
- 1C++基础教程_c十十编程教学是什么
- 2tomcat压缩写法_compressablemimetype
- 3TensorFlow 安装GPU版本_tensorflow不分gpu版本了
- 4【面试准备】安全运维_配置各类安全设施,包括防火墙规则配置、权限管理、访问管理等面试云计算运维
- 5linux上datax 安装以及使用
- 6java httpclient 异步请求_java_java实现HttpClient异步请求资源的方法,本文实例讲述了java实现HttpClien - phpStudy...
- 7机器学习——K-近邻算法实例实战_k近邻算法经典案例
- 8linux系统中pci总线设备查看的几种方式_linux 查看pci设备
- 9大模型技术学习系列(4): langchain+ollama构建本地大模型应用_ollama + langchain实现的大模型 学习历史
- 10搭建邮箱服务器hMailServer详细教程(Windows)
OpenAI开放色情内容生成?百度AI怎么做【附内容审核方案_可以写黄文的ai
赞
踩
色情内容在网络中几乎无处不在,但由于保护机制、风险规避等原因,很多色情内容会被屏蔽或删除。
可是,据 Wired 报道,OpenAI 发布了一份文档草案,透露出他们正在探索色情和其他露骨内容领域。“我们正在探索是否能够通过 API 和 ChatGPT 负责任地提供在适合年龄的环境中生成 NSFW 内容的能力,我们期待更好地了解用户和社会对这一领域模型行为的期望。”
NSFW 是一个英文网络用语,“Not Safe For Work”或者“Not Suitable For Work”的缩写,意思就是某个网络内容不适合上班时间浏览,通常用于标记包含淫秽色情、暴力血腥、极端另类等内容的邮件、视频、博客、论坛帖子等。
一、网络中的色情内容
无论在传统媒体时代还是网络时代,色情内容一直“野火烧不尽”,漫画、链接、软文、ASMR 等都是色情内容的载体 。
早在生成式 AI 火爆全球之前,就有人提出了 AI 生成色情内容的风险问题。“深度伪造色情内容”(Deepfake Porn)是利用人工智能技术生成的虚假色情内容,通常通过深度学习算法,将某个人的脸部图像或身体部位合成到色情视频中,以产生高度逼真的假色情影像。
英国政府网站称,近年来“深度伪造色情内容”变得越来越普遍,全世界每个月的这类图像浏览量达数百万次。2023 年 3 月,微软推出了 AI 图像生成器产品 Copilot Designer,有内部工程师发现其可生成暴力色情图,但微软却拒绝整改,无奈之下该工程师只能将其举报至政府。曾经,Stability AI 开源了根据文本生成图像的 AI 程序,Reddit 和 4chan 上的社区用户开始利用该 AI 生成真实和动画风格的裸体人物图像,其中大部分是女性,以及名人的换脸裸体图像。

目前,OpenAI 发言人格蕾丝·麦奎尔拒绝透露 OpenAI 对显式内容生成的探索涉及哪些细节,也拒绝透露该公司在这一想法上收到了哪些反馈。可是不久前,OpenAI 的首席技术官米拉·穆拉蒂称,“不确定”公司未来是否会允许使用 Sora 制作裸露内容。
二、AI 生成色情内容的现状
色情内容一直有很大的供求市场,为了逃避检测,色情内容不断以各种各样的形式进行伪装,它们表面上可能是无害的或符合一般社交规范的。当人工智能技术突飞猛进后,色情内容的生成、传播更为普遍。

色情内容可能会伪装成多种类型的文本。含有双关意味或暗示性强的“幽默”文本,和包含露骨或不当性暗示的日常生活记叙,是最为常见的色情信息载体。有时候,AI 会伪造新闻摘要、故事情节、聊天记录,并在其中加入引人遐想的描写,从真实性的角度误导读者。尽管较少见,但不排除有人将 AI 生成的色情内容伪装成教育材料,如教科书摘录、科学解释等,以讲解科学知识为幌子,展示不当行为或场景。
色情内容还会隐藏在图片和视频中。利用先进的图像处理技术,AI 能生成高度逼真的、含有性暗示的影像,也可以生成含有不当言论的音频。它们会将真实素材和虚假的合成元素混合在一起,所以往往难以检测。此外,为了更自然地融入社交平台,一些先进的 AI 系统可能会采用流行动漫或插画风格来制作图片,模仿电影、电视剧的片段,甚至模拟真实用户的行为,自动发布、转发或互动涉及色情内容的帖子。
用 AI 生成和传播色情内容是不良的行为,违反了社会公德和法律法规:

色情内容无孔不入、防不胜防,想要更精准高效地识别色情信息,内容审核团队应密切关注行业动态和技术发展趋势,不断更新检测算法,采用更复杂的机器学习模型来识别和过滤不良信息。可是,对于很多公司、个人开发者来说,自建内容审核程序的成本过于高昂。
通过公有云或私有化部署等形式,接入市场上较为成熟的内容审核平台,是高性价比的不二选择。
三、百度 AI 审核色情内容的强大优势
百度内容审核平台由智能机审平台与人机协同审核平台构成,拥有多项业内独家能力、百度亿级数据审核经验,敏感人物库业内最全、更新最快。
-
图片色情:智能识别图像中的色情和性感内容,包含色情违禁、儿童裸露、女性性感、艺术品色情等 18 个细分标签。
-
文本色情:对文本中的色情行为描述、色情资源链接、低俗交友、污秽文爱等内容进行识别。
-
音频色情:包含娇喘声识别和语音内容识别。先通过语音识别将音频内容转换为文字,再审核文本信息,可检测色情、暴恐违禁、政治敏感、低俗辱骂、恶意推广等语音内容,同时利用声纹检测进行娇喘声识别,高效过滤违规语音信息。
-
视频和直播色情:综合图像、文本审核能力,对视频内的画面、标题进行同步审核,全方位过滤违规视频。

百度内容审核平台,5 分钟即可完成规则配置,零门槛、可视化界面操作,多维度数据导出功能,能让企业快速接入使用、减少开发维护成本。
-
审核维度丰富:紧跟监管需求,实时同步政府指令,提供业内最丰富的审核维度,其中图像审核具备恶心图、质量检测的独家识别能力。
-
审核粒度细腻:具备业界最丰富、全面的分类标签体系,并且持续更新。可根据业务需求,自由组合标签,让模型效果犹如“量身定制”。
-
模型准确率高:基于百度海量数据训练优化,利用深度学习技术及算法迭代模型,识别准确率高,减少人工复查率,有效降低企业运营成本。
-
易用性强:一次上传,多维度同时审核后统一返回审核结果;提供符合 RESTful 规范的标准 API 接口和多语言服务端 SDK,易于集成和开发。
内容审核平台的常见格式要求、请求限制如下:
| 媒体类型 | 接口地址 | 格式支持 | 时长限制 | 大小限制 | 其他注意事项 |
| 图像 | https://aip.baidubce.com/rest/2.0/solution/v1/img_censor/v2/user_defined | PNG, JPG, JPEG, BMP, GIF(仅首帧), Webp, TIFF | / | base64后 >= 5KB, <= 4MB; 最短边 >= 128像素, <= 4096像素 | 需Base64编码,不含图像头 图像需提供URL地址,以URL形式请求(图像URL需要做urlencode) |
| 文本 | https://aip.baidubce.com/rest/2.0/solution/v1/text_censor/v2/user_defined | - | / | <= 20000字节 (约6666字符) | 支持中文(简体、繁体) 支持英文 |
| 短视频 同步审核 | https://aip.baidubce.com/rest/2.0/solution/v1/video_censor/v2/user_defined | mp4, avi, flv, mov | <= 5分钟 | 建议 <= 50MB | 仅支持审核画面 |
| 长视频 异步审核 | https://aip.baidubce.com/rest/2.0/solution/v1/video_censor/v1/video/submit | mp4, avi, flv, mov, wmv, ts, mpeg, 3gpp, asf, f4v, mkv, m4a, mp3, mp2, mpg, ogg, mts, wma, webm | 建议<=2小时 | 建议 <= 2GB | 支持审核画面和音频 |
| 短音频 同步审核 | https://aip.baidubce.com/rest/2.0/solution/v1/voice_censor/v3/user_defined | pcm(推荐), mp3, wav, aac, amr, m4a | <= 60秒 | 大小 <= 10MB | 强烈建议使用pcm格式 支持普通话和英语 |
| 音频文件 异步审核 | https://aip.baidubce.com/rest/2.0/solution/v1/async_voice/submit | <= 60分钟 | 大小 <= 200MB | ||
| 文档审核 | https://aip.baidubce.com/rest/2.0/solution/v1/solution/document/v1/submit | txt, doc, docx, pdf, ppt, pptx, xls, xlsx | / | URL建议 <= 100MB base64编码建议 <= 10W字符 | / |
四、平台操作指南
“百度智能云·一念”的内容审核平台,拥有行业内唯一具备的大模型审核能力,覆盖涉黄、违禁、广告、恶心不适等丰富的审核维度,支持自定义黑白库和个性化审核策略配置,可以为业务健康发展保驾护航。
Step1:账号登录及资源领取
调用百度智能云的内容审核能力,首先需注册账号内容审核_内容安全_智能审核-百度AI开放平台。
然后根据操作指引,分别领取免费资源、创建应用、配置策略和调用服务。

