
- 1ViLBERT:视觉语言多模态预训练模型_视觉-语言多模态训练模型
- 2深度之眼Paper带读笔记NLP.11:FASTTEXT.Baseline.06_in this work, we explore ways to scale thesebaseli
- 3matlab accumarray_32个实用matlab编程技巧
- 4【科研新手指南2】「NLP+网安」相关顶级会议&期刊 投稿注意事项+会议等级+DDL+提交格式_ccs投稿须知文件
- 5spring-boog-测试打桩-Mockito_org.mockito.exceptions.base.mockitoexception: chec
- 6Git将当前分支暂存切换到其他分支_如何暂存修改切换分支git
- 7solidity实现智能合约教程(3)-空投合约
- 8上位机图像处理和嵌入式模块部署(qmacvisual寻找圆和寻找直线)
- 930天拿下Rust之错误处理
- 10基于springboot的在线招聘平台设计与实现 毕业设计开题报告_招聘app的设计与实现的选题背景怎么写
Attention注意力机制综述(二)--多头自注意力机制(含代码)Multi-head Self-Attention Machanism_多头注意力机制图
赞
踩
3. 多头自注意力机制(Multi-head Self-Attention Machanism)
多头注意力机制是在自注意力机制的基础上发展起来的,是自注意力机制的变体,旨在增强模型的表达能力和泛化能力。它通过使用多个独立的注意力头,分别计算注意力权重,并将它们的结果进行拼接或加权求和,从而获得更丰富的表示。
在自注意力机制中,每个单词或者字都仅仅只有一个 q、k、v与其对应,如下图所示;
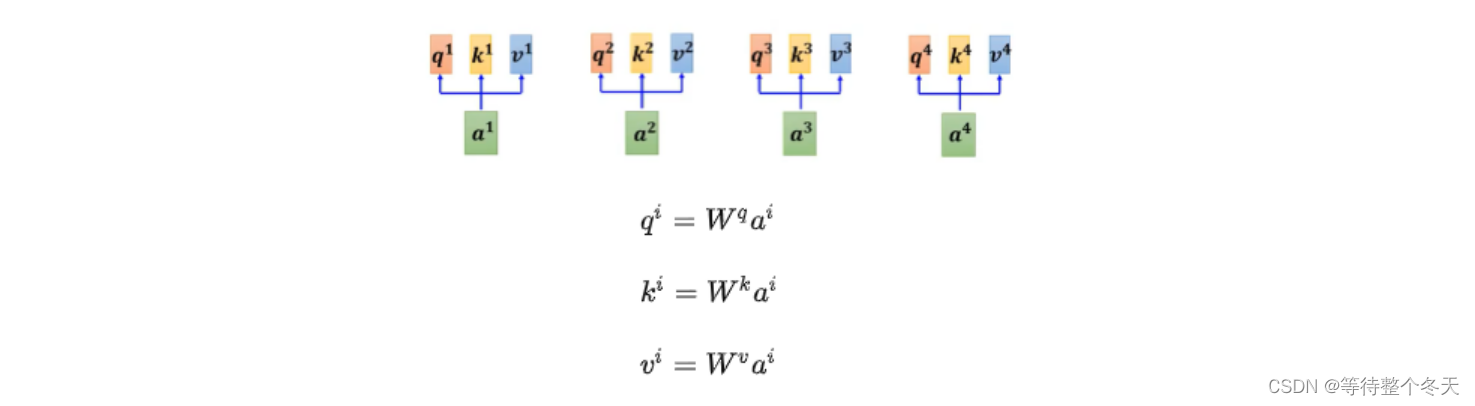
为什么需要多个head?
