
- 1运算放大器的理解与应用_电压控制电路的运放作用csdn
- 2基于先验驱动深度神经网络的图像复原去噪_神经网络恢复图像算法
- 3Android 中的广播机制_android 广播
- 4Docker入门学习教程_c# docker
- 5深度学习图解 - 具备高中数学知识就能从入门到精通的神书 Andrew W· Trask
- 6使用move_base规划路径后,小车接近目的地后原地打转的原因分析_movebase导航原地打转
- 7pytorch自定义loss损失函数
- 8JavaScript面试题看这一篇就够了,简单全面一发入魂(持续更新 step2)_javascript 面试题
- 9ArkTS基础学习笔记_arkts文档
- 10手把手教你DouZero项目的环境配置及运行,使用注意事项(否则会退出)
kylin调优,项目中错误总结,知识点总结,kylin jdbc driver + 数据库连接池druid + Mybatis项目中的整合,shell脚本执行kylin restapi 案例_unknown column 'discription' in 'field list
赞
踩
关于本篇文章的说明:
本篇文章为笔者辛苦劳作用了一整天总结出来的文档,大家阅读转发的时候请不要吝啬写上笔者:涂作权 和 原文地址。
由于笔者所在环境没有人用过kylin,笔者也是自学官网,阅读书籍 将kylin用于实际项目,期间遇到了很多很多关于kylin使用的问题。为了让后面的人在使用kylin实践的时候能够少走弯路,在此生成kylin的调优,错误总结,知识点文档,这篇文档应该是目前网上最全的kylin调优和总结文档了(除了官网)。
以下文章内容主要来自官网,书籍,博文,网友,社区,同学,以及实际项目。
1 调优方案
1.1 调优:如何提高访问连接并发(运维层面)
根据书籍中的介绍,kylin单个的实例,支持的访问连接并发是70个左右,所以,为了让kylin能够支持更多的访问并发,可以通过增加实例的方式实现。将单实例的Kylin变成集群方式,增加query节点的个数。
官网介绍的方式:
http://kylin.apache.org/docs/install/kylin_cluster.html
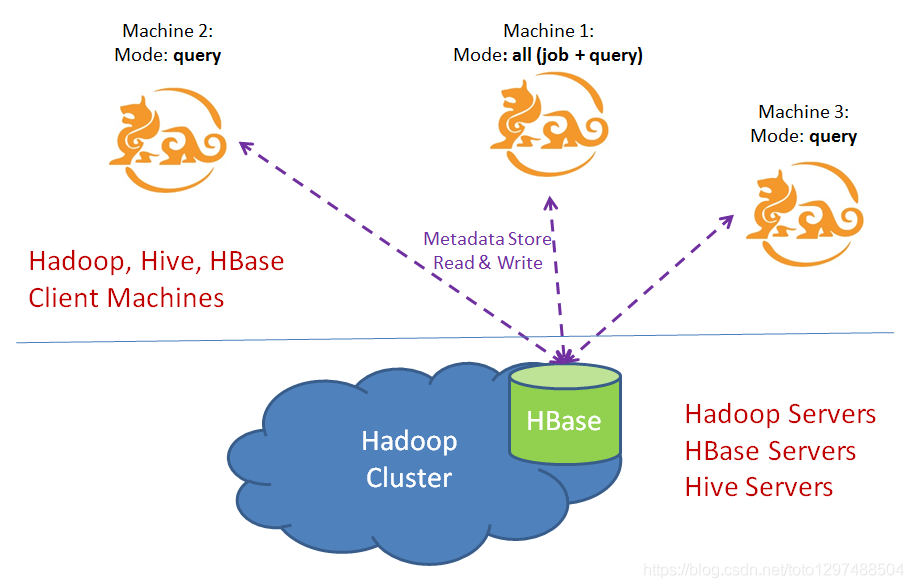
说明:
A:假设有3台机器,分别是machine1,machine2,machine3。其中Machine的运行模式是all(即拥有 执行job+执行query的角色 (个人理解)),另外的machine2和machine3为query(主要用于查询)。
B:注意,kylin2.0以后,kylin支持了多个job的方式,具体方式可以参考文档进行相关配置。
1.2 调优:解决kylin预处理过程gc问题(运维层面)
Kylin是基于预处理技术,如果公司资金雄厚,服务器配置高,内存大,那就不要吝啬内存了。给kylin足够的内存分配,能够减少很多问题。
如果处理的好,可以结合任务调度系统,比如azkaban,通过shell的方式将kylin的内存在数据处理空闲的时候,将内存多分配给kylin。
关于此部分的介绍,官网给出的建议是:
http://kylin.apache.org/docs/install/configuration.html
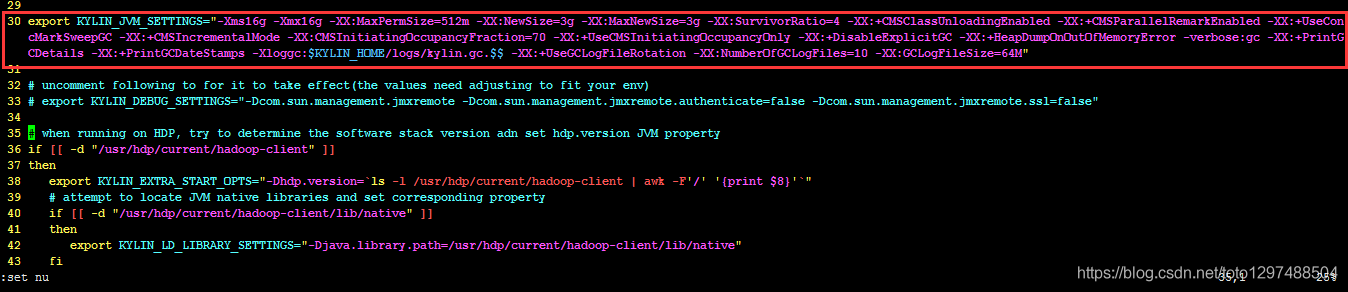
Allocate More Memory for Kylin
There are two sample settings for KYLIN_JVM_SETTINGS are given in $KYLIN_HOME/conf/setenv.sh.
