
- 17个非常流行的Python的可视化工具_python可视化编程工具
- 2计算机图像图形学相关好书推荐[转]_计算机图形学 推荐 教材
- 3Elasticsearch 搜索的过程?_elasticsearch 检索过程
- 4苹果MacOS电脑远程桌面本地局域网内Windows电脑操作流程_mac链接win远程桌面
- 5MySQL中的用户管理_mysql用户管理
- 62021最全最新Spring Boot面试题+答案(持续更新)_springboot入职测验题 无限极分类测验题
- 7OpenAI神秘項目「草莓」曝光!自我进化已超越人类智能?马斯克嘲讽:回形针灾难_self-taught reasoner
- 8前端-HTML基础知识详解_前端html
- 9[破解] DRM-内容数据版权加密保护技术学习(中):License预发放实现
- 10PRD文档范例,产品经理值得收藏的写作手册
自动驾驶合集25_自动驾驶的mfr是什么
赞
踩
# 小米智能驾驶技术的一些猜测
来蹭一下小米汽车智能驾驶的热度,昨晚听了雷总小米汽车的发布,心潮澎湃寻思下单一辆奈何现实不允许hhh。
言归正传吧, 本来是想主要听一下小米智驾的但雷总并没有透露太多。这次对于智驾方面的介绍其实和上次技术发布会上展出的内容差不多。听完之后我自己对于小米自动驾驶的技术点有一些疑问和猜测,写一写大家可以瞅一瞅交流一下。
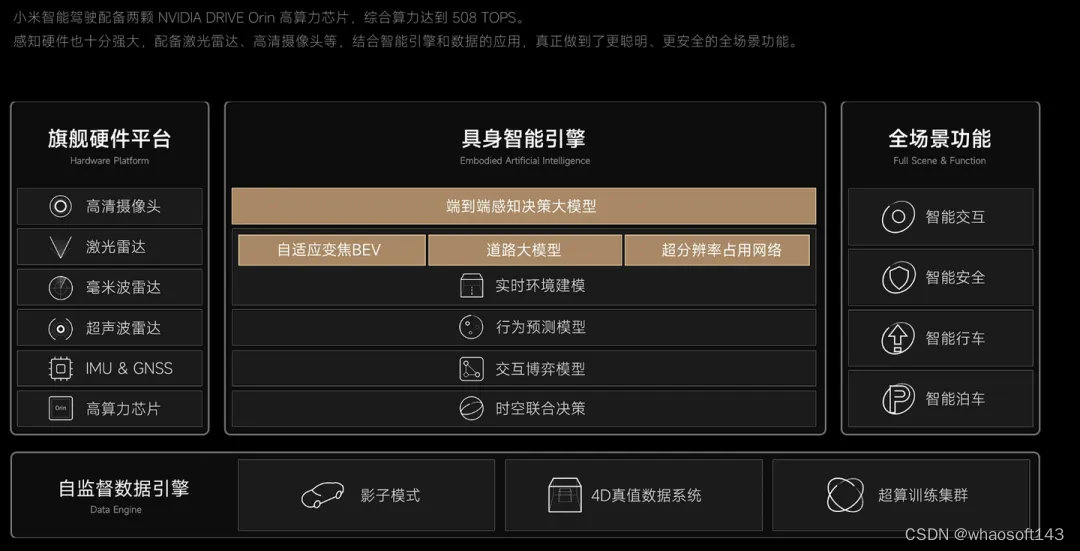
旗舰硬件平台之高算力芯片

首先没毛病,小米智能驾驶高配用的芯片是英伟达双Orin-X,综合算力508TOPS。低配版使用的是Orin-N,单芯片算力84TOPS。这里就解决了大家为什么会疑问84 X 2 是508。
这个算力已经可以算是在量产车上用的最高算力配置了,毕竟上了激光雷达,图像加激光来做模型对算力要求还是挺高的。orin芯片由于是英伟达产品这意味着在进行深度学习推理时候cuda支持的操作都可以使用,这对于车端部署神经网络模型非常友好。如果是其他芯片则会有多多少少的特定算子不支持的问题,增加工程量。以地平线J5开发平台为例,不支持的操作都得改代码,还存在其他限制。
另外大算力芯片带来的好处还有网络模型可以做的大一些,可以使用新的模型结构。如果你想在地平线J5平台上使用transformer,那基本就不要想着上车了,网络也就跑个几帧十几帧。所以小米造车使用orin还是很合理的,大算力宣传性价比,开发难度也小很多。旗舰硬件平台没啥毛病。
困惑之自监督数据引擎
接下来就是有困惑的地方,自监督数据引擎?这个自监督是如何定义的,如果按深度学习的定义自监督就是说我的训练数据是无标签的,那这个为什么还需要真值标注?如果你不是数据自监督是引擎自监督,那应该是整个数据处理的pipline是不需要人工来做全部自动化了,这我属实难以相信。车还没卖出去,影子模式还没回传数据,也就测试车自己采集点跑通整个流程,国内也没有一家敢斩钉截铁的说自己4d真值标注完全不靠人工,超算训练自动化不是不可以,但肯定也还是需要手动处理一些bug和调参。
也可能是我的问题,我只负责模型部分对前面的真值标注部分不熟悉,所以“自监督数据引擎”几个字凑在一起真的是很令人困惑啊!!!
重点具身智能引擎
下一个重点具身智能引擎,这个是说得通的,挺火的概念。环境感知,行为预测,交互博弈,时空联合,决策这些确实也都是模型可以做到的,把智能装在身体上可以和外界交互,具身智能就成了。
第一个点是变焦bev。
官网给了三个场景解释,分别是泊车,城区和高速。我们一般人困惑的第一个点就是为什么这个bev可变?按ppt的说法我理解是说在泊车场景的时候网络的划分会更细,分辨率会更高。我们都知道一般bev网络的输出分辨率是需要作为config在训练的时候给定的,怎么训的跑的时候就怎么跑,这个分辨率是给定的不能变。如果说你可以变,那config文件变了就意味着最起码神经网络后面的输出也要改变,网络是需要学习参数的。所以我猜测难道在是训的时候就有不同分辨率,只是根据场景切换了输出模型。(更容易一点也可能是好几个模型来回切,但应该不至于这么搞)至于有什么其他更妙的设计或许也有可能吧。如果这么来看那变焦bev似乎也没有很神秘,至于如何看的更宽更远我觉得也差不多同理,bev远范围的感知也有一些文章,一两百米的bev也能搞。当然最开始和同事讨论的时候我们也想过,难道是相机是可变焦距的?要是这样那还挺牛的。
不过这世界还是挺有趣的,很多事情的谜底往往就在谜面上。

猜来猜去猜了那么久,人家写的很清楚调用不用算法动态调整bev网格特征的细粒度和感知范围。那就是几个模型切换了。看来作为坚定的唯物主义者也需要对科技进行祛魅(disenchantment)。
至于自适应应该说的是算法可以根据场景切换。这三个场景简单点就是手动切,高级点是自动切。手动切就是说用户自己使用了什么功能,后台根据功能来切换模型;自动切是用网络去自己判断场景或者根据感知出来的结果来写一些规则,根据这个建筑车辆周围环境的特征去判断场景来切换,但无论如何也是我们大概可以猜到的,能猜到逻辑上能说通,那就是我们也可以去实现的功能。

第二个点是超分辨率占用网络技术。
对不熟悉这个方向的同学来说,一看看过去感觉挺高级的。但隔行如隔山,这个恰好我之前有了解过一些,不清楚小米是不是真的这样做的,但我猜测大概是这样八九不离十?给大家放几篇篇相关文章可以看一下,这个模拟连续曲面的立体物到底是什么情况。

