 6TreeSet&从树到红黑树_treeset什么时候会转化为红黑树
- 7【Linux】基础IO —— 系统文件IO | 文件描述符fd | inode | 重定向原理 | 缓冲区 | 软硬链接_file descriptor inode
- 8android与java web交互完成简单的登录和注册_android 调用java 做的webservice登录功能
- 9【Spring Cloud】Gateway 服务网关限流
- 10“开源与闭源AI模型的比较与未来发展趋势“
STL - 容器篇
赞
踩
目录
由于STL种类繁多,所以这里只是挑几个最具代表性的来做讲解,想要查询具体的容器及其使用,可以参考官方网站:Containers - C++ Reference (cplusplus.com)
STL简介
STL(standard template libaray - 标准模板库)是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
STL的一些版本
- 原始版本
Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。 HP 版本即所有STL实现版本的始祖。
- P. J. 版本
由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
- RW版本
由Rouge Wage公司开发,继承自HP版本,不能公开或修改,可读性一般。
- SGI版本
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版本。被GCC采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。
STL的6大组件

STL的一些缺陷
- STL库的更新慢。上一版靠谱是C++98,中间的C++03基本一些修订。C++11出来已经相隔了13年,STL才进一步更新。
- STL不支持线程安全。并发环境下需要我们自己加锁。且锁的粒度是比较大的。
- STL极度的追求效率,导致内部比较复杂。比如类型萃取,迭代器萃取。
- STL的使用会有代码膨胀的问题,比如使用vector<int> / vector<double> / vector<char> 这样会生成多份代码,当然这是由于模板语法本身导致的。
——截至2023-8-19
string
C++ 大大增强了对字符串的支持,除了可以使用C风格的字符串,还可以使用内置的string类。string类处理起字符串来会方便很多,完全可以代替C语言中的字符数组或字符串指针。要注意,string类本不是STL的容器,但是作为一种约定俗成的习惯,还是把string这里介绍。
string接口的参考文档:
参考文档:string - C++ Reference (cplusplus.com)
介意英文可以看下面这个:
string常用接口 - 用法示例
- part1:构造与赋值
- string s1; // 无参构造
- string s2(10, 65); // 有参构造,开局10个'A'
- string s3("hello world"); // 拷贝构造
- s1 = s3; // operator =
- string s4(s3, 2, 5);
- const char* str = "abcdefg";
- string s5(str);
- string s6(str, 5);
- part2:迭代器
begin():指向容器第一个元素的位置(可读可写)
rbegin():指向容器最后一个元素的位置(可读可写)
cbegin():指向容器第一个元素的位置(只读)
crbegin():指向容器最后一个元素的位置(只读)
end():指向容器最后一个元素的下一个位置(可读可写)
rend():指向容器第一个元素的前一个位置(可读可写)
cend():指向容器最后一个元素的下一个位置(只读)
crend():指向容器第一个元素的前一个位置(只读)
- // 正向非常量迭代器,可以正常读写
- string str1("hello world");
- string::iterator beg = str1.begin();
- while (beg != str1.end())
- {
- cout << ++ * beg << " ";
- beg++;
- }
- cout << endl;
-
- // 反向非常量迭代器,反方向正常读写
- string str2("hello world");
- string::reverse_iterator rbeg = str2.rbegin();
- while (rbeg != str2.rend())
- {
- cout << ++ * rbeg << " ";
- rbeg++;
- }
- cout << endl;
-
- // 正向常量迭代器,只能读不能写
- string str3("hello world");
- string::const_iterator cbeg = str3.cbegin();
- while (cbeg != str3.end())
- {
- //cout << ++*cbeg << " "; // error
- cout << *cbeg << " ";
- cbeg++;
- }
- cout << endl;
-
- // 反向常量迭代器,反方向只读不写
- string str4("hello world");
- string::const_reverse_iterator crbeg = str4.crbegin();
- while (crbeg != str4.crend())
- {
- //cout << ++*crbeg << " "; // error
- cout << *crbeg << " ";
- crbeg++;
- }
- cout << endl;

- part3:容量相关
- string str = "hello world";
- // size方法:Return length of string(不包含最后的'\0')
- cout << "str_size: " << str.size() << endl;
- // length方法与size方法效果相同
- cout << "str_length: " << str.length() << endl;
- // max_size方法:Return maximum size of string(没有实际的参考性)
- cout << "str_max_size: " << str.max_size() << endl;
- // resize方法:改变size,但不改变容量大小
- // capacity方法:获取string的容器大小
- str.resize(5);
- cout << str << endl;
- cout << "str_size: " << str.size() << endl;
- cout << "str_capacity: " << str.capacity() << endl;
- // reverse方法:尝试更改容量大小(只有当变大的时候生效)
- str.reserve(5);
- cout << "change_5_capacity_result: " << str.capacity() << endl;
- str.reserve(20);
- cout << "change_20_capacity_result: " << str.capacity() << endl;
- // clear方法:清空string
- str.clear();
- // empty方法:判空
- cout << str.empty() << endl;
- // shrink_to_fit方法:尝试缩容
- // 函数原型:void shrink_to_fit();
- // This function has no effect on the string length and cannot alter its content.
