
热门标签
热门文章
- 1嗨,Chrome和火狐,有第三者插足!_ortc开源吗
- 2ACL2022 | 关系抽取和NER等论文分类整理_few-shot class-incremental learning for named enti
- 3陪诊小程序成品|陪诊系统功能|陪诊小程序研发功能和流程
- 4Android Studio中配置aliyun maven库_android studio maven配置
- 5把本地文件 formfile 拷贝到本地文件 tofile 的程序
- 6Pytorch(二) —— 激活函数、损失函数及其梯度_pytorch 激活函数的梯度
- 7Tensorflow训练mnist数据集损失函数loss出现Nan_minist 训练结果lost 大
- 8Android SDK下载安装及配置教程_andorid sdk
- 9【鸿蒙开发】第十七章 Web组件(一)_鸿蒙 web组件 nweb
- 1012 个在线代码编辑器,有哪个比 GitHub Codespaces 更香?_在线写代码
当前位置: article > 正文
Pytorch卷积神经网络Mnist手写数字识别-GPU训练_train_dataset = datasets.mnist(root='./data', trai
作者:IT小白 | 2024-03-30 06:17:46
赞
踩
train_dataset = datasets.mnist(root='./data', train=true, transform=transfor
导入工具包
- import torch
- import torch.nn as nn
- import torch.optim as optim
- import torch.nn.functional as F
- from torchvision import datasets,transforms
- import matplotlib.pyplot as plt
- import numpy as np
- %matplotlib inline
定义超参数
- # 定义超参数
- input_size = 28 #图像的总尺寸28*28
- classes = 10 #标签的种类数
- epochs = 10 #训练的总循环周期
- batch_size = 64 #一个撮(批次)的大小,64张图片
- learning_rate=0.001
通过torchvision的dataset导入Mnist数据集
- # 训练集
- train_dataset = datasets.MNIST(root='./data',
- train=True,
- transform=transforms.ToTensor(),
- download=True)
-
- # 测试集
- test_dataset = datasets.MNIST(root='./data',
- train=False,
- transform=transforms.ToTensor())
通过DataLoader实现构建batch数据,进一步简化了代码。(这样就不用写关于设置batch的循环了)
- # 构建batch数据
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=batch_size,
- shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=True)
构建CNN网络,卷积层-池化层-卷积层-池化层-全连接层
- class CNN(nn.Module):
- def __init__(self):
- super(CNN,self).__init__() #输入大小为(1,28,28)
- self.conv1=nn.Sequential(
- nn.Conv2d(
- in_channels=1, #灰度图,通道只有一个特征图
- out_channels=16, #输出16个特征图
- kernel_size=5, #卷积核大小为5*5
- stride=1, #步长为1
- padding=2, #填充2圈变为32*32
- ) , #输出为16*28*28
- nn.ReLU(), #ReLU层
- nn.MaxPool2d(kernel_size=2), #进行池化操作,2*2
- ) #输出为16*14*14
- self.conv2=nn.Sequential(
- nn.Conv2d(
- in_channels=16, #输入16*14*14
- out_channels=32, #输出32*14*14
- kernel_size=5,
- stride=1,
- padding=2,
- ) ,
- nn.ReLU(), #ReLU层
- nn.MaxPool2d(kernel_size=2), #输出(32,7,7)
- )
- self.out=nn.Linear(32*7*7,10) #全连接层输出结果
-
- def forward(self,x):
- x=self.conv1(x)
- x=self.conv2(x)
- x=x.view(x.size(0),-1)
- output=self.out(x)
- return output

定义准确率计算函数
- def accuracy(predictions,labels):
- pred=torch.max(predictions.data,1)[1]
- rights=pred.eq(labels.data.view_as(pred)).sum()
- return rights,len(labels)
网络实例化,设置优化器,损失函数,设定gpu训练(将模型,数据导入gpu即可)
- #实例化
- net=CNN()
- #损失函数
- criterion=nn.CrossEntropyLoss()
- #优化器
- optimizer=optim.Adam(net.parameters(),lr=learning_rate)
-
- device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- net.to(device)
 训练模型并且打印输出
训练模型并且打印输出
- #开始训练循环
- for epoch in range(epochs):
- #保存当前epoch的结果
- train_rights=[]
-
- for batch_idx,(data,target) in enumerate(train_loader):
- data=data.to(device)
- target=target.to(device)
- net.train()
- output=net(data)
- loss=criterion(output,target)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- right=accuracy(output,target)
- train_rights.append(right)
-
- if batch_idx%100==0:
- net.eval()
- val_rights=[]
-
- for (data,target) in test_loader:
- data=data.to(device)
- target=target.to(device)
- output=net(data)
- right=accuracy(output,target)
- val_rights.append(right)
-
- #准确率计算
- train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
- val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
-
- print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(
- epoch+1, batch_idx * batch_size, len(train_loader.dataset),
- 100. * batch_idx / len(train_loader),
- loss.data,
- 100. * train_r[0].numpy() / train_r[1],
- 100. * val_r[0].numpy() / val_r[1]))
-

打印最后得到的训练模型总的准确率
- train_rights=[]
- val_rights=[]
- for (data,target) in train_loader:
- data=data.to(device)
- target=target.to(device)
- train_output=net(data)
- right=accuracy(train_output,target)
- train_rights.append(right)
- for (data,target) in test_loader:
- data=data.to(device)
- target=target.to(device)
- test_output=net(data)
- right=accuracy(test_output,target)
- val_rights.append(right)
- #总准确率计算
- train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
- val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
-
- print('训练集总准确率: {:.2f}%\t测试集总准确率: {:.2f}%'.format(
- 100. * train_r[0].numpy() / train_r[1],
- 100. * val_r[0].numpy() / val_r[1]))
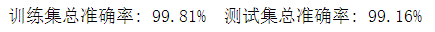
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/339415?site
推荐阅读
相关标签