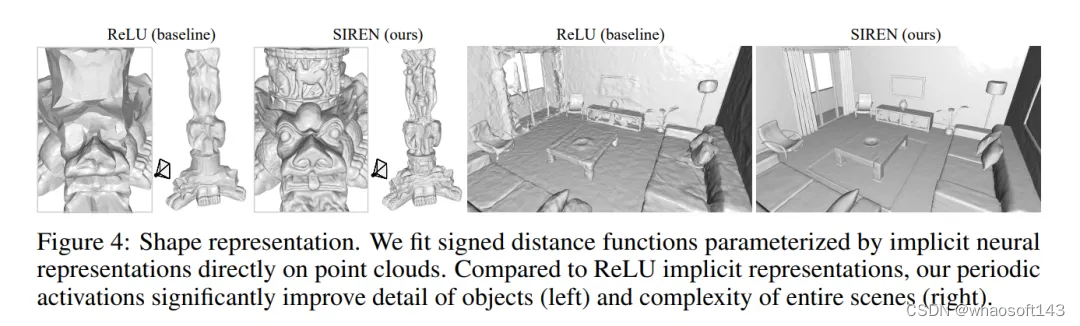
按顺序来的话,第一篇先放SIREN:Implicit Neural Representations with Periodic Activation Functions
arxiv.org/pdf/2006.09661.pdf
正弦表示网络(sinusoidal representation network:SIREN),用周期性的激活函数来作为隐式神经表达,用他来解决特定的Eikonal方程的边值问题,简单来说就是用来在点云上拟合隐式神经表达参数化的符号距离函数就可以产生下面的效果 whaosoft aiot http://143ai.com
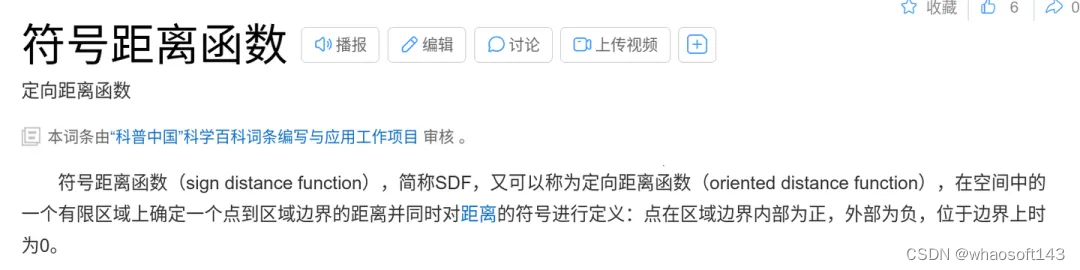
这里稍稍科普一下SDF,此外还有TSDF
另一篇是LODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR
arxiv.org/pdf/2302.14052.pdf
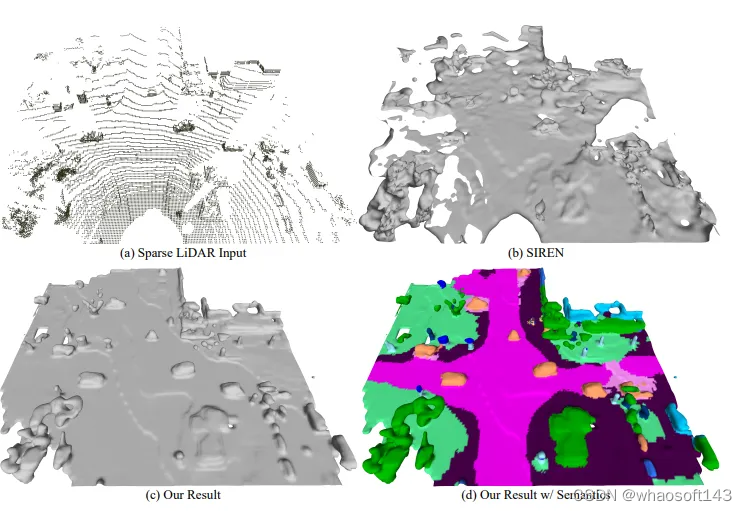
SIREN提出一种从点云到3D mesh补全方法,LODE提出了利用GT来监督SDF。
SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field
arxiv.org/pdf/2403.14366.pdf
这篇文章第一单位是xiaomi ev。后来居上的文章效果一般都不错,为什么会不错呢?具体来说,引入了一种基于查询的方法,并利用Eikonal公式约束的SDF来准确描述障碍物的表面。此外,考虑到缺乏精确的SDF基本事实,提出了一种新的SDF弱监督范式,称为Sandwich-Eikonal公式,它强调在表面两侧应用正确和密集的约束,从而提高表面的感知精度。实验表明,该方法在nu-Scenes数据集上实现了占用预测和3D场景重建任务的SOTA。这篇文章没有开源,但其实根据paper和上面两篇文章想要复现也不难,但我目前还是在做bev模型的检测分割所以暂时不会搞。
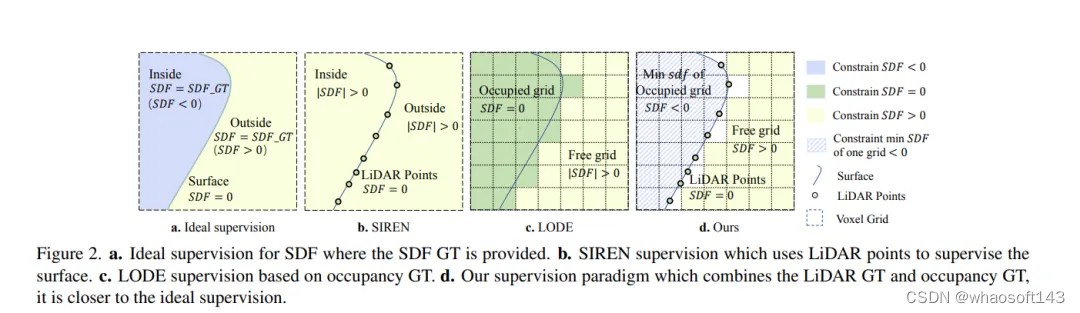
a.在提供SDF GT的情况下,对SDF进行理想的监督。b.SIREN监督,使用LIDAR点对表面进行监督。c.基于占用GT的LODE监管。d.我们的监管范式结合了LiDAR GT和占用GT,更接近理想的监管
这类任务都还是需要用激光做的真值。

然后就是识别异性障碍物种类无上限,我们做目标检测一般都给定类别,对于没见过的东西可能就胡乱给结果了,所以对于各种各样的异性障碍物训练集里面不会都有,那就需要给一个other类。又或者一些开集的检测把视觉语言一起训,用语言监督视觉也可以做到超类别的检测,这个文章就很多很多了。
第三个雨雪天自动降噪。

这个我就想的很简单,对输入的数据先过降噪算法再进网络。这类的算法就太多太多了,大家应该随处都可以找到。例如去arxiv网站上搜索rainy 或者snowy可以看到非常多的相关算法。
降噪可以单做,也可以嵌入网络,至于小米的智驾是如何做到的不是很清楚。难点在于降噪部分与后续环节的连接与耗时。
第四个小米道路大模型。
关于路网这部分这个我就不是很懂了,这部分目前是有其他同事在做。但也给大家一些我收藏的文章吧。下面链接里的文章不算全但也足够大家来理清脉络了,主要是新工作出来的太快了,像昊哥他们做的P-Mapnet之类。用神经网络去做道路结构的拓扑这部分我确实没搞过,但毕竟还是有大量文章可以参考!大家可以仔细研究一下
文章推荐地址如下:https://zhuanlan.zhihu.com/p/685111496

