
- 1(附源码)ssm基于Html+css的音乐网站的设计与实现 毕业设计181627_html音乐网站框架设计
- 2vrchat模型房_vrchat人物模型 1.0 官方版
- 3盘点百度、阿里、腾讯、华为自动驾驶战略
- 4python 全栈开发,Day75(Django与Ajax,文件上传,ajax发送json数据,基于Ajax的文件上传,SweetAlert插件)...
- 5Android5.0之NavigationView的使用
- 6全球首个AI女主播上岗了!太惊艳了!
- 7魔兽世界私服架设教程——如何搭建魔兽世界私服
- 8蓝桥杯备考冲刺必刷题(Python) | 549 扫雷
- 9Java –将值附加到Object []数组中
- 10torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 86.00 MiB (GPU 0; 31.74 GiB total
OpenMP入门及基本用法_#pragma omp parallel for
赞
踩
1.OpenMP的基本概念
OpenMP 是 Open MultiProcessing 的缩写。OpenMP 并不是一个简单的函数库,而是一个诸多编译器支持的框架,是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的#pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行1.OpenMP的基本概念)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
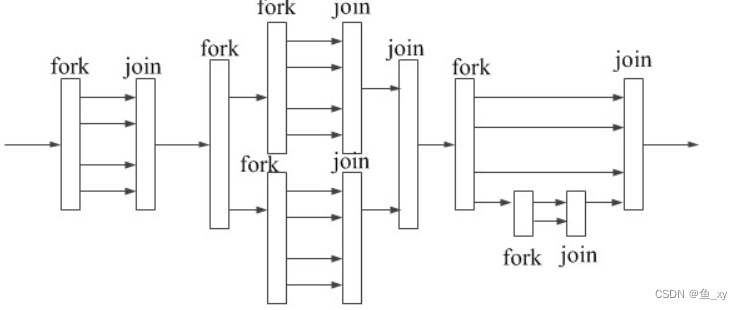
2.OpenMP的运行模式
OpenMP的执行模式采用fork-join的形式,其中fork创建新线程或者唤醒已有线程;join即多线程的汇合。fork-join执行模式在刚开始执行的时候,只有一个称为“主线程”的运行线程存在。主线程在运行过程中,当遇到需要进行并行计算的时候,派生出线程来执行并行任务。在并行执行的时候,主线程和派生线程共同工作。在并行代码执行结束后,派生线程退出或者阻塞,不再工作,控制流程回到单独的主线程中。整个流程如下图所示:
OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
1.编译器指令
OpenMP的编译器指令的目标主要有:1)产生一个并行区域;2)划分线程中的代码块;3)在线程之间分配循环迭代;4)序列化代码段;5)同步线程间的工作。编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句],[子句] ,[…]。常用的功能指令如下:
parallel :用在一个结构块之前,表示这段代码将被多个线程并行执行;
for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
parallel for :parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
sections :用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
parallel sections:parallel和sections两个语句的结合,类似于parallel for;
single:用在并行域内,表示一段只被单个线程执行的代码;
critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
flush:保证各个OpenMP线程的数据影像的一致性;
barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
atomic:用于指定一个数据操作需要原子性地完成;
master:用于指定一段代码由主线程执行;
相应的OpenMP子句为:
collapse:例如双重的嵌套循环,将嵌套循环扁平化,但实际使用需要看多重循环满不满足扁平化条件。
private:指定一个或多个变量在每个线程中都有它自己的私有变量;
firstprivate:指定一个或多个变量在每个线程都有它自己的私有变量,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
num_threads:指定并行域内的线程的数目;
schedule:指定for任务分担中的任务分配调度类型;
shared:指定一个或多个变量为多个线程间的共享变量;
default:用来指定并行域内的变量的使用方式,缺省是shared。
2.API函数
常用的有:
omp_get_num_threads:返回并行域中总线程的数量。
omp_get_thread_num:返回当前工作的线程编号。
omp_set_num_threads:设定并行域内开辟线程的数量。
omp_get_wtime:openmp中自带的计时函数,用于检测并行优化效果。
3.环境变量
OpenMP提供了一些环境变量,用来在运行时对并行代码的执行进行控制。这些环境变量可以控制:1)设置线程数;2)指定循环如何划分;3)将线程绑定到处理器;4)启用/禁用嵌套并行,设置最大的嵌套并行级别;5)启用/禁用动态线程;6)设置线程堆栈大小;7)设置线程等待策略。常用的环境变量:
OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
OMP_NUM_THREADS:用于设置并行域中的线程数;
OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
OMP_NESTED:指出是否可以并行嵌套。
3.OpenMP编译语句的具体实现
(1)parallel 是用来构造一个并行块的,也可以使用其他指令如for、sections等和它配合使用。parallel指令是用来为一段代码创建多个线程来执行它的。parallel块中的每行代码都被多个线程重复执行。和传统的创建线程函数比起来,相当于为一个线程入口函数重复调用创建线程函数来创建线程并等待线程执行完。程序示例如下:
-
void fun(){ -
#pragma omp parallel -
{ -
cout<<"线程数:"<<omp_get_num_threads()<<endl; -
} -