- str = "123456789";
- cout << "size: " << str.size() << "capacity: " << str.capacity() << endl;
- str.shrink_to_fit();
- cout << "size: " << str.size() << "capacity: " << str.capacity() << endl;
part4:数据访问
- string str = "hello world";
- cout << str[3] << endl; //operator[] - 越界触发断言
- cout << str.at(7) << endl; // at方法 - 越界抛异常
- cout << str.back() << endl; // back方法:访问最后一个字符
- cout << str.front() << endl; // front方法:访问第一个字符
part5:数据操作
- string s1 = "hello ";
- string s2 = "world";
- // operator+=
- s1 += s2;
- cout << s1 << endl;
- // append:在字符串尾添加字符串或单个字符
- s2.append(" good");
- cout << s2 << endl;
- // push_back:尾插单个字符
- s1.push_back('!');
- cout << s1 << endl;
- // assign:赋值,效果与operator=一样
- string s3;
- s3.assign(s2);
- cout << s3 << endl;
- // insert:在任意位置插入(下标从0开始)
- s3.insert(5, "*******");
- cout << s3 << endl;
- // erase:按下标/迭代器的位置删除n个
- s3.erase(5, 3); // 从下标5开始,删除3个
- cout << s3 << endl;
- // replace:将指定位置的n个字串替换为另一段字符串
- s3.replace(5, 3, " *-* ");
- cout << s3 << endl;
- // swap:交换两个string对象。对应的size和capacity也原封不动的交换
- s3.swap(s2);
- cout << s2 << endl;
- // pop_back:尾删单个字符
- s3.pop_back();
- cout << s3 << endl;
顺序性容器
vector
vector是表示可变大小数组的序列容器。也就是顺序表。像数组一样,vector也是采用的连续存储空间来存储数据的,即可以随机访问容器内的元素。但vector又不完全等同于数组,vector的容量是动态的,会在适当的时候对容器进行扩容。
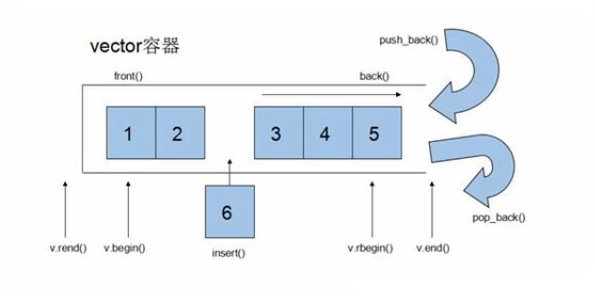
本质上讲,vector使用动态内存分配的数组来存储它的元素。而且vector会分配一些额外的空间以应对未来的插入等操作,所以vector开的空间是大于等于我们真正使用的空间的,不同的库采用不同的策略权衡空间的分配机制。因此,vector占用了更多的存储空间,以获得管理存储空间的能力,并且以一种有效的方式动态增长。
上面讲了string的相关功能的使用,与之不同的是,string是一个实例化的类型,而vector是一个还未实例化的类模板,所以使用vector时还需要显示的指定数据类型。例如:
- string str = "hello world!"; // string不需要指定类型,直接拿来用
- vector<int> v = { 1,3,5,7,8,10,12,31 }; // 显示的指定数据类型为int
所以,其它的容器,像list等,在使用时都需要显示的指定数据类型以实例化出具体的类型。
需要注意的是,像vector<vector<int>>这种类型可以类比二维数组来理解,比如int arr[5][6]表示arr是一个大小为5的数组,数组中的每一个元素是一个大小为6的数组。而vector<vector<int>>表示这是一个vector容器,容器中的元素也是一个vector容器。
由于STL中的接口具有很强的规范性,所以vector和string的功能使用基本上都是大同小异,那么就不用再过多的赘述了,vector功能的使用参考如下:
参考文档:vector - C++ Reference (cplusplus.com)
介意英文可以看下面这个:
deque
deque (double ended queue),双端队列,头文件<deque>。是一种可以在两端扩展或收缩的序列化容器,即deque的头部和尾部都可以进行插入和删除等操作。
与vector不同,deque容器存储数据的空间是由一段一段等长的连续空间构成,各段空间之间并不一定是连续的,可以位于在内存的不同区域,使用一个中控器(指针数组)map来指向这些一段一段的空间,如果当前段空间满了,就添加一个新的空间段链接在头部或尾部。结构示意图如下:
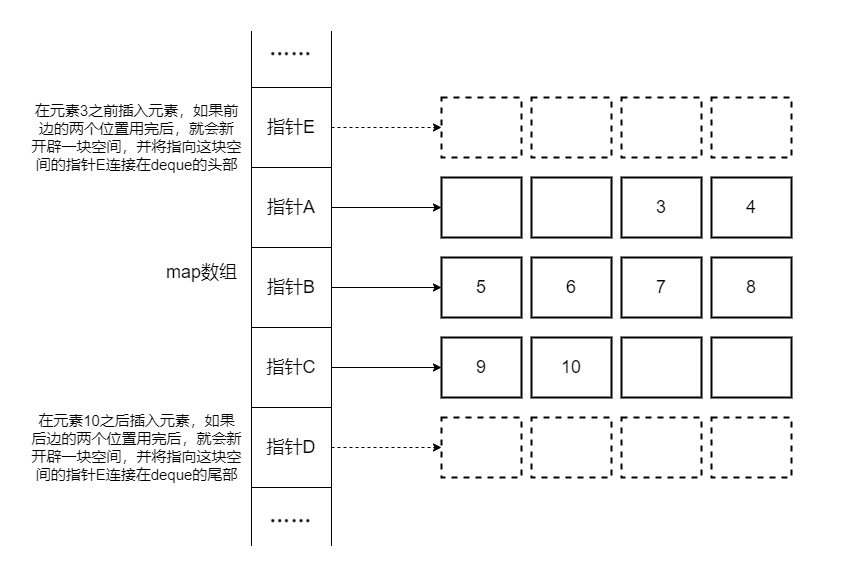
在容器的使用上,deque和vector极其相似,所以就不再过多阐述了,如有疑惑可以参考:deque - C++ Reference (cplusplus.com)![]() https://legacy.cplusplus.com/reference/deque/deque/
https://legacy.cplusplus.com/reference/deque/deque/
list
list是C++标准库中的一种双向循环链表的容器,每个元素都包含指向前后元素的指针,使得插入和删除操作高效。然而,由于没有随机访问能力,访问元素可能相对较慢。与连续内存存储不同,list适用于需要频繁插入和删除而无需随机访问的场景。可以参照下图来理解。
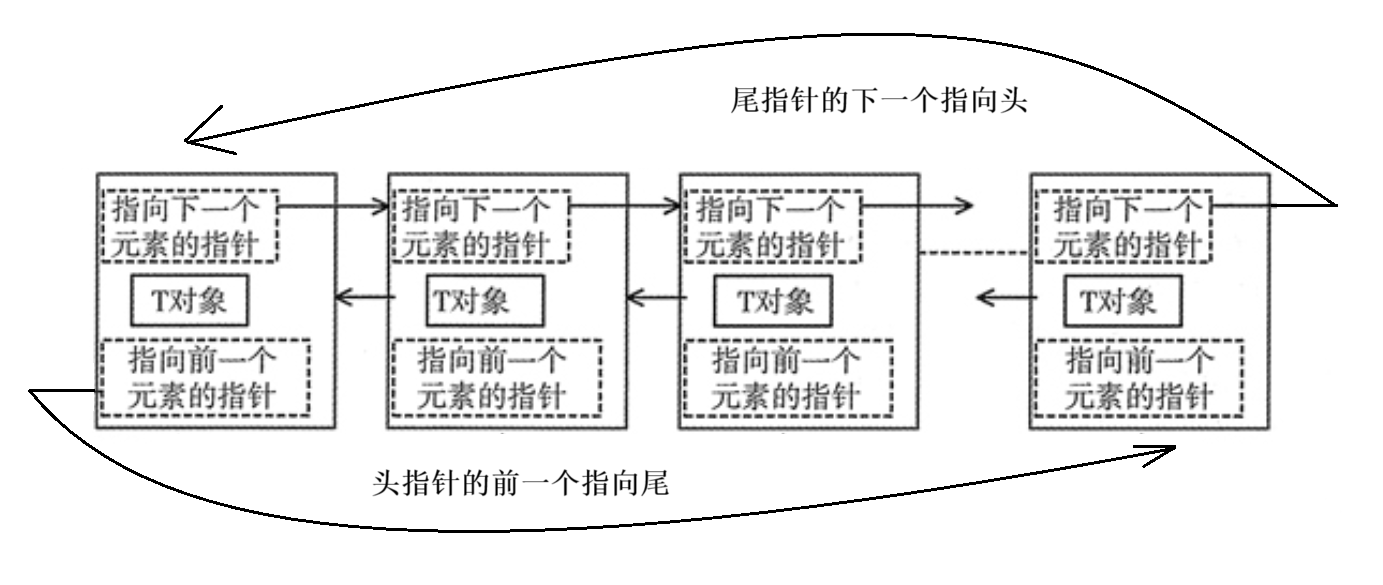
list的使用接口与vector类似,就不再细说了,具体参考如下:
参考文档:list - C++ Reference (cplusplus.com)
介意英文的可以看下面这个:
需要注意一点,vector容器是随机访问迭代器,list是双向迭代器。list的迭代器并不支持+和-的计算,也不支持像v[1]的这种索引操作,只支持了++等操作。这是因为,vector是一种顺序式容器,可以对容器内的任意位置随机访问,而list是一种链式结构,不能对数据进行随机访问。具体细节在“迭代器的类别”部分会细说。
list模拟实现
下面是我自己模拟实现的部分list容器的功能,本人在下面实现的这个list,只是为了更好的理解list的相关功能,并不是要写一个很完善的list容器。
list模拟实现/my_list.h · 大漂亮/Exercises_Warehouse - 码云 - 开源中国 (gitee.com)![]() https://gitee.com/JK1900/exercises_warehouse/blob/master/list%E6%A8%A1%E6%8B%9F%E5%AE%9E%E7%8E%B0/my_list.h在模拟实现list时发现了有如下这么几个需要注意的地方:
https://gitee.com/JK1900/exercises_warehouse/blob/master/list%E6%A8%A1%E6%8B%9F%E5%AE%9E%E7%8E%B0/my_list.h在模拟实现list时发现了有如下这么几个需要注意的地方:
- vector的迭代器可以直接用一个指针代替。而list的迭代器则是封装了一个节点的指针,封装了++、--等运算符重载及一些STL统一性的迭代器操作。
- 至于const迭代器和普通的迭代器,其实是两个类型,并不是单纯的在迭代器前面加个const这么简单的。反向迭代器同理。
- list类内将迭代器的类实例化出具体的类型并将其封装为iterator:
typedef ListIterator<T, T&, T*> iterator;- 链表的节点类型并不是在list类内维护的,而是有一个专门的节点类,维护了next、pre、val等成员变量。list维护的是一个链表,里面只有链表的头指针。
vector和list的区别
| vector | list | |
|---|---|---|
| 底层结构 | 动态顺序表,一段连续空间 | 带头结点的双向循环链表 |
| 随机访问 | 支持随机访问,访问某个元素效率O(1) | 不支持随机访问,访问某个元素效率O(N) |
| 插入和删除 | 任意位置插入和删除效率低,需要搬移元素,时间复杂度为O(N),插入时有可能需要增容,增容:开辟新空间,拷贝元素,释放旧空间,导致效率更低 | 任意位置插入和删除效率高,不需要搬移元素,时间复杂度为 O(1) |
| 空间利用率 | 底层为连续空间,不容易造成内存碎片,空间利用率高,缓存利用率高 | 底层节点动态开辟,小节点容易造成内存碎片,空间利用率低,缓存利用率低 |
| 迭代器 | 原生态指针 | 对原生态指针(节点指针)进行封装 |
| 迭代器失效 | 在插入元素时,要给所有的迭代器重新赋值,因为插入元素有可能会导致重新扩容,致使原来迭代器失效,删除时,当前迭代器需要重新赋值否则会失效 | 插入元素不会导致迭代器失效,删除元素时,只会导致当前迭代器失效,其他迭代器不受影响 |
| 使用场景 | 需要高效存储,支持随机访问,不关心插入删除效率 | 大量插入和删除操作,不关心随机访问 |
容器适配器
C++中还有一类特殊的容器,叫做容器适配器。适配器顾名思义,就是为了适配某些规则而对指定容器做适配的一个中转设备,从STL的角度来看,容器适配器是没有实体的。也就是说,容器适配器不是一种很纯粹的容器,它是直接使用的其它容器,以特定的规则组织而成的一类容器适配器。比如stack和queue默认使用的是deque容器,priority_queue默认使用的是vector容器。
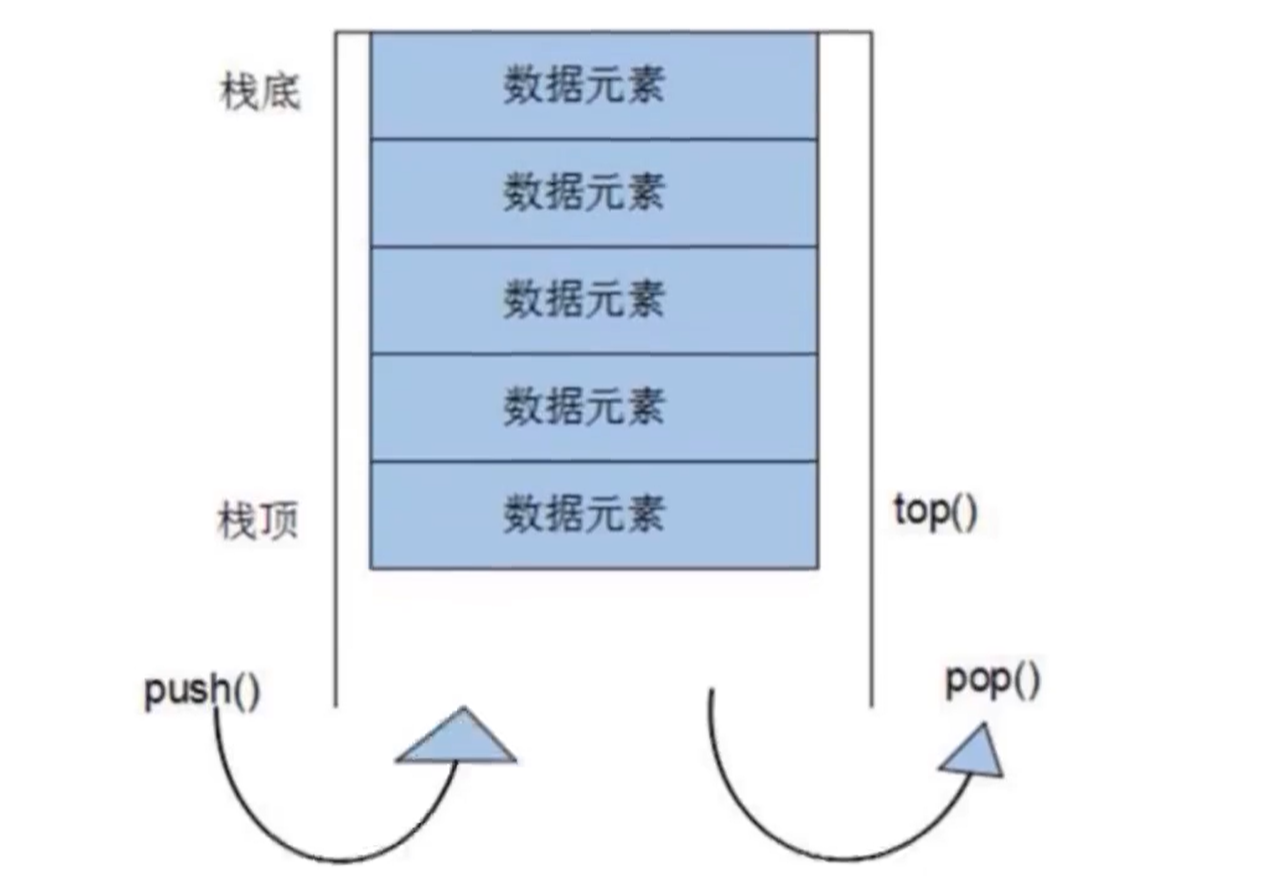
stack
![]()
stack,头文件<stack>。顾名思义就是“栈”这个数据结构的容器适配器,它底层默认是用的deque容器来实现的,当然也可以使用例如vector等指定的容器,不过指定容器需要提供支持如下这5个接口:empty、size、back、push_back、pop_back。其它详情见:stack - C++ Reference (cplusplus.com)![]() https://legacy.cplusplus.com/reference/stack/stack/
https://legacy.cplusplus.com/reference/stack/stack/