第五个端到端感知决策大模型。
这个我其实很感兴趣,把感知和决策一起做了,但目前还是只搞感知,老板不允许啊。我也不想说服他搞(已经放弃老板了)。好在小公司氛围比较轻松可以自己看看论文(已经看了快两年论文了,当然活也没落下该干的我都干了)。对于端到端的文章其实也不算少了,下面就简单给两篇文章参考吧
第一篇非常著名的cvpr的端到端:Planning-oriented Autonomous Driving
arxiv.org/pdf/2212.10156.pdf
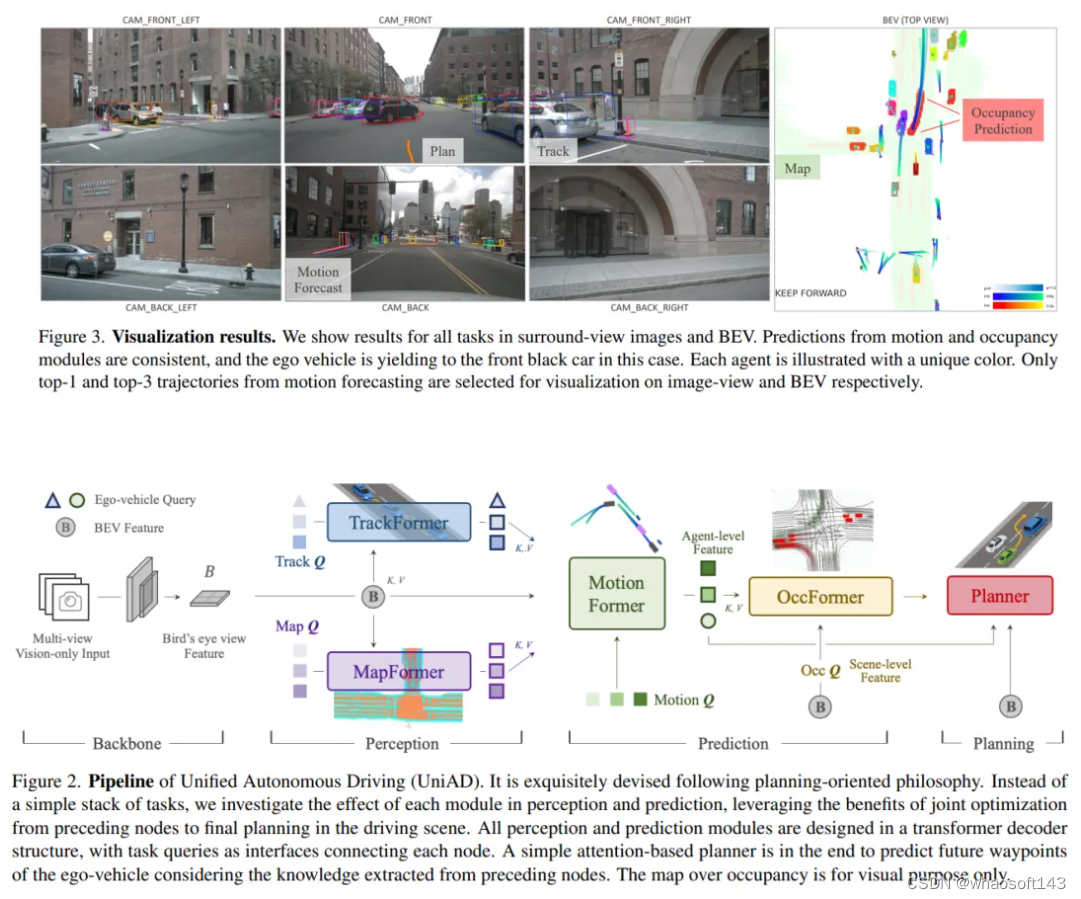
统一自动驾驶(Uni AD)管道。它是按照以规划为导向的理念精心设计的。与简单的任务堆栈不同,我们研究了每个模块在感知和预测方面的效果,利用了从前面节点到最终驾驶场景规划的联合优化的好处。所有感知和预测模块都采用变压器解码器结构设计,任务查询作为连接各个节点的接口。最后利用一个简单的基于注意力的规划器,结合所提取的知识来预测自驾车未来的路径点
大家看pipline也能看出来这个端到端其实是有很多组件构成,每个环节都通过任务查询来连接,前面的流程都是为了最后的规划而服务。
第二篇鉴智的端到端:GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
arxiv.org/pdf/2403.19098.pdf
 (这个看起来就很酷)
(这个看起来就很酷)
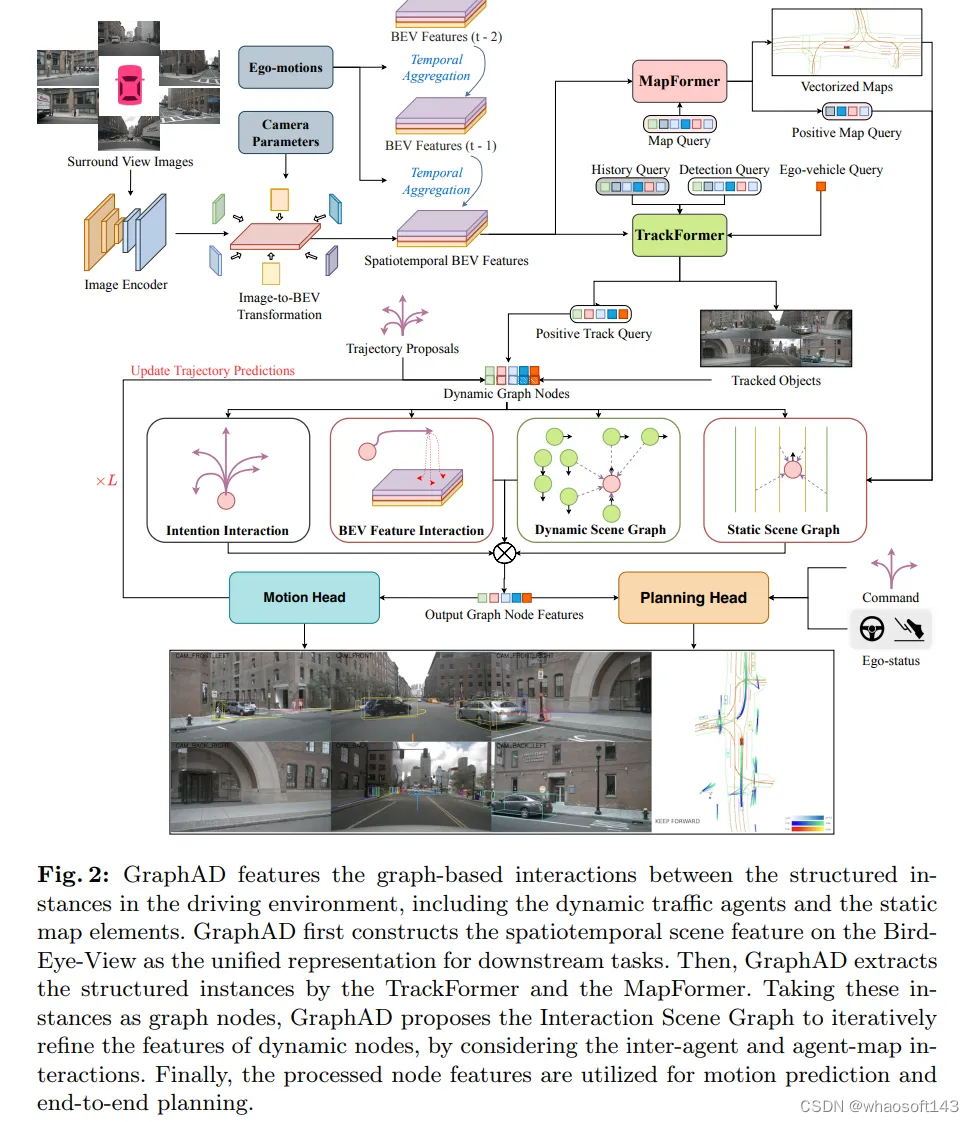
GraphAD的特点是驾驶环境中结构化实例之间基于图的交互,包括动态交通代理和静态地图元素。Graph AD首先在鸟瞰图上构建时空场景特征,作为下游任务的统一表示。然后,Graph AD通过Track Former和Map Former提取结构化实例。以这些实例为图节点,graph AD提出了交互场景图,通过考虑代理间和代理映射的交互,迭代细化动态节点的特征。最后,将处理后的节点特征用于运动预测和端到端规划。
GraphAD 的github可以看到Our code is based on UniAD and DGCNN,还是借鉴了UniAD的工作,用图的形式来做交互上的优化无疑是更好的。但代码目前还没有开源,大家可以mark一下。
先把端到端模型部署上车,再把这套东西装到机器人身上,这个才是我想做的,也是未来五到十年的人生目标吧。
给完文章再来看小米这个端到端感知决策大模型,感觉还是稳扎稳打的,先在泊车场景下验证端到端,后面在放到行车上。单从文章来看感知部分大家应该都很熟悉,但是决策部分给定的都比较简单,具体要量产控车,简单的左转右转直行停下肯定还是不够的,但老样子有文章的话就管中窥豹可见一斑。