在做self-attention的时候是用q去找相关的k,但是相关有很多不同形式和定义,不同q负责不同种类的相关性。
多头注意力机制则是在 ai 乘以一个q,k,v后,会再分配多个 q,k,v,这里以2个 q,k,v 为例,如下图所示:
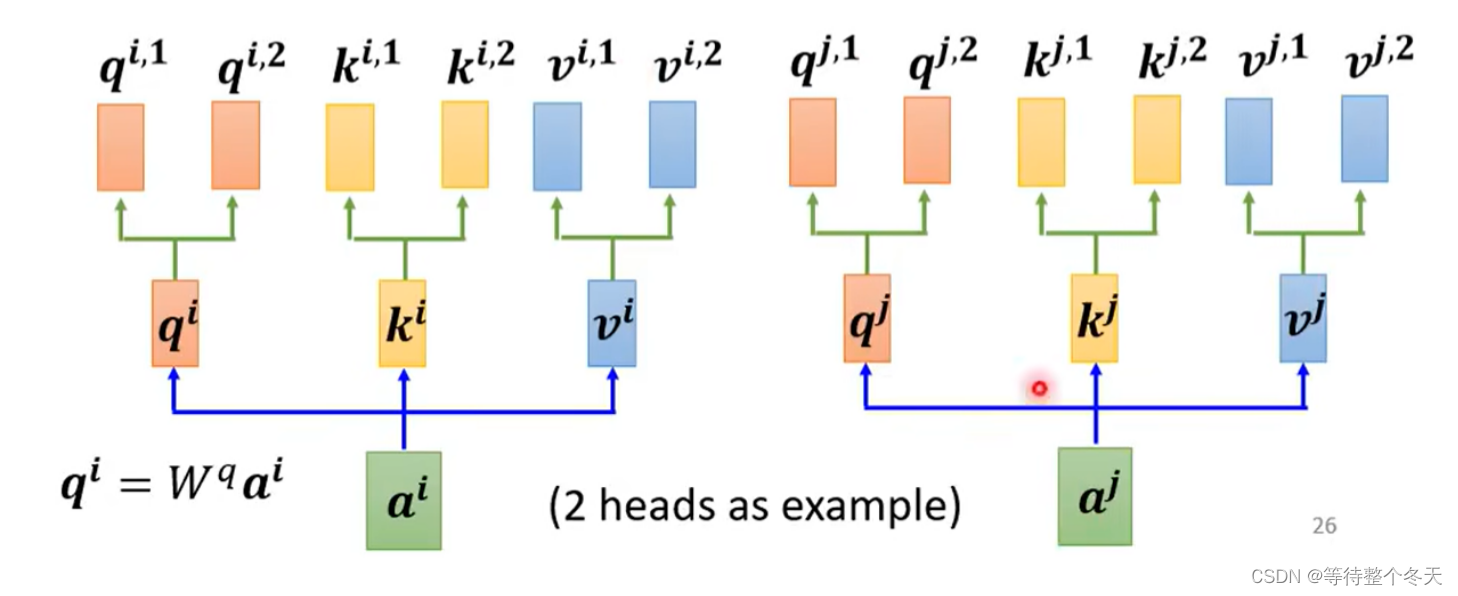
3.1q、k操作
在多头注意力机制中, ai 会先乘 q矩阵,*qi=Wqai ;
其次,会为其多分配两个head,以 q为例,包括: qi,1,qi,2 ;
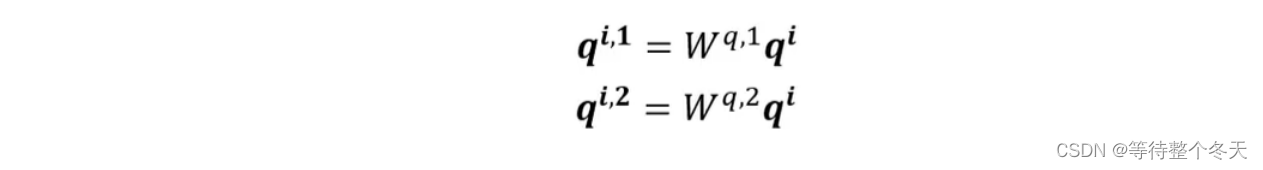
同样地,k和 v 也是一样的操作。
那么,下面就是 q和 k 的点乘操作了,在多头注意力机制中,有多个q 和 k,究竟应该选择哪个进行操作呢?