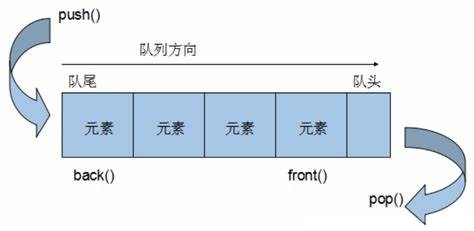
queue
![]()
queue,头文件<queue>,是队列这种数据结构的容器适配器,底层默认是用的deque容器实现的一种容器适配器。它也可以使用指定的容器,不过容器需要支持如下6个接口:empty、size、front、back、push_back、pop_back。其它详情见:queue - C++ Reference (cplusplus.com)![]() https://legacy.cplusplus.com/reference/queue/queue/
https://legacy.cplusplus.com/reference/queue/queue/
priority_queue
![]()
priority_queue,头文件<queue>,是堆这种数据结构的容器适配器。priority_queue底层默认使用的是vector容器,如果需要手动指定容器,那么对应的容器需要支持如下接口:empty、size、front、push_back、pop_back。需要注意的是,虽然priority_queue默认使用的比较规则是less,但less比较规则对应的是大根堆的数据结构。其它详情见:priority_queue - C++ Reference (cplusplus.com)![]() https://legacy.cplusplus.com/reference/queue/priority_queue/
https://legacy.cplusplus.com/reference/queue/priority_queue/
关联式容器 - map/set
set的特性是。所有元素都会根据元素的键值自动被排序,其中set的元素即是键值又是实值。set不允许两个元素有相同的键值。multiset特性及用法和set完全相同,唯一的差别在它允许键值重复。
set容器的迭代器一般使用只读迭代器,目的是不允许修改键值,修改键值会破坏set的内存布局。但是并不是说set容器只能使用只读迭代器,而是使用只读迭代器可以省去很多麻烦,是一种很好的选择。
map的特性是,所有元素都会根据键值自动排序。Map容器的所有的元素都是pair,同时拥有实值和键值,pair的第一元素被视为键值,第二元素被视为实值,Map不允许两个元素有相同的键值。
那我们可以通过map的迭代器改变map的键值吗?答案是不行,因为map的键值关系到map元素的排列规则,任意改变map键值将会严重破坏map组织。如果想要修改元素的实值,那么是可以的。Map和Set拥有相同的某些性质,当对它的容器元素进行新增操作或者删除操作时,操作之前的所有迭代器,在操作完成之后依然有效,但被删除的元素的迭代器是个例外。multimap和Map的操作类似,唯一区别multimap键值可重复。Map和multimap都是以红黑树为底层实现机制。
map容器重载了[]运算符,类似于数组的操作,[]内是键值,可以直接通过 .运算符访问成员。但如果这个键值没有存在过,它就会自动创建一个这个键值的map元素,因此说这是一种很危险的方式。所以使用这种方式时需要确保键值存在。
map的迭代器是以对组的形式存在的,是有相应的first元素和second的,所以要避免直接*迭代器这样的操作,需要*迭代器.first / *迭代器.second这样。
其中,map\set在底层实现上是红黑树,如果想要了解红黑树的话,可以参考如下这篇博客:红黑树详解-CSDN博客![]() https://blog.csdn.net/m0_73759312/article/details/134589089?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22134589089%22%2C%22source%22%3A%22m0_73759312%22%7D