全场景功能
全场景功能就交给广大网友和up主去测评了。
总结
不吹不黑,个人感觉小米的智驾水平还是可以的,有钱有人但还是需要时间来积淀。
目前发布出来的技术也不能说是多么遥不可及,我们都是技术的跟随者不是创新者,就上面这些东西只要有人做过我相信大家搭demo大家都可以做到,从0到60,但是真的能把任何一个技术从80做到90,甚至99都太难了,demo后面的每一步都难如登天。特斯拉已经把路给走通了,剩下的就看大家怎么搞了。加油!为了自动驾驶!冲!
# 自动驾驶中的坐标变换
对线性代数中的坐标变换、基变换两个概念的引入、性质进行了详细推导,并以自动驾驶中的传感器外参标定验证场景举例,介绍了坐标变换和基变换在实际工程中的应用,相信看完本文大家能对坐标变换和基变换有更深的理解。
默认读者具备基础的线性代数知识,包括基、线性组合、线性变换等概念。
应用背景

车辆系和相机系都是右手坐标系,一般情况下:车辆系的X轴指向车辆前方,Y轴指向车辆左方,Z轴指向天空;相机为前视相机,其坐标系为X轴指向车辆右方,Y轴指向地面,Z轴指向车辆前方。
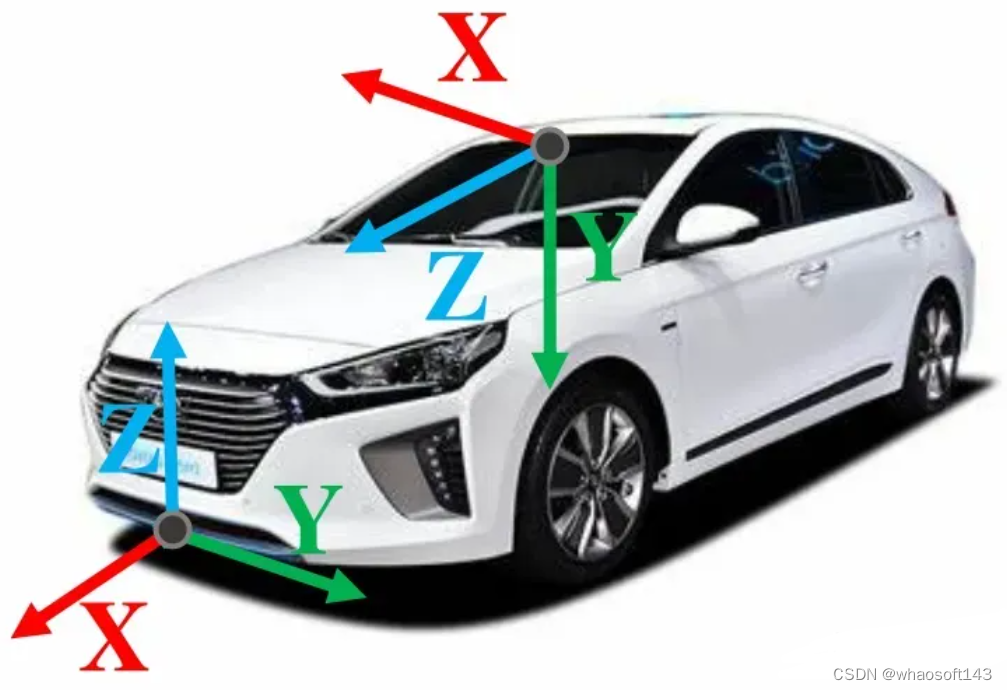
车辆坐标系和相机坐标系
为什么需要坐标转换矩阵 T 呢,假设我们在图像中检测到一个行人,此时我们可以通过相机内参并结合其他测距传感器,得出该行人在相机系下的位置,但我们并不知道这个人距离车辆有多远,在车辆的正前方还是左前方。因此就需要一个坐标转换矩阵,将相机系下的三维点转换到车辆系下,供下游任务使用。
问题引入

实验验证
为了实验能更加直观和真实,我们先做出如下设置:
-
车辆坐标系原点设置在车辆前保险杠的中心处,车辆系的X轴指向车辆正前方,Y轴指向车辆正左方,Z轴指向天空;
-
将相机系原点设置在挡风玻璃后的上方处,相机系的X轴指向车辆正右方,Y轴指向地面,Z轴指向车辆正前方,相对于车辆坐标系的原点,相机系原点相对于相机系X、Y、Z方向上的平移分别为-1.25、0.1、0.65,直观理解为相机位于车辆前保险杠的后上方,并且偏左一点点;
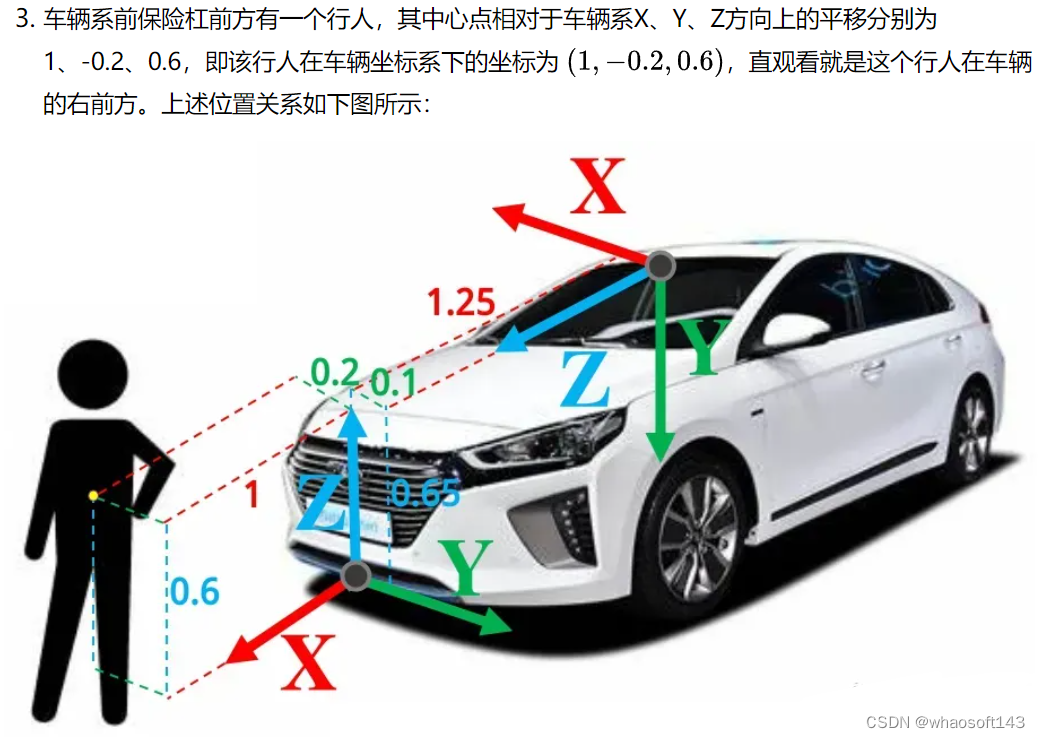
车辆、相机与人的位置关系