其实很简单,就是看下标,如下图所示。 qi,1,会和 ki,1和kj,1>进行点乘,再进行softmax操作
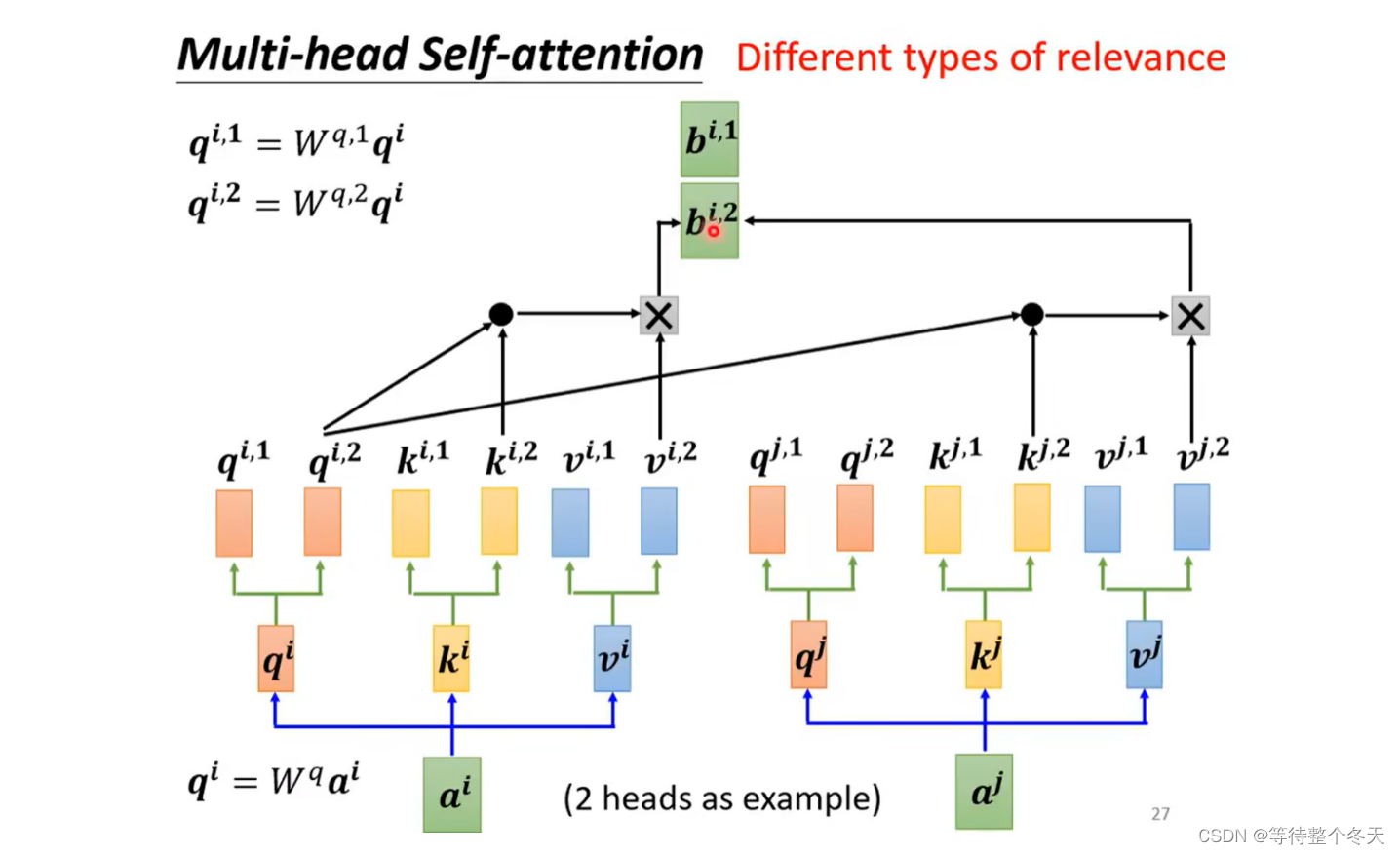
3.2v操作
将对应的attention分数乘对应的v, 比如head1的qi,1和 ki,1和kj,1进行点乘(dot_product)后,得到相应的注意力分数,归一化后分别和 vi,1和vj,1相乘,再求和得到注意力输出,head2也是同时这样进行的,得到bi,1和bi,2.
3.3注意力输出
将head1和head2得到的输出拼接起来,进行transpose就得到了注意力输出bi

3.4single-head与multi-head对比
single-head-attention中,从每个a中提取出q、k、v,他们的维度为d-model(每个token的维度)

multi-head-attention,与singlehead一样,先得出q、k、v,不同的是,每个q、k、v还要分出多个head

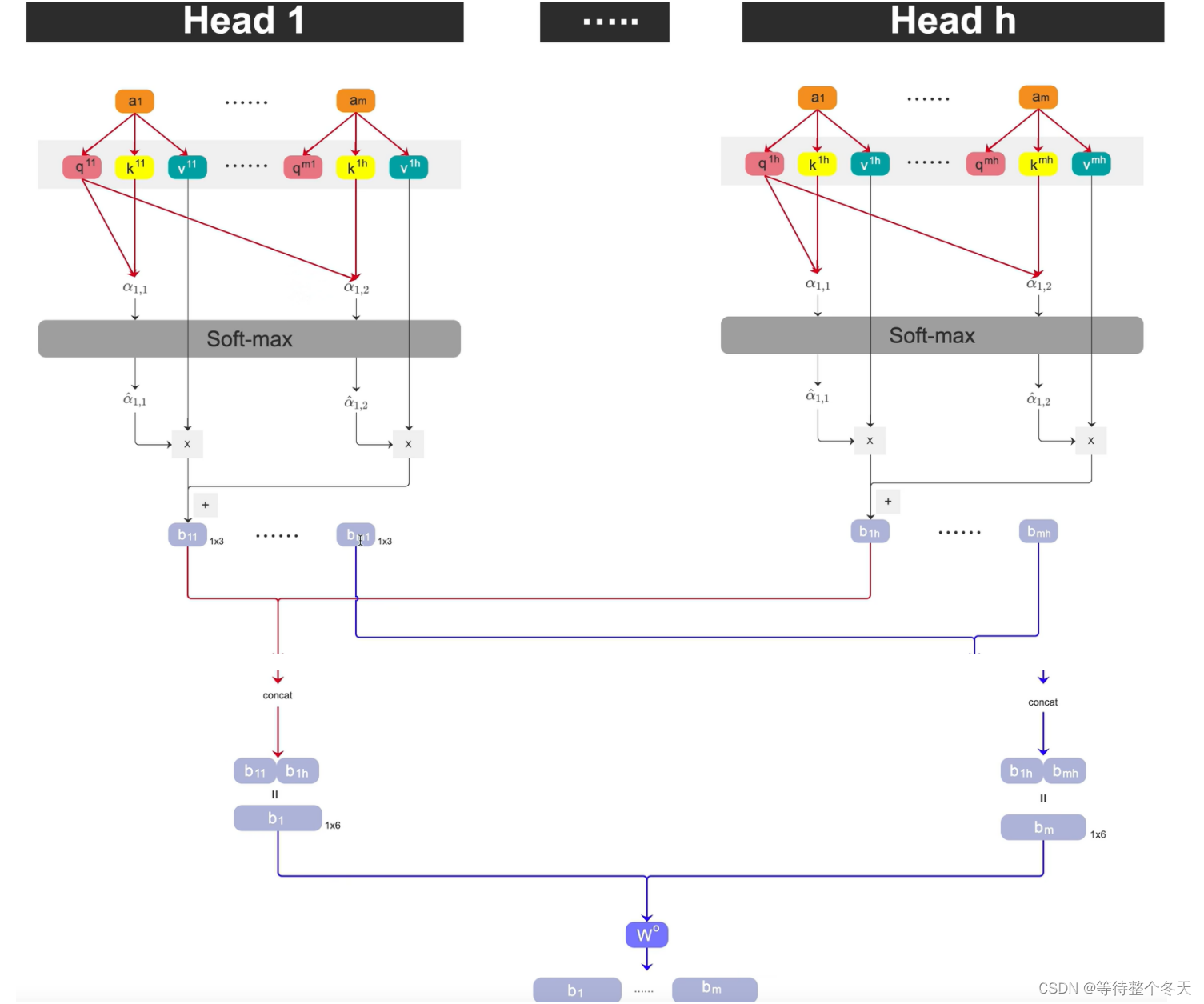
将多头得到的bii先按照列再按行con-cat,可以得到m x d_model的矩阵,m为token个数,d_model为每个token的维度
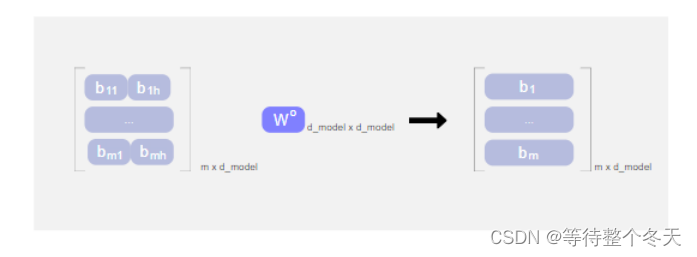
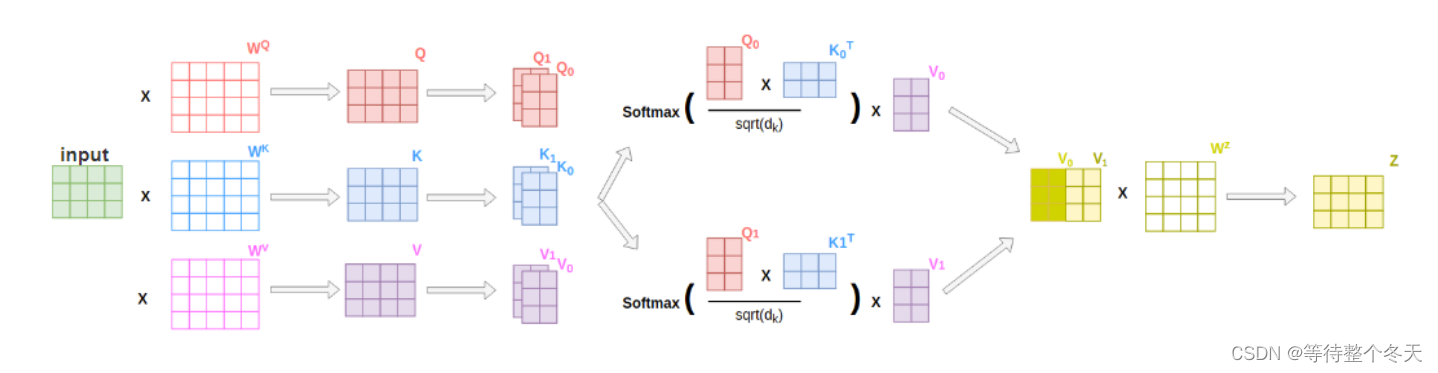
3.5流程总结
3.6代码实现
import torch from torch import nn as nn #dim_in:输入中每个token的维度,也就是输入x的最后一个维度 #d_model:single-head-attention情况下q、k、v总的向量长度 #num_heads:head个数 class MultiHead_SelfAttention(nn.Module): def __init__(self,input_dim,num_heads): super().__init__() self.num_heads=num_heads self.head_dim=input_dim//num_heads#head的维度为输入维度除以head个数,方便后面拼接 assert input_dim%num_heads==0 ,"Input dimension must be divisible by the number of heads." # Linear layers for the query, key, and value projections for each head