点击薅羊毛!!一分钟快速领取某云平台内容审核免费测试资源!-CSDN博客,手把手教你怎么领取免费资源
Step2:在线验证
创建应用与配置策略完成后,即可进行在线验证。
策略管理页面:

策略配置页面:

在线审核/验证页面:

Step3: 编写示例程序
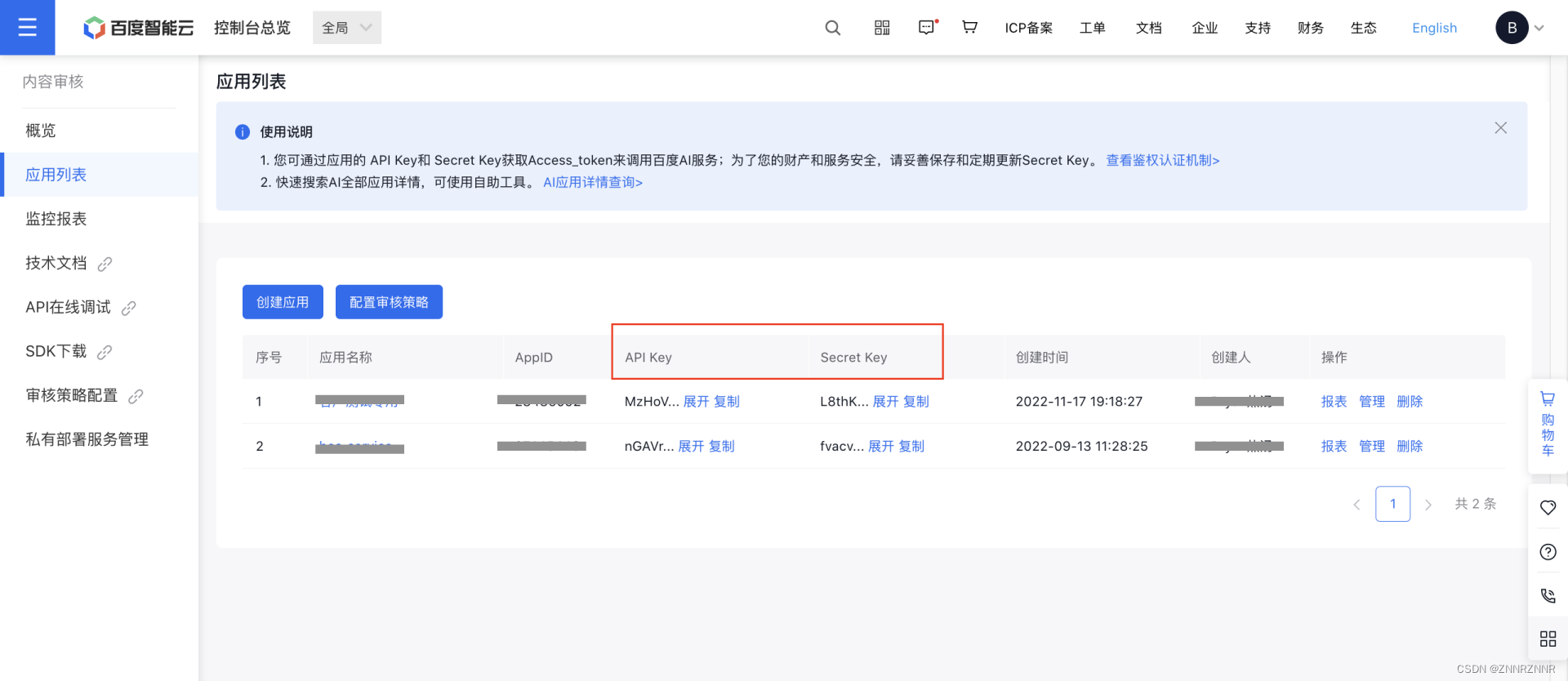
根据第一步创建应用时生成的 API KEY 以及 Secret KEY,就可以写一个能调用百度 AI 内容审核能力的示例代码。
准备开发环境
用 python 来快速搭建一个原型