- #include <eigen3/Eigen/Core>
-
- int main(){
- float pi = 3.14159265358979;
- Eigen::Matrix3f R_inv;
- R_inv << 0, 0, 1, -1, 0, 0, 0, -1, 0;
- Eigen::Vector3f euler_angle = R_inv.eulerAngles(0, 1, 2); // 0: X轴,1: Y轴,2: Z轴,前后顺序代表旋转顺序,旋转方式为内旋
- std::cout << "先绕X轴旋转: " << euler_angle[0] * 180 / pi <<std::endl;
- std::cout << "再绕Y轴旋转: " << euler_angle[1] * 180 / pi << std::endl;
- std::cout << "最后绕Z轴旋转: " << euler_angle[2] * 180 / pi << std::endl;
- }
-
- // Console Output:
- // 先绕X轴旋转: -0
- // 再绕Y轴旋转: 90
- // 最后绕Z轴旋转: -90

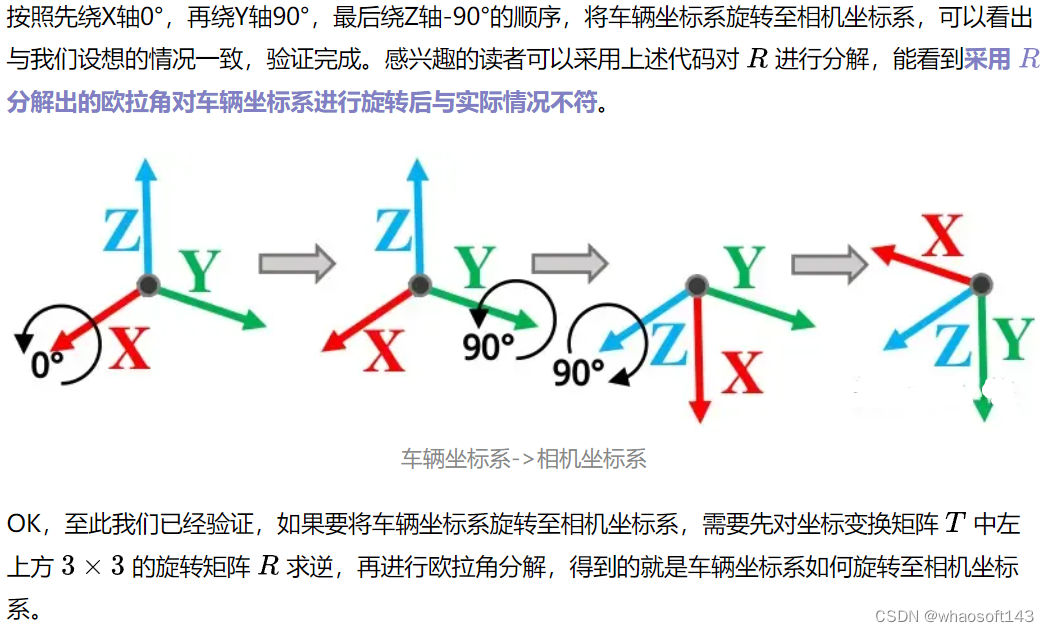

我们接下来采用线性代数,来分析为什么坐标变换矩阵和基变换矩阵刚好就是互为逆的关系。
线性代数解释(坐标变换和基变换的本质)