The default setting use relatively less memory. You can comment it and then uncomment the next line to allocate more memory for Kyligence Enterprise. The default configuration is:
export KYLIN_JVM_SETTINGS="-Xms1024M -Xmx4096M -Xss1024K -XX:MaxPermSize=512M -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:$KYLIN_HOME/logs/kylin.gc.$$ -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=64M"
# export KYLIN_JVM_SETTINGS="-Xms16g -Xmx16g -XX:MaxPermSize=512m -XX:NewSize=3g -XX:MaxNewSize=3g -XX:SurvivorRatio=4 -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:$KYLIN_HOME/logs/kylin.gc. $$ -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=64M"
- 1
- 2
- 3
- 4
- 5
- 6
笔者配置:
[xxx conf]# pwd
/data/installed/apache-kylin-2.3.1-bin/conf
[xxxx conf]# vim setenv.sh
- 1
- 2
- 3
1.3 调优+错误总结:配置build引擎支持Spark (运维层面)
在kylin中支持以Spark作为预处理的方式,在内存足够的情况下,建议配置build引擎。使用Spark,默认的build引擎使用的是mapreduce.
由于笔者使用的hadoop版本是3.0.1(原生),当前最高版本是:v2.5.2,发现使用Kylin的时候,会报jar冲突问题,因为我环境使用的是3.x的jar包,但是在kylin发行版本目前还使用的是基于hadoop2.x的Spark。所以失败了。
但是,若使用的是CDH,可以使用,apache-kylin-2.5.2-bin-cdh60.tar.gz for beta版本进行安装试用。
支持Spark的配置:http://kylin.apache.org/docs/tutorial/cube_spark.html,关于具体步骤,本文不进行详细叙述。
1.4 调优:kylin出现reduce阶段内存异常问题(hadoop运维层面)
在kylin执行cube build的过程中,可能会出现内存溢出的问题,这个问题其中一个原因是hadoop的虚拟参数配置不合理导致的。
这里在$HADOOP_HOME/etc/Hadoop/yarn-site.xml 中的配置类似如下:
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 任务每使用1MB物理内存,最多可使用虚拟内存,默认是2.1 --> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5</value> </property> <!-- 每个节点可用内存,单位MB --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <!--<value>16384</value>--> <value>20480</value> <discription>每个节点可用内存,单位MB</discription> </property> <!-- 单个任务可申请最少内存,默认1024MB --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <!-- 单个任务可申请最大内存,默认8192MB --> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <!--<value>16384</value>--> <value>20480</value> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
yarn.nodemanager.vmem-pmem-ratio :虚拟内存大小的一个系数,通过调整这个参数,可以增大虚拟内存的值,避免kylin在cube build的过程中出现失败。
此外,也要调整:$HADOOP_HOME/etc/Hadoop/mapred-site.xml中如下的值:
<property> <name>mapreduce.map.java.opts</name> <!--<value>-Xms3g -Xmx6g</value>--> <value>-Xms3g -Xmx10g</value> </property> <property> <!-- mapreduce.reduce.java.opts 这个值一般是mapreduce.map.java.opts的两倍 --> <name>mapreduce.reduce.java.opts</name> <!--<value>-Xms6g -Xmx12g</value>--> <value>-Xms6g -Xmx16g</value> </property> <!-- 每个Map任务的物理内存限制,这个值 * yarn.nodemanager.vmem-pmem-ratio 就是虚拟内存的大小--> <property> <name>mapreduce.map.memory.mb</name> <!--<value>6144</value>--> <value>10240</value> </property> <property> <name>mapreduce.reduce.input.buffer.percent</name> <value>0.5</value> </property> <!-- 每个Reduce任务的物理内存限制,一般还是机器内存的80% --> <property> <name>mapreduce.reduce.memory.mb</name> <!--<value>12288</value>--> <value>16384</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
其中官网的介绍是:
1.5 将cuboid数据转为HFile
这一步启动一个MR任务来讲cuboid文件(序列文件格式)转换为HBase的HFile格式。Kylin通过cube统计数据计算HBase的region数目,默认情况下每5GB数据对应一个region。Region越多,MR使用的reducer也会越多。如果你观察到reducer数目较小且性能较差,你可以将“conf/kylin.properties”里的以下参数设小一点,比如:
kylin.hbase.region.cut=2
kylin.hbase.hfile.size.gb=1
- 1
- 2
如果你不确定一个region应该是多大时,联系你的HBase管理员。
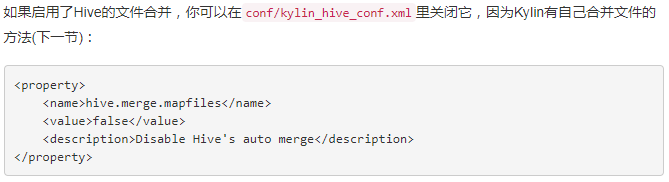
1.6 调优:解决kylin cube过程中的hive小文件问题(运维层面)
Kylin中自带文件合并,下面的过程可以考虑设置(这个笔者没有验证过,有的博文中建议下面方式进行设置,但是官网是另外一种说法)
官网:
一些博文上的写法:
[xxx conf]# pwd
/xxxx/apache-kylin-2.3.1-bin/conf
[xxxx conf]# vim kylin_hive_conf.xml
- 1
- 2
- 3
该文件原本的配置如下:
<property>
<name>hive.merge.mapfiles</name>
<value>false</value>
<description>Disable Hive's auto merge</description>
</property>
<property>
<name>hive.merge.mapredfiles</name>
<value>false</value>
<description>Disable Hive's auto merge</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
修改成:
<property>
<name>hive.merge.mapfiles</name>
<value>true</value>
<description>Enable Hive's auto merge</description>
</property>
<property>
<name>hive.merge.mapredfiles</name>
<value>true</value>
<description>Enable Hive's auto merge</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.7 调优:hive建表过程(数仓层面)
kylin使用的是一种预处理方式,这种方式有别于hive、spark-sql、presto、hbase、impala、druid等的即时查询方案,kylin能够在机器内存配置较少的情况下完成多维查询,对于有多维分析需求(OLAP)的项目,是一个很不错的选择。
但是,不要觉得kylin在调优过程中只要保证了kylin的model和cube创建的好就能够提升kylin的大大效率。对于kylin的数据来源hive中的hive表创建不好,会导致kylin cube build过程很漫长,这个笔者深有体会,优化的好的能够将build过程由1天多减少到分钟级别。
使用kylin进行多维查询,能够让不熟悉HBASE二级索引,预分区,HBASE调优,协处理等的开发人员减少很多时间。
在此,笔者建议kylin的hive数据表在创建的时候增加分区(partitioned),笔者的与分区格式类似如下:
drop table if exists tb_table;
CREATE TABLE IF NOT EXISTS tb_table
(
Xxxxxxx 此处建表语句略去,
addTime bigint comment '数据生成的时间,时间戳,秒值',
createDate bigint comment '创建天,时间格式为yyyyMMdd的integer值,由addTime通过from_unixtime(actionTime,'yyyyMMdd') as createDate 得出'
)
partitioned by(pt_createDate integer comment '创建天,时间格式为yyyyMMdd的integer值,分区时间')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