https://blog.csdn.net/m0_73759312/article/details/134589089?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22134589089%22%2C%22source%22%3A%22m0_73759312%22%7D
内容补充
迭代器的种类
STL 标准库为每一种标准容器定义了一种迭代器类型,也就是说,不同容器的迭代器是不同的。虽然每一种容器的迭代器都是不同的,但功能类似的迭代器可以归为一个小类。这样,我们就把容器的迭代器分为5类:输入迭代器、输出迭代器、前向迭代器、双向迭代器、随机访问迭代器。
- 输入迭代器和输出迭代器
输入迭代器和输出迭代器通常与输入输出流类(iostream)一起使用,用于从输入流(如键盘、文件等)读取数据,或将数据写入输出流(如屏幕、文件等)。在C++标准库中,为了方便处理输入输出,提供了名为 std::istream_iterator 和 std::ostream_iterator 的模板类,它们分别用作输入迭代器和输出迭代器。
std::istream_iterator:它允许你从输入流读取数据,并以迭代器的方式访问这些数据。
std::ostream_iterator:它允许你以迭代器的方式将数据写入输出流。
这两个迭代器类别使得通过迭代器接口来处理输入输出操作变得更加方便,使得将输入输出操作与算法结合使用变得更加灵活。
不过,输入输出迭代器并不常用(个人观点),这里我们着重介绍后面三个。
内容参考:C++ STL迭代器(iterator)用法详解 (biancheng.net)
- 前向迭代器(forward iterator)
假设 p 是一个前向迭代器,则 p 支持 ++p,p++,*p 操作,还可以被复制或赋值,可以用 == 和 != 运算符进行比较。而且,两个正向迭代器可以互相赋值。
- 双向迭代器(bidirectional iterator)
双向迭代器具有正向迭代器的全部功能,除此之外,假设 p 是一个双向迭代器,则还可以进行 --p 或者 p-- 操作(即一次向后移动一个位置)。
- 随机访问迭代器(random access iterator)
随机访问迭代器具有双向迭代器的全部功能。除此之外,假设 p 是一个随机访问迭代器,i 是一个整型变量或常量,则 p 还支持以下操作:
- p+=i:使得 p 往后移动 i 个元素。
- p-=i:使得 p 往前移动 i 个元素。
- p+i:返回 p 后面第 i 个元素的迭代器。
- p-i:返回 p 前面第 i 个元素的迭代器。
- p[i]:返回 p 后面第 i 个元素的引用。
此外,两个随机访问迭代器 p1、p2 还可以用 <、>、<=、>= 运算符进行比较。另外,表达式 p2-p1 也是有定义的,其返回值表示 p2 所指向元素和 p1 所指向元素的序号之差(也可以说是 p2 和 p1 之间的元素个数减一)。
下表是 C++ 11 标准中不同容器指定使用的迭代器类型:
| 容器 | 对应的迭代器类型 |
|---|---|
| array | 随机访问迭代器 |
| vector | 随机访问迭代器 |
| deque | 随机访问迭代器 |
| list | 双向迭代器 |
| set / multiset | 双向迭代器 |
| map / multimap | 双向迭代器 |