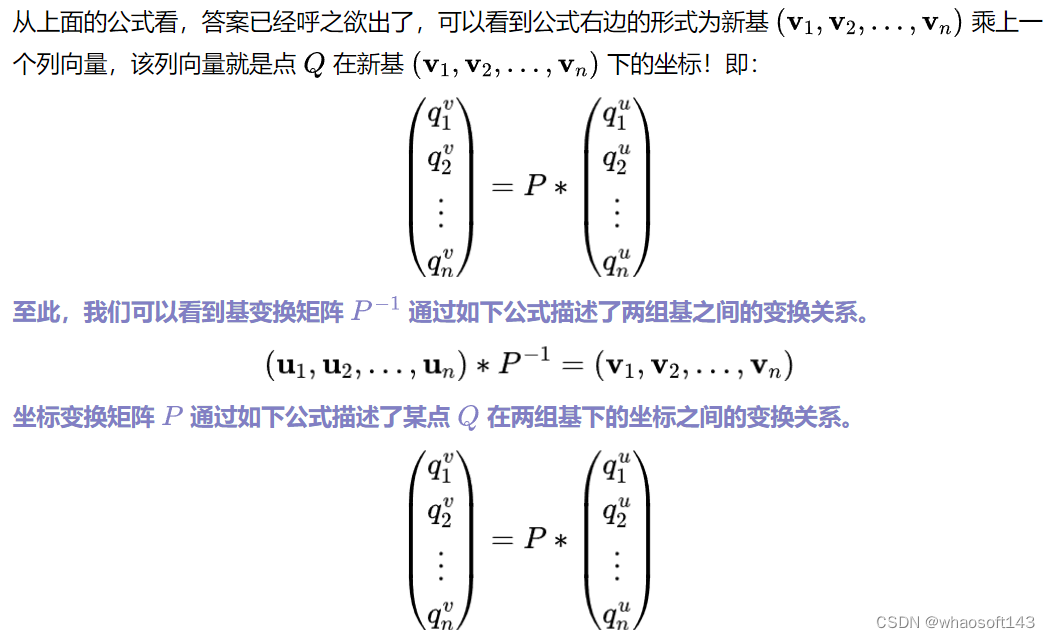
基变换矩阵和坐标变换矩阵互为逆,推导完毕。
总结
基变换矩阵和坐标变换矩阵的关系之前也在矩阵论这门课中接触过,但当时完全不了解其应用场景,也对为什么这么取名一知半解。直到在实际应用中碰到了这个问题,才发现简简单单的两个公式,在使用时必须根据应用场景对齐进行区分,来选择究竟使用基变换矩阵还是坐标变换矩阵。
# 车道线检测任务
Implementing lane detection is the first, essential task when building a self-driving car.
—— Sebastian Thrun (godfather of self-driving cars)
在自动驾驶和智能交通系统的发展中,车道线检测作为其中至关重要的一环,扮演着无可替代的角色。车道线不仅是道路交通标记的重要组成部分,更是车辆导航、路径规划和环境感知的基础。因此,准确、稳定的车道线检测系统对于实现安全、高效的智能交通至关重要。
随着深度学习技术的飞速发展,车道线检测技术已经取得了显著的进步。传统的基于图像处理和机器学习的方法逐渐被基于深度学习的端到端模型所取代,使得车道线检测系统在准确性和鲁棒性上都得到了显著提升。
笔者正是从事相关领域的研究和工作,创作这篇文章,主要是想对车道线检测这一细分任务的方法进行一个总结归纳,并且谈谈自己的理解。全文将从传统的检测方法聊到基于深度学习的一些方法,再谈到BEV视角下的检测,最后聊一聊关于大一统的检测方法。可以说是讲述了车道线检测任务的"前世今生",故起了这样一个标题。以下是本文的结构框架:
传统方法
先简单聊聊几个主流的传统车道线检测的方法,主要还是借助于opencv和一些算法来实现:
-
颜色阈值:如果只是检测简单的黄色和白色车道线,我们可以用这种方法来实现。把一般常见的RGB通道的图片转化到HSV或者HSL的颜色特征,然后人工设置一个黄色阈值和白色阈值,就能检测出来图像中黄色和白色车道线的位置。
-
边缘检测+霍夫变换:灰度图像-->高斯平滑(把图片变模糊,下一步边缘检测就会滤掉一些不重要的线条)-->边缘检测(检测出图像中边缘的点)-->选择ROI(可以选出路面区域)-->霍夫变换(获得车道线的直线参数)-->投影到原图上。
PS:说说笔者对霍夫变换的理解:将一条直线转换到表征直线的参数空间(可以用斜率m和截距b表征一条直线,那么霍夫空间就是m和b的函数,极坐标表示也类似)。所以经过笛卡尔坐标系下的一个点,可以有无数条直线,即可以有无数种m和b的对应关系,在霍夫空间中,则对应着一条直线。图片上通过边缘检测可以离散得到N个点,而对应的霍夫空间可以表示成N条直线,这N条直线的交点,对应的m和b,即为我们所想要检测的车道线。 -
基于拟合的检测: 利用RANSAC等算法拟合车道线。
优点:不需要数据积累
缺点:鲁棒性较差;需要人工手动调参;霍夫变换不能做弯道检测;拟合的方法稳定性较差。
虽然我们要肯定前人的成果,但是不得不说,传统的车道线检测方法需要人工手动地去调整算子和阈值,不仅工作量大且而且鲁棒性也较差,在复杂的环境下,检测结果就不够理想。
基于深度学习方法
与传统的检测算法相比,基于深度学习的车道线检测因其过硬的“实力”,越来越被学术界重视和也被工业界广泛应用:无需手动设计特征提取规则、泛化能力强、适应性强、准确性高。主流的方法分为三种:基于分割的方案(segmentation-based),基于锚的方法(anchor-based),基于参数的方法(parameter-based)。
基于分割的方法(segmentation-based)
顾名思义,把车道线检测的任务当成分割任务来做,通过模型得到图片中哪些pixels属于车道线,哪些不是,并且知道哪些pixels是属于同一条车道线,所以,这其实是一个实例分割(instance segmentation)的任务。
提到这类方法,不得不提它的开山之作——LaneNet!
论文地址:https://arxiv.org/pdf/1802.05591.pdf
github地址:https://github.com/MaybeShewill-CV/lanenet-lane-detection
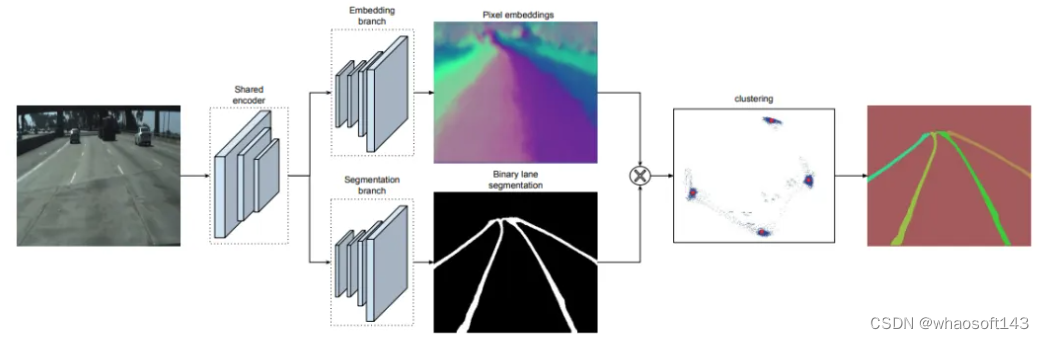
作者用用共享的Encoder模型,设计了两个Decoder分支:车道线分割分支和车道embedding分支。前者对像素进行二分类,输出哪些pixels是车道线,哪些是背景,使用标准的交叉熵损失函数;后者输出不同的车道实例,每个pixel初始化一个embedding,通过loss的设计,使得属于同一车道的embedding距离尽可能小,属于不同车道的embedding距离尽可能大。

