
热门标签
热门文章
- 1openvino:yolov3转换成tenserflow模型再转换成openvino模型,并用神经计算棒一代加速。后在树莓派3b+加上NCS平台上实现yolo3前传。_树莓派3b+可以做yolo算法吗
- 2Elasticsearch中脚本的使用_es中脚本应用
- 3spring-jar包详解整理(大合集)_spring核心jar包
- 4推荐开源项目:Chinese_Coreference_Resolution - 汉语核心指代消解
- 5【重磅】NLP实战之BERTopic主题模型分析(pycharm版)_通过c-tf-idf算法提取主题候选词。 stop_words: 设置停用词语言。
- 6Hadoop3.1.3之完全分布式模式环境搭建
- 7linux生成密码文本,Linux下用makepasswd和passwordmaker生成密码
- 8报错Cannot deserialize instance of `java.lang.Integer` out of START_OBJECT token
- 9python 文本聚类分析案例——从若干文本中聚类出一些主题词团_使用一个聚类模型实现一个主题发现任务python
- 10ekho 语音合成开源_ekho语音库
当前位置: article > 正文
【PyTorch】关于函数 datasets.IMDB.splits()_imdb(root="data", split="train")
作者:我家自动化 | 2024-04-02 18:44:39
赞
踩
imdb(root="data", split="train")
- I M D B \rm IMDB IMDB 是关于电影评论的数据集,其中有 50000 50000 50000 条情感倾向明显的评论信息,其中 25000 25000 25000 条作为训练集, 25000 25000 25000 条作为测试集。并且数据的总体分布是均衡的,即正面评价和负面评价各 25000 25000 25000 条。
- 下面的代码可以将 t o r c h t e x t . d a t a s e t s \rm torchtext.datasets torchtext.datasets 中的 I M D B \rm IMDB IMDB 数据集分割成文本 T E X T \rm TEXT TEXT 和标签 L A B E L \rm LABEL LABEL 两部分。
train,test = datasets.IMDB.splits(TEXT,LABEL)
- 1
- s p l i t s ( ) \rm splits() splits() 方法的定义如下:
@classmethod def splits(cls, text_field, label_field, root='.data', train='train', test='test', **kwargs): """Create dataset objects for splits of the IMDB dataset. Arguments: text_field: The field that will be used for the