其中pt_createDate 是数据入库时间。这个值很重要,在建立Model的时候,一定要使用这个时间作为partition,而不要使用数据生成时间createDate,否则可能会出现hive中的数据在kylin增量预处理之后,kylin的数据条数小于hive的数据条数,导致分析结果偏少的问题。
1.8 调优:hive表数据类型导致kylin统计如sum出错的问题(数仓层面)
在hive进行sum的时候,有时候发现不管怎么设置,数据值总是1或者一些莫名其妙的值,导致这个现象的其中一个原因就是使用了hive中一个数据类型定义为tinyint的列作为度量列。所以,在使用hive建表的时候,可以将这种字段设置成integer,然后再进行处理,发现结果正确了。
类似:
is_active_member integer comment '是否是活跃会员,1:是,0不是', 由之前的tinyint改成integer
- 1
1.9 调优:group by 字段值,计算每个分组sum的查询速度调优(数仓层面)
kylin有一个坑,可能是设计问题,就是kylin对sum(case when 字段列 then 1 else 0 end) totalNum的支持很烂,它不支持。
为了处理这种场景,建议对所有以上场景或者类似group by然后计算sum结果的场景,都在数据处理结果,将这种结果1 or 0的状态计算好,存储在hive表中。类似笔者的一个Spark sql程序片段:
spark.sql("INSERT INTO TABLE tb_table partition(pt_createDate=" + pt_createDate + ") " +
"SELECT " +
" (case when st.registWay=10 then 1 else 0 end) as selfRegiste," +
" (case when st.registWay=20 then 1 else 0 end) as agentRegiste," +
" (case when st.registWay=30 then 1 else 0 end) as youxShopRegiste," +
" (case when st.registWay=40 then 1 else 0 end) as salesmanRegiste," +
" (case when st.registWay=50 then 1 else 0 end) as headShopRegiste," +
" from_unixtime(registTime,'yyyyMMdd') as createDate " +
"FROM " +
" tb_table_temp "
);
spark.stop();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
也就是说将registWay 的分组求总和统计变成 selfRegiste 、agentRegiste 、youxShopRegiste、salesmanRegiste、headShopRegiste 的sum求和。通过这种方式之后,发现项目查询速度有很大的提升,可能有原来的n秒级,变成毫秒级别。
1.10 调优:使用和hive相同的partition column
在创建model的时候,指定类似如下的分区列:
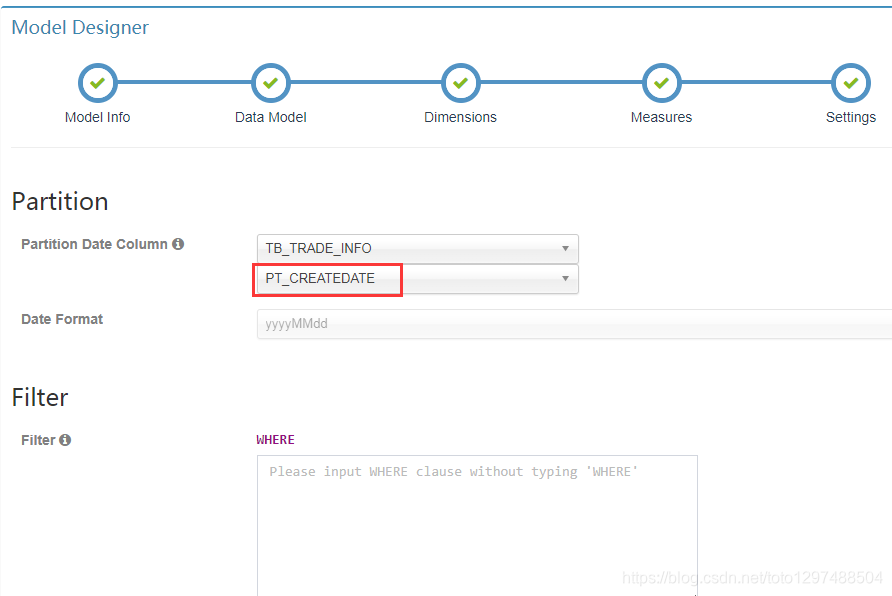
使用增量build cube的方式。
1.11 调优:定期清理Kylin cube build过程中产生的中间文件
在kylin 在cube build过程中会产生很多临时文件,现象是:在hdfs中的/hbase/data/default,会产生很多时间为过往时间的文件,
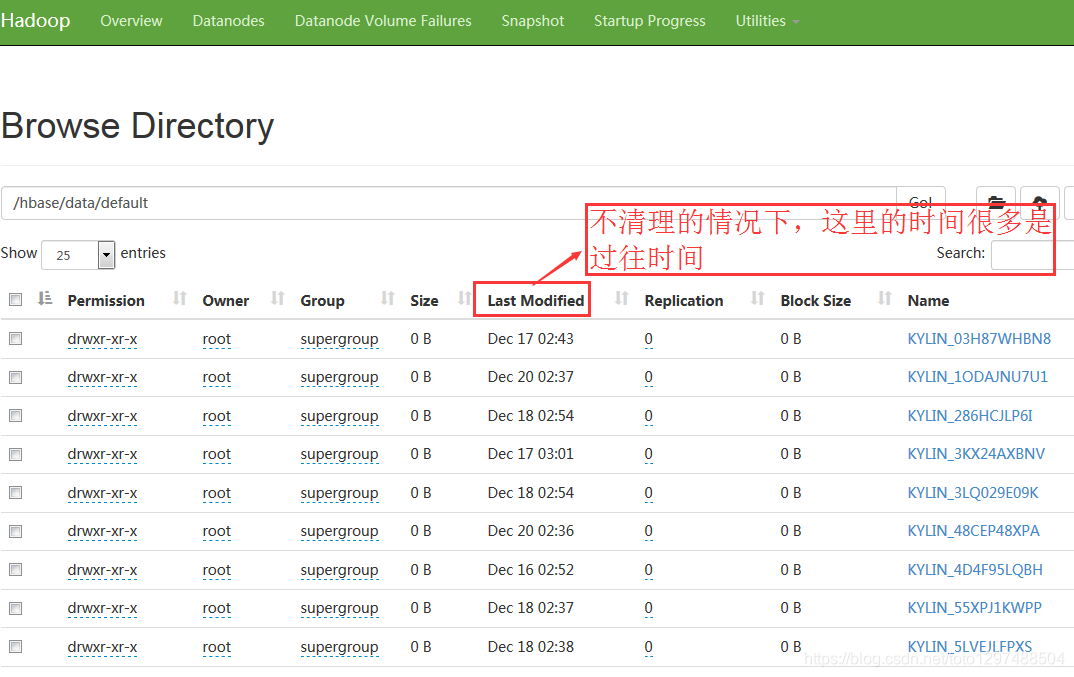
可以使用一下命令查看磁盘占用大小:
[xxxx apache-kylin-2.3.1-bin]# hdfs dfs -du -s -h /hbase/data/default
WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
## 13.1 G 35.9 G /hbase/data/default
[xxxx apache-kylin-2.3.1-bin]#
- 1
- 2
- 3
- 4
- 5
其中:13.1 G 表示的是一个节点中暂用磁盘的大小,35.9 G
如果这个临时中间文件不处理,最终将导致http://namenodeip:hdfs对应的port/dfshealth.html#tab-datanode:
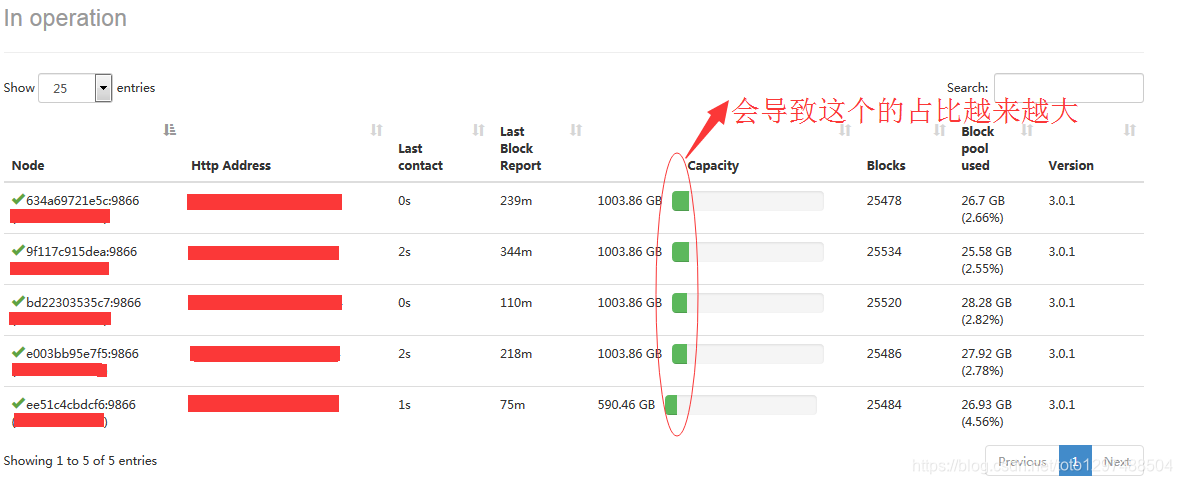
官网介绍:
Kylin 在构建 cube 期间会在 HDFS 上生成中间文件;除此之外,当清理/删除/合并 cube 时,一些 HBase 表可能被遗留在 HBase 却以后再也不会被查询;虽然 Kylin 已经开始做自动化的垃圾回收,但不一定能覆盖到所有的情况;你可以定期做离线的存储清理:
步骤:
1. 检查哪些资源可以清理,这一步不会删除任何东西:
export KYLIN_HOME=/path/to/kylin_home
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false
- 1
- 2
请将这里的 (version) 替换为你安装的 Kylin jar 版本。