得到不同车道的embedding之后,可以通过任意聚类算法来完成实例分割,论文中基于mean-shift来实现的。LaneNet的输出是每条车道线的像素集合,但还需要通过回归来得到完整的车道线。传统方法通常将图像投影到鸟瞰图中,然后使用2阶或3阶多项式进行拟合。然而,这种方法存在一个问题,即变换矩阵H只被计算一次,所有图像都使用相同的变换矩阵,这可能导致在地形变化(如山地或丘陵)的情况下产生误差。为了解决这个问题,论文又设计了一个H-Net网络,它能够训练出能够预测变换矩阵H的模型,其实就是6个参数。H-Net的输入是图像数据,输出是变换矩阵H。通过这个设计,模型能够根据不同的场景和视角,灵活地调整变换矩阵H,从而更好地适应不同地形和环境下的车道线检测任务。
LaneNet算是基于分割的车道线方法的先驱之作,但是除此之外,仍然有效果更棒的文章,比如:
-
SCNN(论文地址:https://arxiv.org/pdf/1712.06080.pdf)的作者就发现,只用简单的CNN来检测车道线,无法提取pixels之间的空间关系,所以会出现当车道线被遮挡时无法被连续识别的问题。于是提出使用空间CNN(spatial CNN)的方法,来增强pixels之间横纵方向的信息传递,从而提高车道线检测的连续性。
-
RESA(论文地址: https://arxiv.org/pdf/2008.13719.pdf)的作者为了提取车道线丰富的空间特征,设计了一个REcurrent Feature-Shift Aggregator模块,利用切片特征图的垂直和水平移动来直接信息聚合。
基于锚的方法 (anchor-based)
Anchor这个词翻译成中文叫“锚”,一直让很多CV新人很不解,其实简单的理解就是“预设的参照”。目标检测任务中,模型对“在哪里有什么目标”不太清楚,所以我们会在图像上预先设计好不同大小,不同长宽比的锚框(anchor boxes),任务即变成“在这个锚框中有没有目标,离得有多远”。那么在车道“线”检测的任务中,预设“框”似乎有点不太合适了,而是要设计“锚线”(anchor lines)。
LineCNN的作者就是受到Faster-RCNN的启发,提出了line proposal (LP),其实就是 anchor lines。因为车道线起始点一般都是图像的左、下、右边向外延伸。所以作者的LP都是从特征图上的这三边上的每个点,沿不同的角度,来生成的。每个LP用一个长度为77的向量表示,[负样本的概率, 正样本的概率, 起始坐标y, 起始坐标x, 车道线长度, 72个偏移量]。作者也设计了一款距离,用来计算车道线和LP之间的距离。
该类别的方法下,还有一个非常经典的模型——LaneATT。
论文地址:https://arxiv.org/pdf/2010.12035.pdf
代码链接:https://github.com/lucastabelini/LaneATT
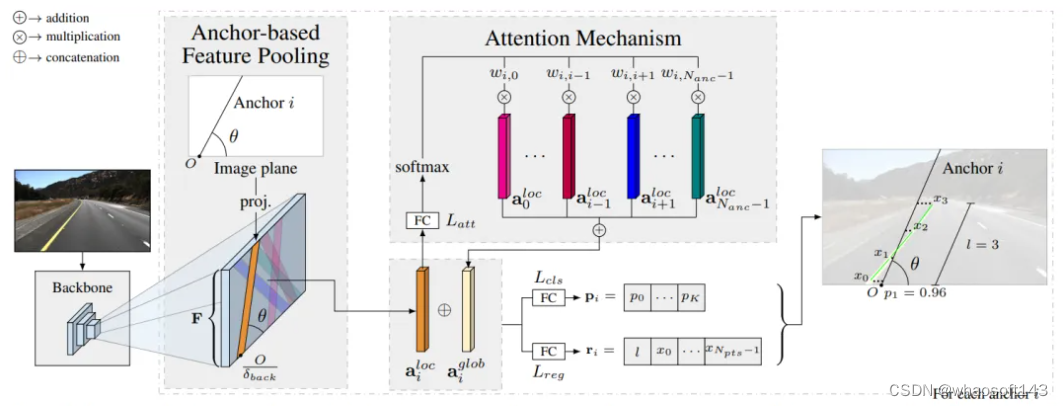
先用CNN提取特征,然后根据 anchor lines的x和y的坐标,在特征图上挑出固定长度的特征,得到 ailoc,但是这个特征也只是局部特征,如果遇到车道线被遮挡的情况,还需要融合全局的特征来进行预测。所以,作者提出了一个注意力机制,用来获取全局特征aiglob。融合后的特征,用于两个预测分支:分类分支用来预测类别(k个类别车道线和1个背景类别);回归分支基于anchor的起始点s,预测出线的长度L, 以及N个点的坐标与anchor的偏移。
上述两个方法都是从图像的左下右三个边为起始点,去预设anchor lines,但是有的数据,可能因为车前盖的影响,车道线并非从这三边出发。基于此,ADNet(https://arxiv.org/pdf/2308.10481.pdf)的作者就将anchor分解为学习起点和相关方向的heatmap,消除了预设的anchor lines起始点的限制。并提出来大核注意力模块LKA,目的是提高生成anchor的质量,增加感受野。
当然,基于anchor的车道线检测方案,不仅仅局限于anchor lines, 还有一些其它的思路,比如:CondLaneNet (https://arxiv.org/pdf/2105.05003.pdf)就是利用一个 proposal head(作用有点类似Faster-RCNN中的Region Proposal Network),预测车道线起始点的heatmap,然后会对于特征图中的每一行,车道线的点在每一行的位置,和在纵向的pixel会被预测出来,再通过预测一个offset,来得到车道线的点。
基于参数的方法(parameter-based)
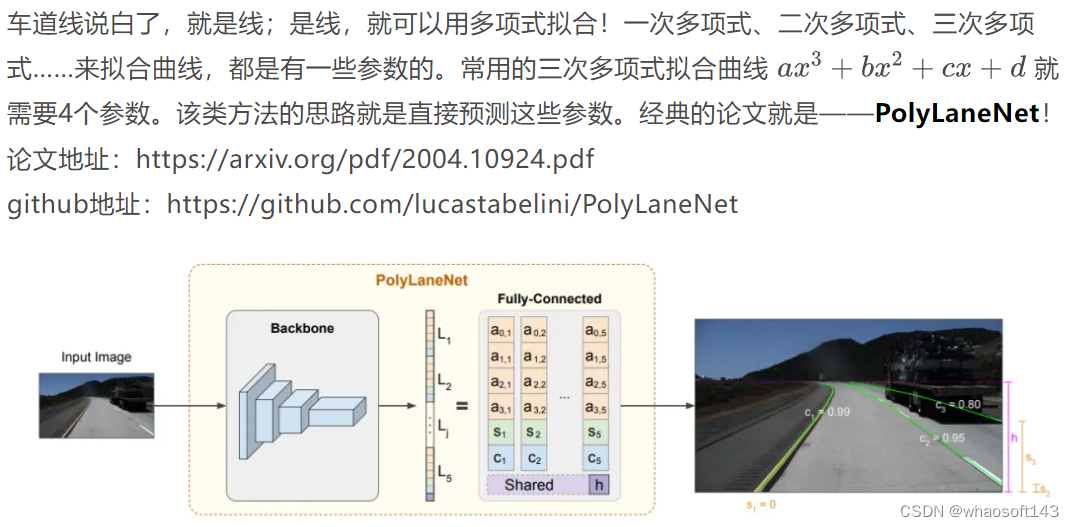
作者设计了多项式曲线回归(deep polynomial regression),输出表示图像中每个车道线的多项式。好处是可以学习整体车道表示,推理速度较快,但实际上这种方法在准确度上并不高。
BEV视角下车道线检测
近几年,BEV视角下的视角感知,一直发展迅速,各家公司都有自己的BEV方案。传统的方案,就是通过多视角的相机参数标定,得到相机平面与地面的单应性矩阵,利用逆透视变换(IPM),实现从相机平面到大地平面的转换,再把多视角的图片拼接。但是这样的方法最大的问题就是需要假设地面是平坦的,这在泊车场景下,应用的比较多,但是在开放路段,对于路面不平或者稍微远距离一些的检测任务中,就有些吃力了。所以大部分的方案,都还是基于深度学习的方法来做的。笔者没有把这部分方法归到上面的类别中,主要是因为这部分近几年比较火热,思路也与之不同。
目前比较主流的方法大体可以分为以下两种:
-
显式估计图像的深度信息,完成BEV视角的构建,e.g., LSS;
-
与transformer结合,利用BEV Query查询构建BEV特征, e.g., BEVformer;
-
作为 HD map构建的一个子任务,e.g., MapTR。
先来讲讲BEV的开山之作——Lift,Splat,Shoot(LSS)。
论文链接:https://arxiv.org/pdf/2008.05711.pdf
github链接:https://github.com/nv-tlabs/lift-splat-shoot
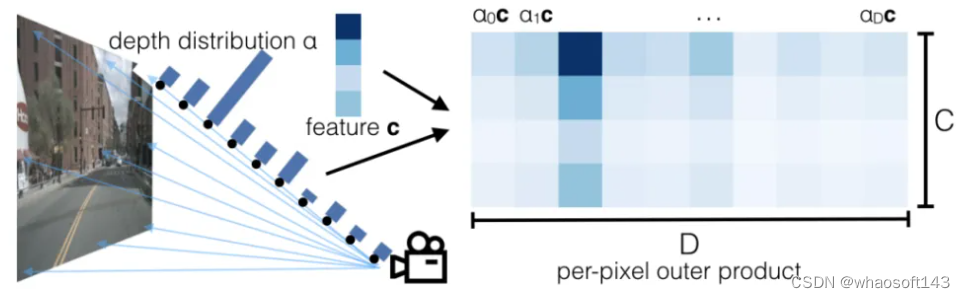
主要分为以下几步:
第一步:生成视锥,得到的是从特征图上的点,与原图上的点的映射,并根据相机内外参将视锥中的点投影到车身坐标系中;
第二步:提取图像特征,利用深度概率密度和语义信息构建图像特征点云;
第三步:将第一步得到的车身坐标系下的点与图像特征点云利用Voxel Pooling,压平构建BEV特征;
第四步:对生成的BEV features利用ResNet-18进行多尺度特征提取,再进一步的特征融合;
第五步:利用特征融合后的BEV特征完成车道线语义分割任务,做交叉熵损失;
当然,基于LSS的很多变式都有不错的效果,但是这种范式对深度的分布非常敏感,于是另一种思路诞生了,让模型自己学习如何将图像的特征转化到BEV空间,来实现车道线检测和目标检测等任务。BEVFormer,即是如此。
论文链接:https://arxiv.org/pdf/2203.17270.pdf
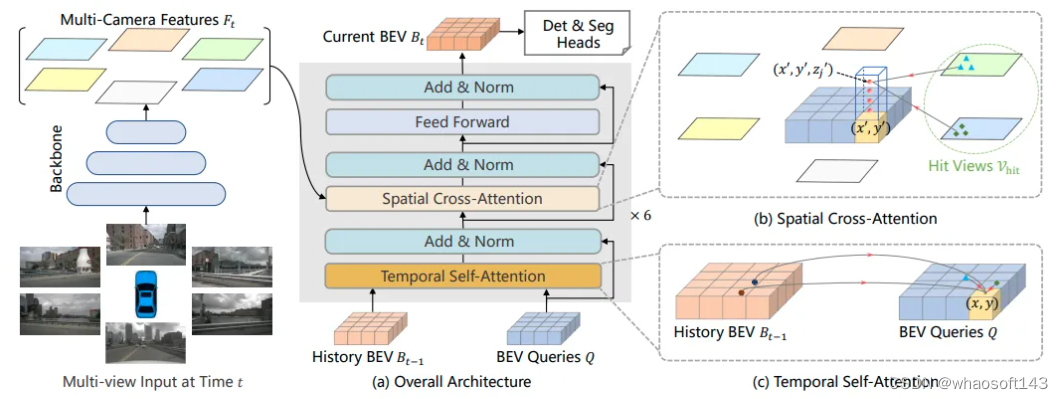
BEVFormer最吸引人的地方就是Encoder layers的设计,包含:BEV Queries, Spatial cross-attention 和Temporal self-attention。BEV Queries可以理解为可学习参数,通过attention机制在多视角图像中查询特征。Spatial cross-attention以BEV Queries作为输入的注意力层,负责获取来自多视角的特征;Temporal self-attention则是负责聚合时间维度上特征,指来自上一帧的BEV特征。
第三个部分聊一聊 HD map。传统的SLAM离线建图,成本比较昂贵,流程也比较复杂,行业里大家都在做无图NOA,但是map的信息对自动驾驶的规划及其重要的,所以,在线构建地图信息,也得到越来越多的关注,车道线、斑马线、道路路沿等等。而车道线检测可以认为是map构建的一个子任务,这也是笔者想在这里提一下的原因。MapTR 就是一种高效在线矢量化地图构建的方法。
论文链接:https://arxiv.org/pdf/2208.14437.pdf
github链接:https://github.com/hustvl/MapTR
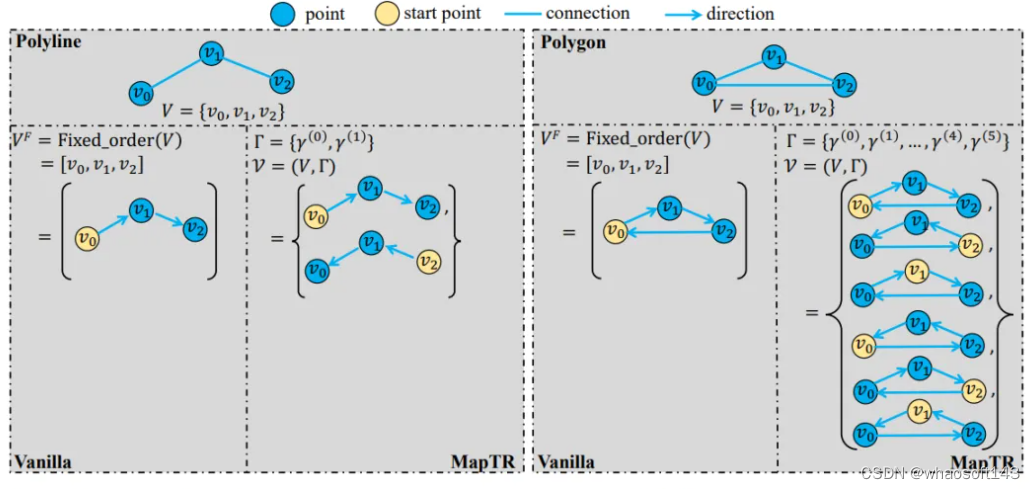