| forward_list | 前向迭代器 |
| unordered_map / unordered_multimap | 前向迭代器 |
| unordered_set / unordered_multiset | 前向迭代器 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
迭代器的定义方式
虽然不同容器对应着不同类别的迭代器,但这些迭代器有着较为统一的定义方式,具体分为 4 种,如下所示:
| 迭代器定义方式 | 具体格式 |
|---|---|
| 正向迭代器 | 容器类名::iterator 迭代器名; |
| 常量正向迭代器 | 容器类名::const_iterator 迭代器名; |
| 反向迭代器 | 容器类名::reverse_iterator 迭代器名; |
| 常量反向迭代器 | 容器类名::const_reverse_iterator 迭代器名; |
通过定义以上几种迭代器,就可以读取它指向的元素,*迭代器名就表示迭代器指向的元素。
其中,常量迭代器和非常量迭代器的区别在于:
常量迭代器对指向的元素只能读取,不能修改。
非常量迭代器对指向的元素既能读取,也能修改。
而反向迭代器和正向迭代器的区别在于:
对正向迭代器进行 ++ 操作时,迭代器会指向容器中的后一个元素。
对反向迭代器进行 ++ 操作时,迭代器会指向容器中的前一个元素。
需要注意的是,以上 4 种定义迭代器的方式,并不是每个容器都适用。有一部分容器同时支持以上 4 种方式,比如 array、deque、vector等。而有些容器只支持其中部分的定义方式,例如 forward_list 容器只支持定义正向迭代器,不支持定义反向迭代器。
容器的种类
(内容摘自 - C语言中文网)



注意区分reserve和resize方法
reserve方法是尝试调整容器的容量大小,只有当请求的容量是大于当前容量时才会调整容量的大小,也就是说,reserve可以看作是一种扩容操作,不能减小容量。resize方法是修改容器的数据的大小,可以缩容也可以扩容。
对应的,size函数返回的是容量内数据的长度,而capacity函数返回的是容器的实际容量。可以把容器类比成一个被子,被子的总大小就是容量capacity,被子里的水就是数据的大小size。
string不同于其它容器
和其它容器不同,其它容器像vector等本身是一个类模板,而string是由basic_string类模板实例化出来具体的类型。

其实不仅仅只有string一种字符串类型,根据具体需求我们还可以选择u16string、u32string、wstring等不同的字符串类型。
值得注意的是,string类型的具体实现在不同的编译器上是不同的,有的是三个成员变量进行维护,有的则只是封装了一个指针,甚至还会有延时拷贝等实现。
部分容器的扩容机制
容器的扩容机制是一个重要的概念。在C++标准库中,容器的扩容是为了在插入新元素时保持高效性能的一种策略。以vector为例,这是一个动态数组容器。向vector插入元素时,如果容器的内部数组已满,就需要进行扩容。扩容的步骤通常涉及以下几个关键步骤:
分配新内存: 当容器的内部数组已满时,会分配一个更大的内存块。通常,新的内存大小会比所需内存更大,以便减少内存分配操作的频繁。
元素迁移: 旧内存中的元素会被复制到新的内存块中。这包括从旧内存到新内存的逐个元素复制,或者可以使用移动语义进行高效的迁移。
释放旧内存: 一旦元素迁移完成,旧的内存块会被释放,以防止内存泄漏。
不同的数据结构有不同的优势和限制,因此容器的设计者会根据实际需求来选择适合的数据结构以及对应的扩容策略。例如,动态数组容器使用重新分配内存的方式进行扩容,而哈希表容器则可能根据负载因子进行扩容。