self.query=nn.Linear(input_dim,input_dim) self.key=nn.Linear(input_dim,input_dim) self.value=nn.Linear(input_dim,input_dim) self.output_linear=nn.Linear(input_dim,input_dim) def forward(self,x): batch_size,seq_len,input_dim=x.size() #输入数据shape=[batch_size,token个数,token长度] #将输出向量经过矩阵乘法后拆分为多头 query=self.query(x).view(batch_size,seq_len,self.num_heads,self.head_dim) #输入数据shape=[batch_size,token个数,head数,head维度] key=self.query(x).view(batch_size, seq_len, self.num_heads, self.head_dim) value=self.query(x).view(batch_size, seq_len, self.num_heads, self.head_dim) #对调序列的长度和head个数(batch_size, seq_len, num_heads, head_dim) to (batch_size, num_heads, seq_len, head_dim) #方便后续矩阵乘法和不同头部的注意力计算 query=query.transpose(1,2)#(batch_size, num_heads, seq_len, head_dim) key=key.transpose(1,2) value=value.transpose(1,2) #计算注意力分数和权重matmul:最后两个维度做矩阵乘法 attention_scores=torch.matmul(query,key.transpose(-2,-1))/torch.sqrt(torch.tensor(self.head_dim,dtype=torch.float)) #query:(batch_size, num_heads, seq_len, head_dim) * key(batch_size,num_heads,head_dim,seq_len) #attention_scores:(batch_size, num_heads, seq_len, seq_len) attention_weights=torch.softmax(attention_scores,dim=-1) #注意力加权求和 