2. 你可以抽查一两个资源来检查它们是否已经没有被引用了;然后加上“–delete true”选项进行清理。
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true
- 1
完成后,Hive 里的中间表, HDFS 上的中间文件及 HBase 中的 HTables 都会被移除。
3. 如果您想要删除所有资源;可添加 “–force true” 选项:
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --force true --delete true
- 1
完成后,Hive 中所有的中间表, HDFS 上所有的中间文件及 HBase 中的 HTables 都会被移除。
1.12 调优:减少Cube Dimensions维度数
做多维数据分析的时候,一般都要涉及到SQL,在这个过程中适当控制一些SQL,使用尽可能少的字段列以实现相同的数据查询需求。
因为维度列越多,cuboid的数量越多,需要的内存越多,cube build的时候时间也越长,生成的数据也越大。对于有n个维度的cube,组合字后会产生22…*(第n个2)体量的数据。
也就是说减少如下的Dimensions数量:
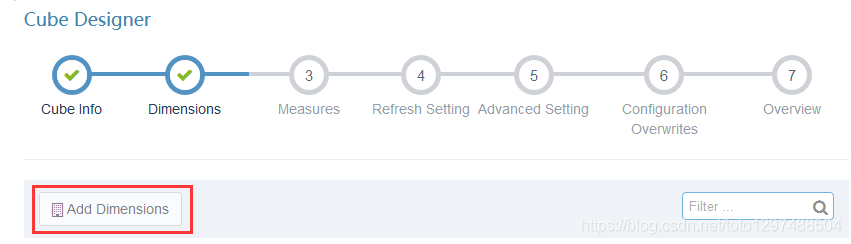
1.13 调优:定义measure列
对于定义measure,结果将在cube build前就预处理好,作为度量列的字段不要在Cube的Dimensions中出现,以减少Cuboid的数量 。这里包括两处:
A:Model创建过程中指定好Measures列,例如:
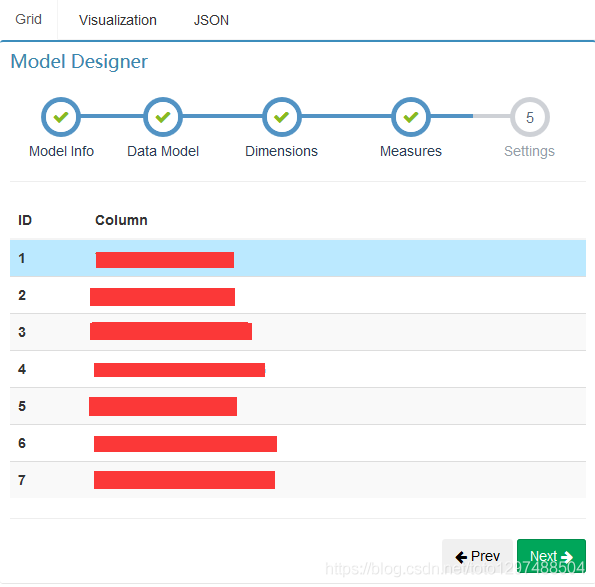
B:增加Cube Measures列的值
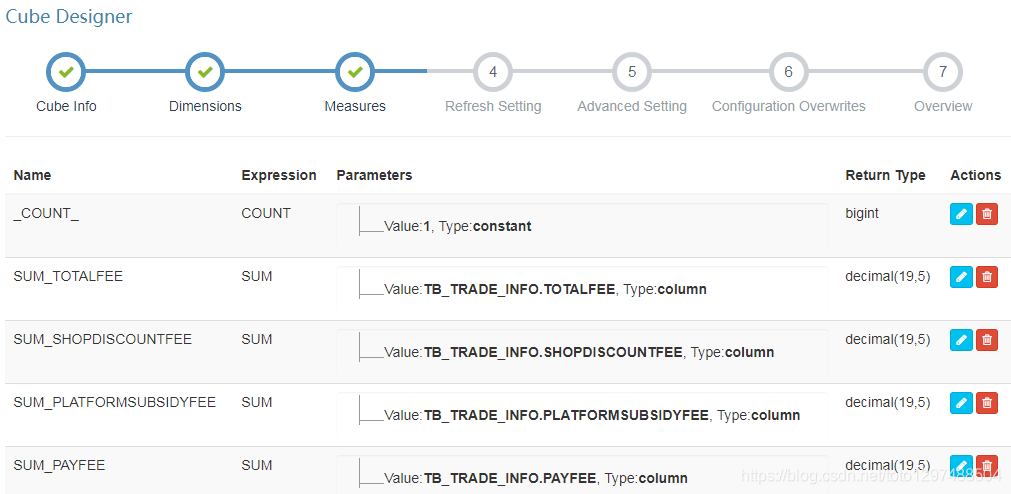
1.14 调优+错误总结:解决sum的时候结果莫名其妙的问题
出现这个现象的原因是在该定义measure的列上没有定义相关的度量值。具体添加方式如上面的:定义measure列
1.15 调优:定期merge cube
在kylin的model下的cube后见面的:
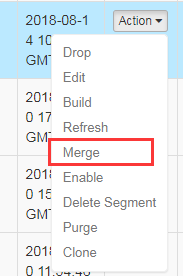
另外:设置好合适的Merge周期
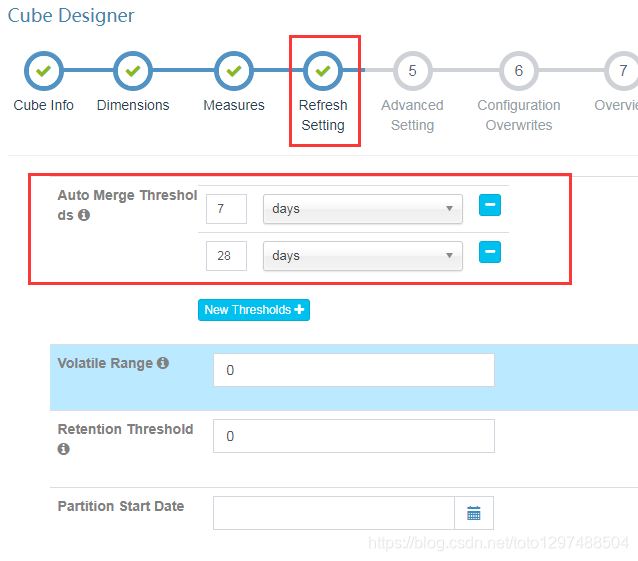
1.16 调优:对于维度多于12个场景
在Advanced Setting中对维度进行Aggregation Groups分组。
也就是说在下面的维度列进行分组设置。
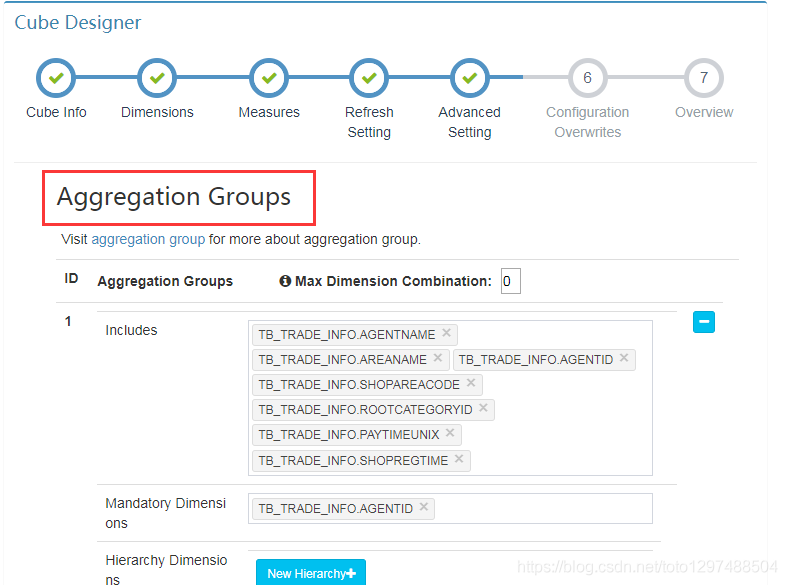
每组只填写好真正需要的维度列。添加新的分组的时候,可以使用:

在设置的时候一定要记着2的n次方这个问题。尽可能减少n(维度数量)这个值。
1.17 调优:创建中间平表(来自官网)
这一步将数据从源Hive表提取出来(和所有join的表一起)并插入到一个中间平表。如果Cube是分区的,Kylin会加上一个时间条件以确保只有在时间范围内的数据才会被提取。你可以在这个步骤的log查看相关的Hive命令,比如:
hive -e "USE default; DROP TABLE IF EXISTS kylin_intermediate_airline_cube_v3610f668a3cdb437e8373c034430f6c34; CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_airline_cube_v3610f668a3cdb437e8373c034430f6c34 (AIRLINE_FLIGHTDATE date,AIRLINE_YEAR int,AIRLINE_QUARTER int,...,AIRLINE_ARRDELAYMINUTES int) STORED AS SEQUENCEFILE LOCATION 'hdfs:///kylin/kylin200instance/kylin-0a8d71e8-df77-495f-b501-03c06f785b6c/kylin_intermediate_airline_cube_v3610f668a3cdb437e8373c034430f6c34'; SET dfs.replication=2; SET hive.exec.compress.output=true; SET hive.auto.convert.join.noconditionaltask=true; SET hive.auto.convert.join.noconditionaltask.size=100000000; SET mapreduce.job.split.metainfo.maxsize=-1; INSERT OVERWRITE TABLE kylin_intermediate_airline_cube_v3610f668a3cdb437e8373c034430f6c34 SELECT AIRLINE.FLIGHTDATE ,AIRLINE.YEAR ,AIRLINE.QUARTER ,... ,AIRLINE.ARRDELAYMINUTES FROM AIRLINE.AIRLINE as AIRLINE WHERE (AIRLINE.FLIGHTDATE >= '1987-10-01' AND AIRLINE.FLIGHTDATE < '2017-01-01');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
