
- 1adb命令 查看运行APP当前页面的Activity名称_adb 查看当前activity name
- 2torchvision.datasets.ImageFolder
- 3简明Pytorch分布式训练 — DistributedDataParallel 实践
- 45.0、软件测试——边界值分析法_软件测试边界值法
- 5阿里云开源通义千问多模态大模型 Qwen-VL
- 6Java基于鸿蒙操作系统的新闻app设计(开题+源码)_鸿蒙java 写app
- 7Ubuntu20.04 阿里云服务器网站搭建 Apache2+PHP+MySQL_ubuntu 阿里源 php
- 8Vue路由传参params与query的区别和 vue 使用resolve打开浏览器新窗口跳转_router.resolve params
- 9第十四届蓝桥杯大赛软件赛省赛(C/C++ 研究生组)_研究生组蓝桥杯
- 10如何使用 RabbitMQ 进行消息的发送和接收
从0开始大模型学习—— GPT2: Zero Shot的崛起
赞
踩
昇思MindSpore希望能在开发者之间建立交流和分享的渠道,与开发者共成长,《从零开始大模型学习》专栏正是这这个期望的载体。
本系列文章是针对《昇思MindSpore技术公开课》的学习心得和体会,文章产出用于参加【第五届MindCon极客周】,《昇思MindSpore技术公开课》包含了两期大模型专题:从Transformer开始讲起,到目前流行的LLaMA模型,已经完结的第一期课程(第1讲-第10讲)中,从Transformer开始,解析到ChatGPT的演进路线,手把手带领大家搭建一个简易版的“ChatGPT”;正在进行的第二期课程(第11讲-)在第一期的基础上做了全方位的升级,围绕大模型从开发到应用的全流程实践展开,讲解更前沿的大模型知识、丰富更多元的讲师阵容。课程结合深度学习框架昇思MindSpore,课程由浅入深,对想要学习机器学习特别是大模型技术的同学比较友好。系列文章选择了我个人比较感兴趣的几节课作为分享,记录内容是以我个人的认知为基础做增量记录,内容可能不全面,推荐大家去看原课,下面是一些文章相关的链接。
第五届MindCon极客周:https://xihe.mindspore.cn/events/mindcon
第二期课程报名:
https://xihe.mindspore.cn/course/foundation-model-v2/introduction
昇思MindSpore技术公开课B站合集:https://space.bilibili.com/526894060/channel/seriesdetail?sid=3293489
课程资料仓库:
github.com/mindspore-courses/step_into_llm
1. 学习总结
GPT2 论文的核心技术
-
Task Conditioning
仅Decoder结构构造训练集的时候,GPT是会做拼接,GPT2也同样是做拼接,但是在拼接的两段中间会加入一个Task拼接符。
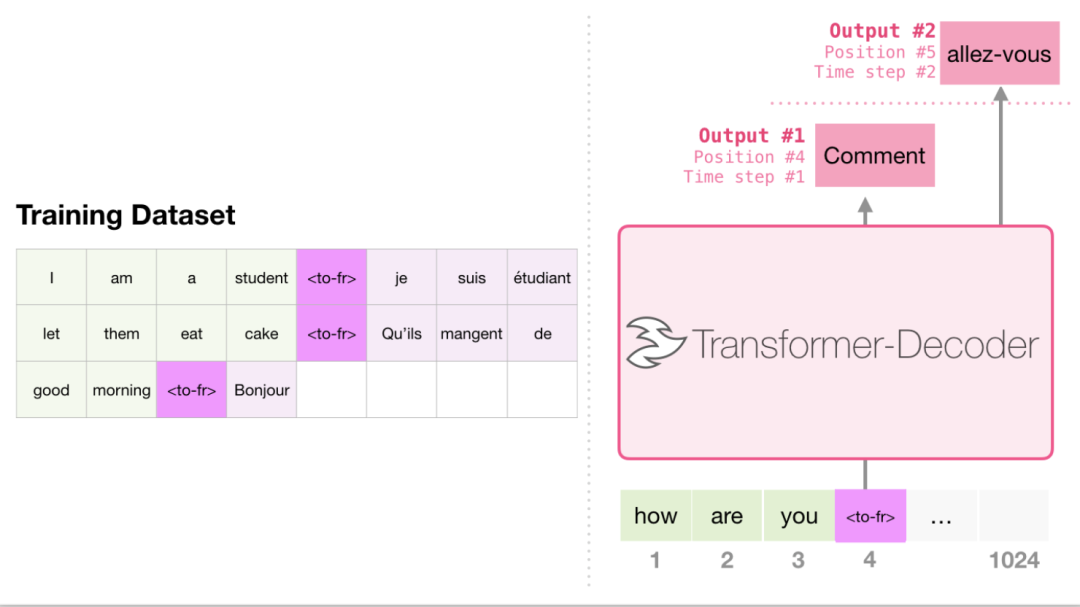
Task Conditioning concat
-
Zero Shot Learning and Zero Shot Task Transfer
我理解就是现在已经非常常用的所谓的prompt,但是在GPT2实现的时候是需要给定一个特定格式的prompt来激发,而现在的大语言模型通常都是直接用自然语言描述prompt就够了。
GPT2 全链接层模块的实现
前面的常规Self-Attention代码省略了,GPT2训练的时候当前的词是不能够看到后面的词的,这才符合inference的时候生成式的方案。