system("pause"); -
}
线程数可以用编译器的环境变量OMP_NUM_THREADS= 设置,此程序返回的是并行区域内线程的总数。
(2)for和for collapse()子句
-
double res[MAX];int i; -
#pragma omp parallel for -
for (i=0;i<MAX;i++){ -
res[i]=huge(); -
}
parallel for主要作用是将for循环进行分块计算。
-
#pragma omp parallel for collapse(2) -
for(i=0;i<MAX1;i++){ -
for(j=0;j<MAX2;j++){ -
[expression]; -
} -
}
在用collapse()子句时一定要提前确认在嵌套循环是否可以进行扁平化,例如:
-
for(i=start1;i<MAX1;i++){ -
for(j=start2;j<MAX2;j++){ -
B[i][j]=(B[i][j+1]+B[i][j-1])/2; -
} -
}
在这个嵌套循环中,数组B的计算结果跟循环迭代的次序有关,循环迭代中并不是彼此独立的,这样的循环不管几层循环,都是不能去合并的。
(3)reduction子句的运用
例如对下面求平均数的示例,当parallel for将循环将线程数分块后,reduction会在线程中创建一块私有的内存空间ave[],并在最后相加。
-
double ave = 0.0;A[MAX];int i; -
#pragma omp parallel for reduction(+:ave) -
for(i=0;i<MAX;i++){ -
ave+=A[i]; -
} -
ave=ave/MAX;
注意:1.根据归约操作的不同,我们需要对归约目标进行初始化。2.规约目标变量必须是共享变量,不能是线程私有。
(4)线程同步指令
例如:#pragma omp barrier :当有线程到达该位置时,在此空转等待,直到线程全部到达,阻塞解除。这是一种显示阻塞,但是在openmp的语句和结构中还存在着隐式阻塞的。例如在#pragma omp parallel 域中即使我们不添加barrier,线程也会在这个位置进行等待和同步。不管是显示还是隐式阻塞都是存在着性能损失的,线程数越多损失就越大,所以在程序中,我们要谨慎添加显示开销,并且可以适当的,谨慎的去关闭结构中的隐式阻塞,例如子句:nowait。
(5)sections & section
section语句是用在sections语句里用来将sections语句里的代码划分成几个不同的段,每段都并行执行。语法格式如下:
#pragma omp [parallel] sections [子句]
{
#pragma omp section
{
代码块
}
#pragma omp section
{
代码块
}
}
说明各个section里的代码都是并行执行的,并且各个section被分配到不同的线程执行。
使用section语句时,需要注意的是这种方式需要保证各个section里的代码执行时间相差不大,否则某个section执行时间比其他section过长就达不到并行执行的效果了。用for语句来分摊是由系统自动进行,只要每次循环间没有时间上的差距,那么分摊是很均匀的,使用section来划分线程是一种手工划分线程的方式。
(6)task 任务池
前面介绍了section结构,但是section结构是有它的局限性的,比如section中的任务必须是一种确定的,静态的,我们可以写成上下文的。当我们需要处理动态任务(任务的总数时动态的)时,我们必须要考虑使用这种task任务池的模式,其支持静态任务和动态任务的划分,例如:
-
#include <stdio.h> -
#include <omp.h> -
#define THRESHOLD 9 -
int fib(int n) -
{ -
int i, j; -
if (n<2) -
return n; -
#pragma omp task shared(i) firstprivate(n) final(n <= THRESHOLD) -
i=fib(n-1); -
#pragma omp task shared(j) firstprivate(n) final(n <= THRESHOLD) -
j=fib(n-2); -
#pragma omp taskwait -
return i+j; -
} -
int main() -
{ -
int n = 30; -
omp_set_dynamic(0); -
omp_set_num_threads(4); -
#pragma omp parallel shared(n) -
{ -
#pragma omp single -
printf ("fib(%d) = %d\n", n, fib(n)); -
} -
} -
% CC -xopenmp -xO3 task_example.cc -
% a.out -
fib(30) = 832040
在本例中,并行区域由四个线程执行。single 区域确保只由其中一个线程执行调用 fib(n) 的 print 语句。
对 fib(n) 的调用会生成两个任务(由 task 指令指示)。其中一个任务调用 fib(n-1),另一个任务调用 fib(n-2),将这些调用的返回值加在一起即可产生由 fib(n) 返回的值。对 fib(n-1) 和 fib(n-2) 的每个调用会进而生成两个任务,这两个任务递归生成,直到传递给 fib() 的参数小于 2。
每个 task 指令中的 final 子句。如果 final 子句表达式 (n <= THRESHOLD) 求值结果为 true,则生成的任务将为最终 (final) 任务。执行最终 (final) 任务期间遇到的所有 task 构造将生成包括 (included) 和最终 (final) 任务。当使用参数 n = 9, 8, ..., 2 调用 fib() 时,将生成包括 (included) 任务。这些任务将由遇到这些任务的线程立即执行,从而减少在池中放置任务的开销。
taskwait 指令可确保在调用 fib() 的同一过程中生成的两个任务(即计算 i 和 j 的任务)在对 fib() 的调用返回之前已完成。
虽然只有一个线程执行 single 指令(因而只有第一个线程调用 fib()),但是所有四个线程都将参与执行生成的任务和放在池中的任务。