Windows 快速测试包
Windows 平台的用户如果对 python 安装感到困难,可以下载一键测试包,下载地址:Windows测试包。
解压 zip 文件后,双击 run.bat 即可测试。
编写代码
新建一个 main.py
粘贴以下内容,不要忘记替换 API_KEY 以及 SECRET_KEY:
- # coding=utf-8
-
- import sys
- import json
- import base64
-
-
- # 保证兼容python2以及python3
- IS_PY3 = sys.version_info.major == 3
- if IS_PY3:
- from urllib.request import urlopen
- from urllib.request import Request
- from urllib.error import URLError
- from urllib.parse import urlencode
- from urllib.parse import quote_plus
- else:
- import urllib2
- from urllib import quote_plus
- from urllib2 import urlopen
- from urllib2 import Request
- from urllib2 import URLError
- from urllib import urlencode
-
- # 防止https证书校验不正确
- import ssl
- ssl._create_default_https_context = ssl._create_unverified_context
-
- API_KEY = 'eQnGqPdFTTctqkjHvdUEzmrC'
-
- SECRET_KEY = 'HDBuwWT4pfSBGyLkTEAYhwoQkoDGrWU2'
-
-
- IMAGE_CENSOR = "https://aip.baidubce.com/rest/2.0/solution/v1/img_censor/v2/user_defined"
-
- TEXT_CENSOR = "https://aip.baidubce.com/rest/2.0/solution/v1/text_censor/v2/user_defined";
-
- """ TOKEN start """
- TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
-
-
- """
- 获取token
- """
- def fetch_token():
- params = {'grant_type': 'client_credentials',
- 'client_id': API_KEY,
- 'client_secret': SECRET_KEY}
- post_data = urlencode(params)
- if (IS_PY3):
- post_data = post_data.encode('utf-8')
- req = Request(TOKEN_URL, post_data)
- try:
- f = urlopen(req, timeout=5)
- result_str = f.read()
- except URLError as err:
- print(err)
- if (IS_PY3):
- result_str = result_str.decode()
-
-
- result = json.loads(result_str)
-
- if ('access_token' in result.keys() and 'scope' in result.keys()):
- if not 'brain_all_scope' in result['scope'].split(' '):
- print ('please ensure has check the ability')
- exit()
- return result['access_token']
- else:
- print ('please overwrite the correct API_KEY and SECRET_KEY')
- exit()
-
- """
- 读取文件
- """
- def read_file(image_path):
- f = None
- try:
- f = open(image_path, 'rb')
- return f.read()
- except:
- print('read image file fail')
- return None
- finally:
- if f:
- f.close()
-
-
- """
- 调用远程服务
- """
- def request(url, data):
- req = Request(url, data.encode('utf-8'))
- has_error = False
- try:
- f = urlopen(req)
- result_str = f.read()
- if (IS_PY3):
- result_str = result_str.decode()
- return result_str
- except URLError as err:
- print(err)
-
- if __name__ == '__main__':
-
- # 获取access token
- token = fetch_token()
-
- # 拼接图像审核url
- image_url = IMAGE_CENSOR + "?access_token=" + token
-
- # 拼接文本审核url
- text_url = TEXT_CENSOR + "?access_token=" + token
-
-
- file_content = read_file('./image_normal.jpg')
- result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
- print("----- 正常图调用结果 -----")
- print(result)
-
- file_content = read_file('./image_advertise.jpeg')
- result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
- print("----- 广告图调用结果 -----")
- print(result)
-
- text = "我们要热爱祖国热爱党"
- result = request(text_url, urlencode({'text': text}))
- print("----- 正常文本调用结果 -----")
- print(result)
-
- text = "我要爆粗口啦:百度AI真他妈好用"
- result = request(text_url, urlencode({'text': text}))
- print("----- 粗俗文本调用结果 -----")
- print(result)
-

运行代码
在命令行中运行 python main.py
结果
若代码正确运行,命令行界面上会显示出运行结果:
- ----- 正常图调用结果 -----
- {"conclusion":"合规","log_id":15589290206915234,"conclusionType":1}
- ----- 广告图调用结果 -----
- {"conclusion":"不合规","log_id":15589290221307686,"data":[{"msg":"存在水印码内容","probability":0.86516607,"type":5}],"conclusionType":2}
- ----- 正常文本调用结果 -----
- {"conclusion":"合规","log_id":15589290234750607,"conclusionType":1}
- ----- 粗俗文本调用结果 -----
- {"conclusion":"疑似","log_id":15589290237990632,"data":[{"msg":"疑似存在文本色情不合规","conclusion":"疑似","hits":[{"probability":0.802,"datasetName":"百度默认文本反作弊库","words":[]}],"subType":2,"conclusionType":3,"type":12}],"conclusionType":3}
结果中返回了内容审核服务对于图片以及文本的审核结果,包括了概率以及不合规的类型。
点击内容审核技术文档,可以查询具体字段的详细释义。