但并不是所有的容器都是会进行扩容操作的。比如像链表这种链式结构就不需要进行扩容。容器是否会进行扩容与这个容器底层实现的数据结构有关。一般来说,顺序存储的数据,像string、vector、map、unordered_map等都是会在容器满了时进行扩容操作,而像list、forward_list等链式容器则不需要进行扩容操作,因为其底层实现并不是固定大小的,所以扩容操作也就没有意义。
迭代器失效问题
在使用C++容器中的迭代器来访问容器中的元素时,如果容器的内部结构发生了变化,就有可能会导致迭代器失效。迭代器失效是指这个迭代器不能再有效或安全地引用原来绑定元素,这可能会导致程序出现未定义的行为、崩溃或错误的结果。
简言之,迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果就是程序崩溃。如下是一些导致迭代器失效的常见操作:
- 改变容量大小:例如reserve操作(resize操作不是),容器的容量大小改变一般是申请一段新空间,将旧空间的数据拷贝到新空间,随之释放旧空间。在这个过程中,如果之前恰巧有一个迭代器是指向旧空间的,那么扩容或者shrink_to_fit 成功之后,此时这个旧的迭代器就会失效。如果此时再对这个旧的迭代器进行操作,就会造成一种很危险的未定义行为,VS中会直接报错,而g++中原来的数据会被修改为随机值。
- 插入操作:插入操作的解释和上面的扩容类似,因为插入操作可能会引起扩容操作,而扩容操作又会导致迭代器失效。但插入操作并不一定会导致迭代器失效。
- 删除操作:删除操作并不一定会导致迭代器失效。只有当删除操作使得原来的迭代器绑定数据的位置被删除才会出现迭代器失效,以vector容器为例,大多数情况下只有在删除最后一个元素的时候才会出现迭代器失效。
- 释放操作:当把对应的容器delete之后,这段空间被释放了,也会造成迭代器失效。
总结一下,当发生扩容或者释放等使得原来的内存空间不再使用的操作时,原来的迭代器就会失效,而如果删除了原来迭代器指向的那段空间的数据(也就是说,释放了迭代器所绑定的那段空间)也会造成迭代器失效。而访问失效的迭代器就和访问越界的数组元素一样,是一种很危险的未定义行为,会导致程序崩溃或是结果错误。
memcpy的拷贝问题
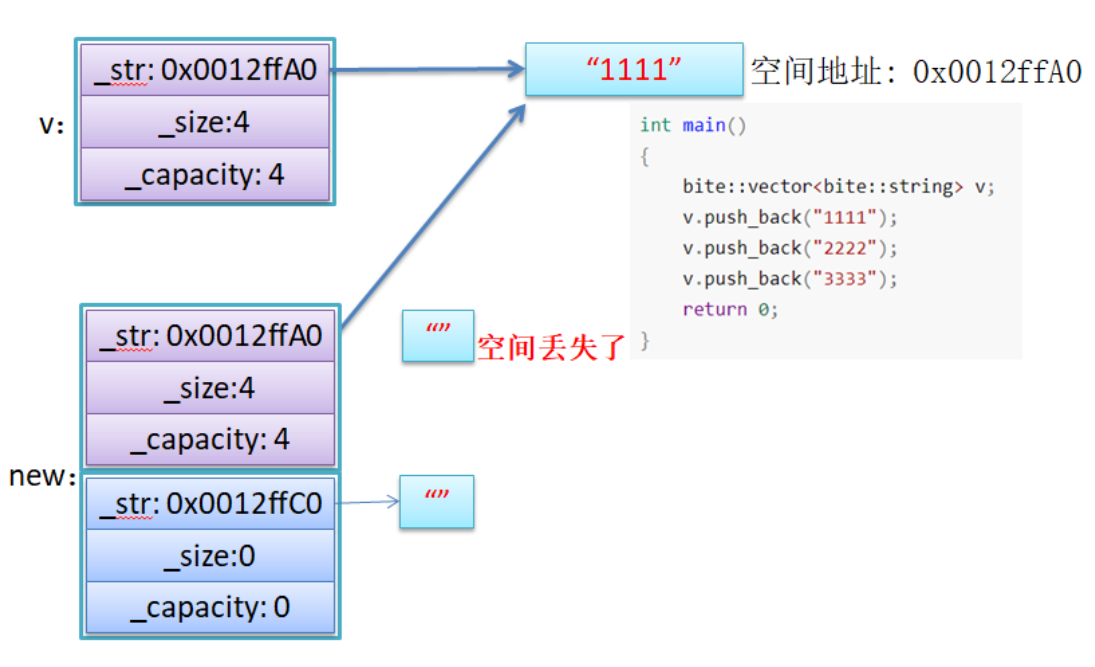
在模拟实现vector写reserve函数的时候,起初我是用memcpy拷贝的,而在memcpy之后又调用了对应的析构函数,但在使用vector<string>的时候并不能正常使用。后来发现,这是因为memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中,也就是说memcpy的拷贝其实就是一种浅拷贝。
而string可以看作是在堆区申请空间的,故string的析构一定有关于delete的相关操作。所以如果在用了memset之后又调用了析构函数,那么就会造成浅拷贝的通病——同一块内存空间析构两次。这是因为新空间是将原空间的srting浅拷贝过去,紧接着旧空间delete,而旧空间中的string成员也会delete,所以新空间的string就是那块已经delete的string。参考下图理解:
结论:只要涉及析构,就要考虑成员变量是自定义类型的情况。甚至可以说,如果对象中涉及到资源管理时,一定不能使用memcpy进行对象之间的拷贝,因为memcpy是浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。