在Hive命令运行时,Kylin会用conf/kylin_hive_conf.properties里的配置,比如保留更少的冗余备份和启用Hive的mapper side join。需要的话可以根据集群的具体情况增加其他配置。
如果cube的分区列(在这个案例中是”FIGHTDATE”)与Hive表的分区列相同,那么根据它过滤数据能让Hive聪明地跳过不匹配的分区。因此强烈建议用Hive的分区列(如果它是日期列)作为cube的分区列。这对于那些数据量很大的表来说几乎是必须的,否则Hive不得不每次在这步扫描全部文件,消耗非常长的时间。
1.18 调优:重新分发中间表(来自官网)
在之前的一步之后,Hive在HDFS上的目录里生成了数据文件:有些是大文件,有些是小文件甚至空文件。这种不平衡的文件分布会导致之后的MR任务出现数据倾斜的问题:有些mapper完成得很快,但其他的就很慢。针对这个问题,Kylin增加了这一个步骤来“重新分发”数据,这是示例输出:
total input rows = 159869711
expected input rows per mapper = 1000000
num reducers for RedistributeFlatHiveTableStep = 160
- 1
- 2
- 3
重新分发表的命令:
hive -e "USE default;
SET dfs.replication=2;
SET hive.exec.compress.output=true;
SET hive.auto.convert.join.noconditionaltask=true;
SET hive.auto.convert.join.noconditionaltask.size=100000000;
SET mapreduce.job.split.metainfo.maxsize=-1;
set mapreduce.job.reduces=160;
set hive.merge.mapredfiles=false;
INSERT OVERWRITE TABLE kylin_intermediate_airline_cube_v3610f668a3cdb437e8373c034430f6c34 SELECT * FROM kylin_intermediate_airline_cube_v3610f668a3cdb437e8373c034430f6c34 DISTRIBUTE BY RAND();
"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
首先,Kylin计算出中间表的行数,然后基于行数的大小算出重新分发数据需要的文件数。默认情况下,Kylin为每一百万行分配一个文件。在这个例子中,有1.6亿行和160个reducer,每个reducer会写一个文件。在接下来对这张表进行的MR步骤里,Hadoop会启动和文件相同数量的mapper来处理数据(通常一百万行数据比一个HDFS数据块要小)。如果你的日常数据量没有这么大或者Hadoop集群有足够的资源,你或许想要更多的并发数,这时可以将conf/kylin.properties里的kylin.job.mapreduce.mapper.input.rows设为小一点的数值,比如:
kylin.job.mapreduce.mapper.input.rows=500000
- 1
其次,Kylin会运行 “INSERT OVERWRITE TABLE … DISTRIBUTE BY “ 形式的HiveQL来分发数据到指定数量的reducer上。
在很多情况下,Kylin请求Hive随机分发数据到reducer,然后得到大小相近的文件,分发的语句是”DISTRIBUTE BY RAND()”。
如果你的cube指定了一个高基数的列,比如”USER_ID”,作为”分片”维度(在cube的“高级设置”页面),Kylin会让Hive根据该列的值重新分发数据,那么在该列有着相同值的行将被分发到同一个文件。这比随机要分发要好得多,因为不仅重新分布了数据,并且在没有额外代价的情况下对数据进行了预先分类,如此一来接下来的cube build处理会从中受益。在典型的场景下,这样优化可以减少40%的build时长。在这个案例中分发的语句是”DISTRIBUTE BY USER_ID”:
请注意: 1)“分片”列应该是高基数的维度列,并且它会出现在很多的cuboid中(不只是出现在少数的cuboid)。 使用它来合理进行分发可以在每个时间范围内的数据均匀分布,否则会造成数据倾斜,从而降低build效率。典型的正面例子是:“USER_ID”、“SELLER_ID”、“PRODUCT”、“CELL_NUMBER”等等,这些列的基数应该大于一千(远大于reducer的数量)。 2)”分片”对cube的存储同样有好处,不过这超出了本文的范围。
1.19 调优:提取事实表的唯一列(来自官网)
在这一步骤Kylin运行MR任务来提取使用字典编码的维度列的唯一值。
实际上这步另外还做了一些事情:通过HyperLogLog计数器收集cube的统计数据,用于估算每个cuboid的行数。如果你发现mapper运行得很慢,这通常表明cube的设计太过复杂,请参考
优化cube设计来简化cube。如果reducer出现了内存溢出错误,这表明cuboid组合真的太多了或者是YARN的内存分配满足不了需要。如果这一步从任何意义上讲不能在合理的时间内完成,你可以放弃任务并考虑重新设计cube,因为继续下去会花费更长的时间。