sentence. label_field: The field that will be used for label data. root: Root dataset storage directory. Default is '.data'. train: The directory that contains the training examples test: The directory that contains the test examples Remaining keyword arguments: Passed to the splits method of Dataset. """ return super(IMDB, cls).splits( root=root, text_field=text_field, label_field=label_field, train=train, validation=None, test=test, **kwargs)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 对比定义和调用方式,可以看出
T
E
X
T
,
L
A
B
E
L
\rm TEXT,LABEL
TEXT,LABEL 是两个
F
i
e
l
d
\rm Field
Field 类型的对象。下载到本地的
I
M
D
B
\rm IMDB
IMDB 数据集组织如下所示:
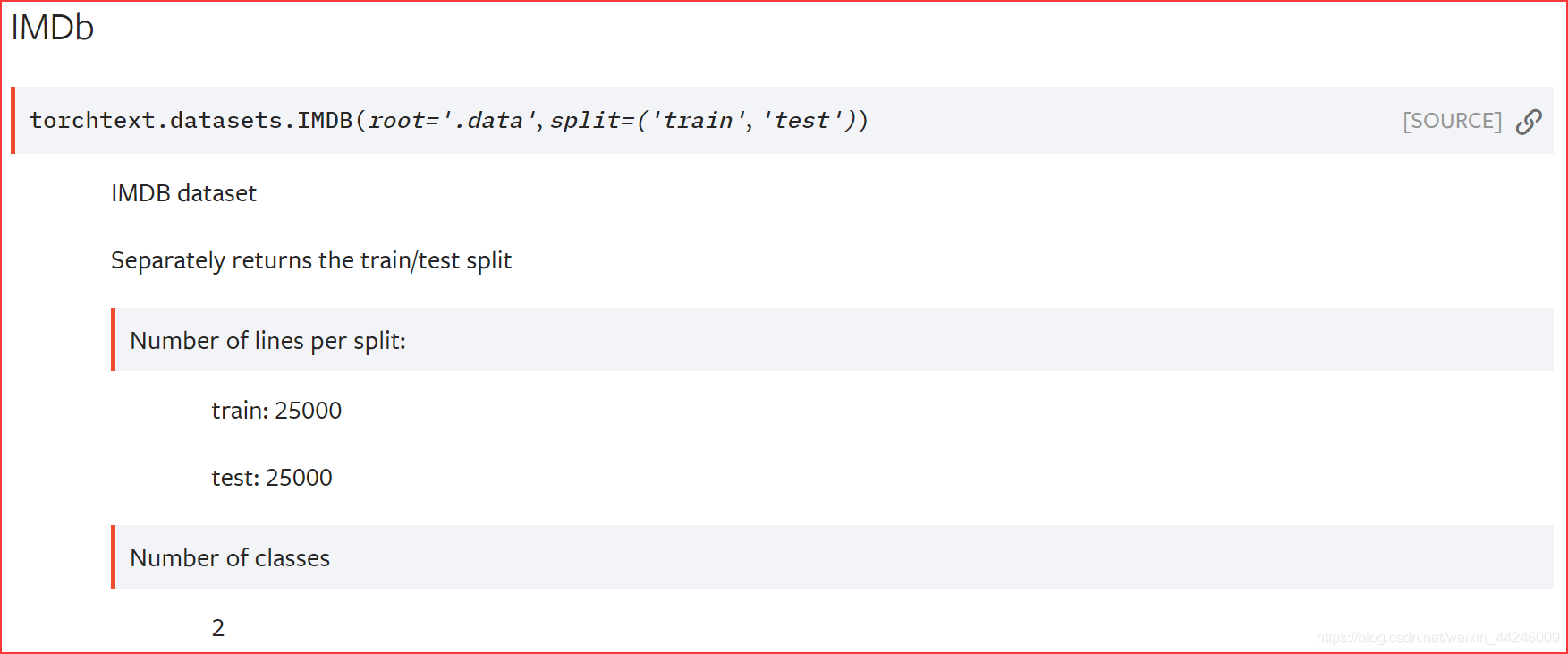
- 下图是
P
y
T
o
r
c
h
\rm PyTorch
PyTorch 官网给出的
I
M
D
B
\rm IMDB
IMDB 信息:
- 在
G
i
t
H
u
b
\rm GitHub
GitHub 上有这样一个问题:
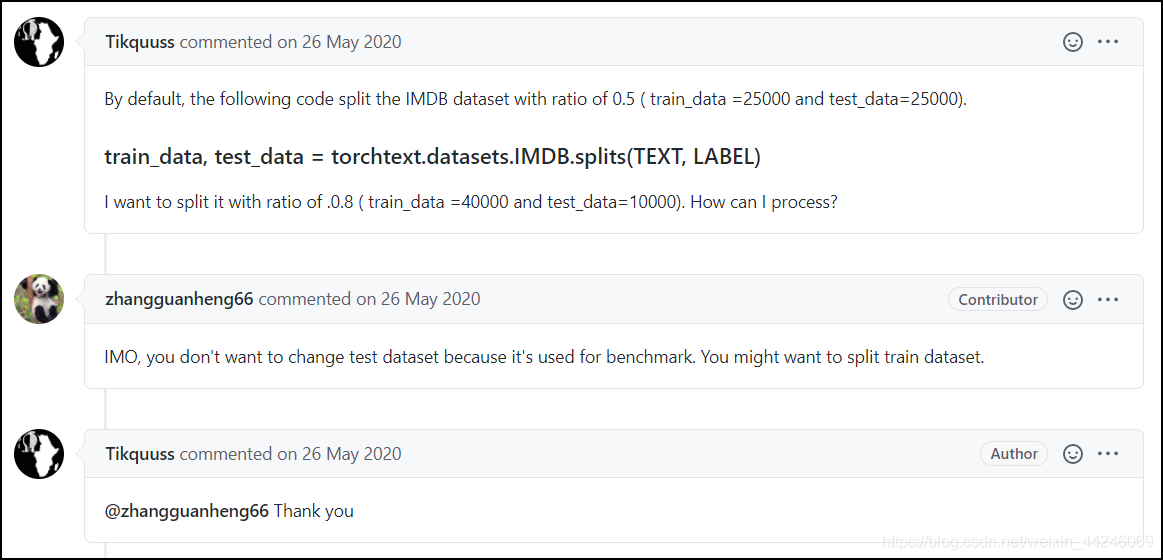
- 我们希望训练集与测试集不是对半分的,而是以某个比值 r r r,例如这里的 0.8. 0.8. 0.8. 需要明确,通过 d a t a s e t s . I M D B \rm datasets.IMDB datasets.IMDB 这种方式获取到的数据集,是服务器上组织后的数据集,其 t r a i n , t e s t \rm train,test train,test 均已确定,即官网给出的 25000 v s 25000 \rm 25000~vs~25000 25000 vs 25000,如果需要改变这个划分方式,需要在本地对数据集进行修改并读取。
- 在下载后的 I M D B \rm IMDB IMDB 压缩文件中,发现 t r a i n / u n s u p \rm train/unsup train/unsup 文件夹,官方数据集对其描述如下:
We also include an additional 50,000 unlabeled documents for unsupervised learning.
- 1
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/353344?site
推荐阅读
相关标签