- max_positions = seq_len
-
- bias = Tensor(np.tril(np.ones((max_positions, max_positions))).reshape(
- (1, 1, max_positions, max_positions)), mindspore.bool_)
- bias
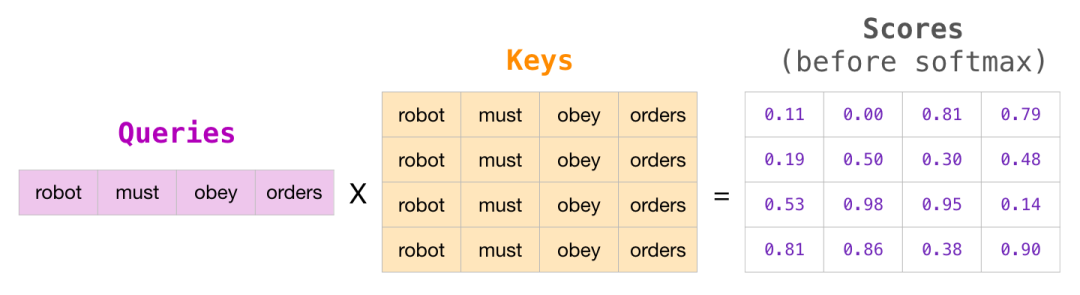
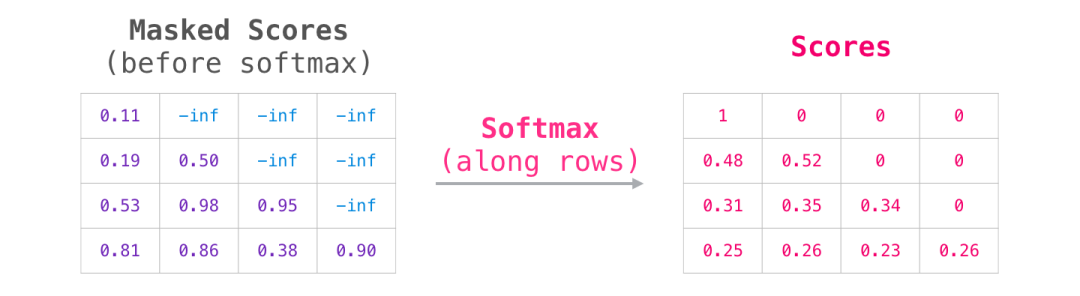
做完softmax之后,上三角的位置会全部变成 0。
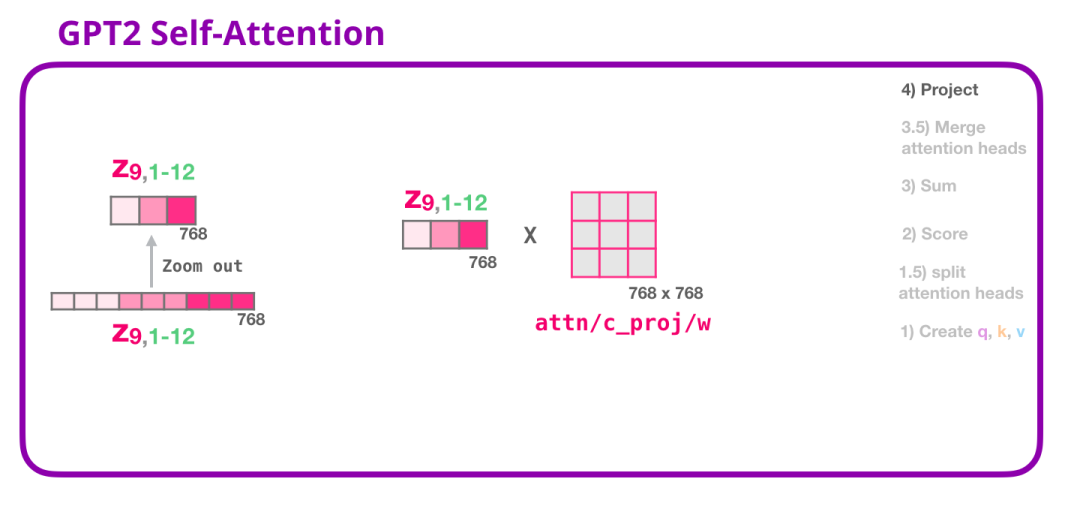
self-attention之后还要加一层project层全连接层( mindnlp.models.utils.utils.Conv1D ),就是对得到的矩阵再进行一次变换,融合一下多头的信息,增强表达能力。
数据预处理
数据预处理要考虑的最关键的问题是怎么对数据做padding,在max_seq_len一定的情况下要考虑对过长的训练样本做截断,对不够长的做padding,最终对齐所有的样本。截断的方案有很多,不同的截断方案训练出来的效果可能有差异,要更好地权衡需要保留的信息,例如本课程里做的是一个summarize的任务,所以采取的方案是保留所有的summary数据,而去截断原文的数据。
- def merge_and_pad(article, summary):
- article_len = len(article)
- summary_len = len(summary)
-
- sep_id = np.array([tokenizer.sep_token_id])
- pad_id = np.array([tokenizer.pad_token_id])
- if article_len + summary_len > max_seq_len:
- new_article_len = max_seq_len - summary_len
- merged = np.concatenate([article[:new_article_len], sep_id, summary[1:]])
- elif article_len + summary_len - 1 < max_seq_len:
- pad_len = max_seq_len - article_len - summary_len + 1
- pad_text = np.array([tokenizer.pad_token_id] * pad_len)
- merged = np.concatenate([article, summary[1:], pad_text])
- else:
- merged = np.concatenate([article, summary[1:]])
-
- return merged.astype(np.int32

2. 学习心得
GPT2作为一个比较老的模型,近期肯定没有多少人会去训了,大家现在关注的重点都在LLaMA、GLM这些比较新的模型,但是回顾一下比较老的工作,可以重新巩固一下基础,并且思考一下当初为什么要使用这些技术,以及为什么会将某些表现不好的技术坚持下去最后被验证是一个好的方案。
3. 经验分享
-
在做mask的时候,如果采用 attn_weights = where(causal_mask, attn_weights, mask_value) 这样的select操作,在昇腾硬件上是没有用加法快的,所以可以直接给要mask的位置加上一个极小值,对训练时候的值域不会产生影响 attn_weights = attn_weights + adder。