你可以通过降低取样的比例(kylin.job.cubing.inmen.sampling.percent)来加速这个步骤,但是帮助可能不大而且影响了cube统计数据的准确性,所有我们并不推荐。
1.20 调优:构建维度字典(来自官网)
有了前一步提取的维度列唯一值,Kylin会在内存里构建字典。通常这一步比较快,但如果唯一值集合很大,Kylin可能会报出类似“字典不支持过高基数”。对于UHC类型的列,请使用其他编码方式,比如“fixed_length”、“integer”等等。
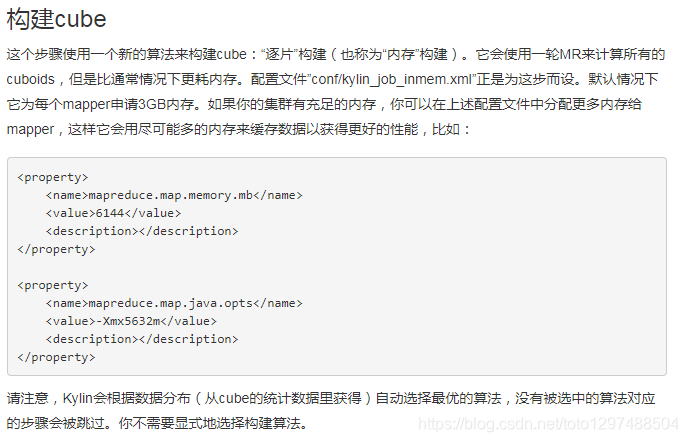
1.21 调优:构建基础cuboid,调整map大小 和reduce的数量
这一步用Hive的中间表构建基础的cuboid,是“逐层”构建cube算法的第一轮MR计算。Mapper的数目与第二步的reducer数目相等;Reducer的数目是根据cube统计数据估算的:默认情况下每500MB输出使用一个reducer;如果观察到reducer的数量较少,你可以将kylin.properties里的“kylin.job.mapreduce.default.reduce.input.mb”设为小一点的数值以获得过多的资源,比如:
kylin.job.mapreduce.default.reduce.input.mb=200
- 1
1.22 调优:设置好Mandatory Dimensions 列
这种维度意味着每次查询的group by中都会携带的,将某一个dimension设置为mandatory可以将cuboid的个数减少一半
因为我们确定每一次group by都会携带字段A,将A设置成Mandatory Dimensions后,那么就可以省去所有不包含A这个维度的cuboid了
好的技术文章:
http://kyligence.io/zh/2017/04/21/apache-kylin-advanced-setting-mandatory-dimension-principle/
1.23 调优:设置Joint Dimensions
很好的一篇博文:
http://kyligence.io/zh/2017/04/07/apache-kylin-advanced-setting-joint-dimension-principle/
1.24 调优:设置Hierarchy Dimension
以下文章很好的介绍了如何关于Hierarchy Dimension的调优策略
- 1
http://kyligence.io/zh/2017/04/14/apache-kylin-advanced-setting-hierarchy-dimension-principle/
1.25 调优:Configuration Overwrites 高级设置
参考官网更详细介绍:
http://kylin.apache.org/cn/docs/install/advance_settings.html
另外在里面最好设置数据压缩方式,以减少磁盘占用
1.26 调优:改变kylin中Advanced Setting的维度顺序
对于kylin中频繁使用,或着一定使用的维度列,在设置Includes的时候,将这些配置的靠前一些。因为kylin内部机制是越靠前的越优先被找到,从而加快查询速度。
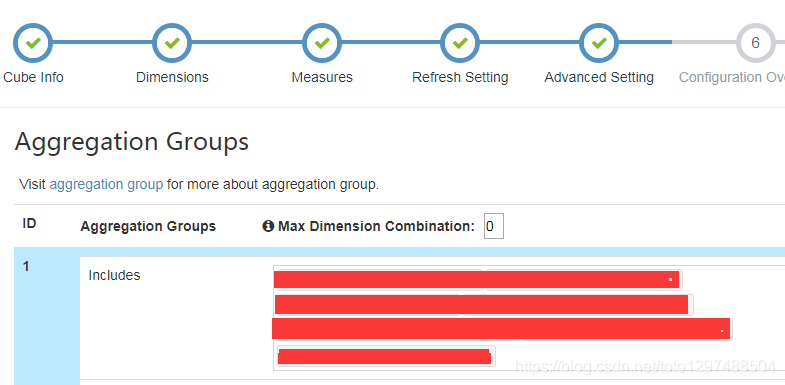
就是上面红色区域的维度列的顺序。
1.27 调优:Build Cube With Spark
kylin.engine.spark.rdd-partition-cut-mb = 10 (默认 200)

直接影响 spark 的分区数,首先大概清楚 cuboid 数据总大小,例如 6032mb,那么 partitions = 6032/10 = 600,即会产生 600 个小文件,随后在 step8 跑 mr 时,就会拉起 600 个 map,使得 服务器负载骤增,发生报警。
调整参数后执行,如何跟踪服务器情况?只需跟踪 step8 的 mr 情况即可
① http://bgnode1:8088/cluster/scheduler 找到对应的 application
② %of Cluster 是否过高
③ 进入详情查看 map 数量是否过多,若过多则很可能是 rdd-partition-cut-mb 设置过 小导致,此时要调大参数 因此,合理的调整 rdd-partition-cut-mb 能防止机器报警。 这一步是对每一层的 cuboid 依次进行计算并写入 hdfs,耗时会比较长
kylin.engine.spark-conf.spark.executor.cores = 2
kylin.engine.spark-conf.spark.executor.memory = 4G
- 1
- 2
这两个参数自行根据数据大小来调整,cores 和 memory 都不是越大越好,需根据要 build 的数据量,再三调整测试最优值。
1.28 调优:Rowkey调优
为什么要优化 Rowkey? Apache Kylin 使用 HBase 做为 Cube 的存储引擎。而 HBase 是 Key-Value 数据库,这个 Key 在 HBase 中称为 Rowkey。为了能够支持按多个维度进行查询,Kylin 需要将多个维度值以某 种次序组成 Rowkey。HBase Scan Range,排在 Rowkey 靠前部分的维度,将比排在靠后部分 的维度更易于做筛选,查询效率更高。
那些维度适合排在前部分?