attention=torch.matmul(attention_weights,value) # attention_scores:(batch_size, num_heads, seq_len, seq_len)* value(batch_size, num_heads, seq_len, head_dim) #attention:(batch_size, num_heads, seq_len, head_dim) #连接和线性变换 attention=attention.transpose(1,2).contiguous().view(batch_size,seq_len,input_dim)#contiguos深拷贝,不改变原数据 #(batch_size,num_heads, seq_len , head_dim) to (batch_size, seq_len, num_heads, head_dim) to (batch_size,seq_len,input_dim) output=self.output_linear(attention) return output #定义多头自注意力机制模型 class MultiHead_SelfAttention_Classifier(nn.Module): def __init__(self,input_dim,num_heads,hidden_dim,num_classes): super().__init__() self.attention=MultiHead_SelfAttention(input_dim,num_heads) self.fc1=nn.Linear(input_dim,hidden_dim) self.fc2=nn.Linear(hidden_dim,num_classes) self.relu=nn.ReLU() def forward(self,x): x=self.attention(x) x=x.mean(dim=1)#(batch_size, seq_len, input_dim) to (batch_size, input_dim) x=self.fc1(x) x=self.relu(x) x=self.fc2(x) return x if __name__=='__main__': model=MultiHead_SelfAttention_Classifier(input_dim=4,num_heads=2,hidden_dim=32,num_classes=2) x=torch.randn((2,4,4))#batch,4个token,每个token长度=input_dim output=model(x) print(output)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
输出
tensor([[-0.0598, -0.0333],
[-0.2237, -0.0573]], grad_fn=<AddmmBackward0>)
- 1
- 2