-
如果直接用pretrained GPT2来fine tune效果可能会很差,并且GPT2自带的tokenizer也没有做到中文的分词,所以可以使用预训练的bert-base-chinese 来做分词。
- from mindnlp.transforms import BertTokenizer
- tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
-
from mindnlp.models import GPT2Config, GPT2LMHeadModel,这个 GPT2LMHeadModel就是专门来做预训练的模型,还有一些例如 GPT2Classification可能是用来做分类的下游任务的。
-
用混合精度的时候一定要关注训练过程中是否会发生溢出的问题,可以在利用 mindspore.amp.DynamiclossScaler来实现给loss乘一个大数,这个时候梯度也会乘上这个大数,这样在需要表示特别小的值的时候也能在例如float16上表示出来了,当我们要使用梯度的值的时候需要把这个值处回去。更严谨的是在混合精度训练的时候做溢出检测,昇思MindSpore在昇腾软硬件支持方便的溢出检测。
- from mindspore.amp import init_status, all_finite, DynamicLossScaler
- @ms_function
- def train_step(data, label):
- # 初始化溢出检测位
- status = init_status()
- data = ops.depend(data, status)
- loss, grads = grad_fn(data, label)
- loss = loss_scaler.unscale(loss)
- # 探测溢出检测位是否被置位
- is_finite = all_finite(grads, status)
- # 如果溢出了就直接跳过这个step
- if is_finite:
- grads = loss_scaler.unscale(grads)
- loss = ops.depend(loss, accumulator(grads))
- loss = ops.depend(loss, loss_scaler.adjust(is_finite))
- return loss, is_finite
显存不够大的时候可以使用梯度累加技术,昇思MindSpore也支持了。
- from mindnlp.modules import Accumulator
- accumulator = Accumulator(optimizer, accumulate_step, max_grad_norm)
4. 反馈
-
讲课的老师很专业,内容涵盖的很广,也能积极的互动,最好的是能提供一些工业的视野和一些前沿的情况,这些是同学们在学校不太好接触到的。
-
昇思MindSpore的dataset这个map的接口很赞。
-
MindNLP对标了HuggingFace,可以更方便地使用fine-tune预训练模型了
5. 未来展望
感觉课程理论部分和代码部分有一点割裂,可以尝试把GPT2的一些新用的技术实现到代码里,使用稍简单点的方式也可以,比如理论讲到的GPT2的两个关键技术,是怎么把prompt的信息融入到训练中的,感觉现在的代码内容没有特别体现出来GPT2的特性,当然也有可能这节课的代码重点是怎么对模型做预训练。