- 基数高的排前面 在 Load Hive Table 时,勾选 Calculate column cardinality,即可在 load 时计算各字段的基 数,并在 Data Source -> Tables -> 点击相应的 table 查看
1.29 调优:在查询中被用做过滤条件的维度放在非过滤条件维度的前面
这一个环节如果 rowkey 没设计好,会导致以下问题:
- Cuboid 转 hfile 后,会因数据分布不均匀,导致单点问题,使得服务器内存过高,触发报 警
- Hbase 寻址慢,查询性能下降 除了各维度在 Rowkey 上的次序外,维度的编码方法对于空间占用及查询性能也有着显 著的影响。 合适的编码能减少维度对空间的占用,同时编码值也会加速查询过滤。
1.30 调优:罗列几个显著影响性能的参数
以下都是默认值:
kylin.engine.spark.rdd-partition-cut-mb = 10
kylin.engine.spark-conf.spark.executor.memory = 4G
kylin.storage.hbase.region-cut-gb = 5
官网提供的可设置参数:http://kylin.apache.org/docs/install/configuration.html
1.31 调优:其它调优思路
通过./kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader [cubeName] 查看 cuboid 总大小,然后再根据以下步骤进行对参数的调整:
1. 3 种降维选项是否有根据业务实际情况调整
2. 有没合理的使用分区列
3. 小文件是否过多
4. reducer 是否过少
5. spark partitions 是否合适
6. spark 的 excutor 内存和 cores 数量分配是否合理
7. cuboid 文件转 hfile 时,map 是否过多,reducer 是否过少(region 块的大小和数量是否合 理)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.32 调优:输出压缩(来自官网)
使用 Snappy 压缩 HBase Cube:

另一个选项为 Gzip:

压缩输出的结果为:

Snappy 和 Ggzip 的区别在时间上少于 1% 但是在大小上有 18% 差别
1.33 调优:压缩Hive表(来自官网)
时间分布如下:

按概念分组的详细信息 :

67 % 用来 build / process flat 表且遵守 30% 用来 build cube
大量时间用在了第一步。
这种时间分布在有很少的 measures 和很少的 dim (或者是非常优化的) 的 cube 中是很典型的
尝试在 Hive 输入表中使用 ORC 格式和压缩(Snappy):

前三步 (Flat Table) 的时间已经提升了一半。
其他列式格式可以被测试:

• ORC
• 使用 Snappy 的 ORC 压缩
但结果比使用 Sequence 文件的效果差。
请看:Shaofengshi in MailList 关于这个的评论
第二步是重新分配 Flat Hive 表:
是一个简单的 row count,可以做出两个近似值
- 如果其不需要精确,fact 表的 row 可以被统计→ 这可以与步骤 1 并行执行 (且 99% 的时间将是精确的)

• 将来的版本中 (KYLIN-2165 v2.0),这一步将使用 Hive 表数据实现。
1.34 调优:Hive 表 (失败) 分区(来自官网)
Rows 的分布为:
| Table | ROWS |
|---|---|
| Fact Table | 3.900.00 |
| Dim | 2.100 |
build flat 表的查询语句 (简单版本):
SELECT
,DIM_DATE.X
,DIM_DATE.y
,FACT_POSICIONES.BALANCE
FROM FACT_POSICIONES INNER JOIN DIM_DATE
ON ID_FECHA = .ID_FECHA
WHERE (ID_DATE >= '2016-12-08' AND ID_DATE < '2016-12-23')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里存在的问题是,Hive 只使用 1 个 Map 创建 Flat 表。重要的是我们要改变这种行为。解决方案是在同一列将 DIM 和 FACT 分区
• 选项 1:在 Hive 表中使用 id_date 作为分区列。这有一个大问题:Hive metastore 意味着几百个分区而不是几千个 (在 Hive 9452 中有一个解决该问题的方法但现在还未完成)
• 选项 2:生成一个新列如 Monthslot。
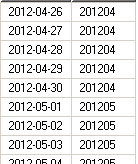
为 dim 和 fact 表添加同一个列
现在,用这个新的条件 join 表来更新数据模型
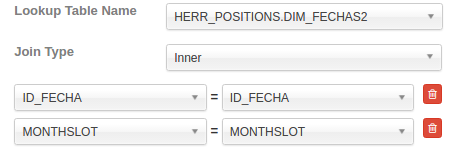
生成 flat 表的新查询类似于:
SELECT *
FROM FACT_POSICIONES **INNER JOIN** DIM_DATE
ON ID_FECHA = .ID_FECHA AND MONTHSLOT=MONTHSLOT
- 1
- 2
- 3
用这个数据模型 rebuild 新 cube
结果,性能更糟了
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