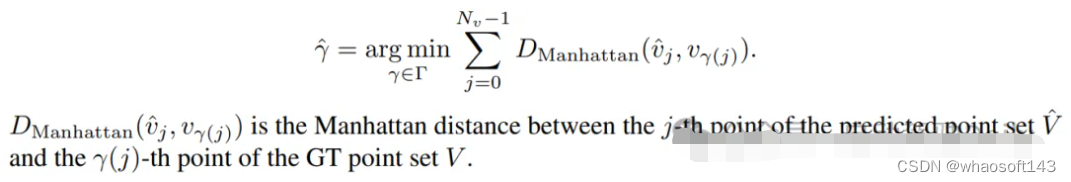
训练时的损失函数也是基于这两种分配,设计出了三个部分:classfication loss(监督地图元素类别)、point2point loss(监督每一个预测点的位置)、edge direction loss(监督相邻两点连线的方向)。
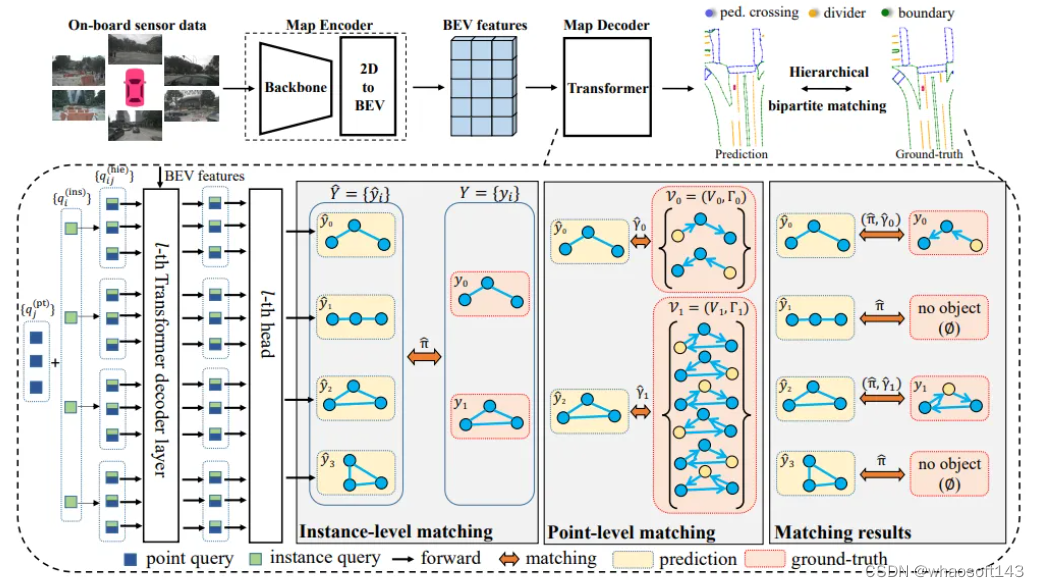
大一统方法
笔者前几天闲逛看到了一篇很有趣的论文(CVPR2024):Lane2Seq
论文链接:https://arxiv.org/pdf/2402.17172.pdf
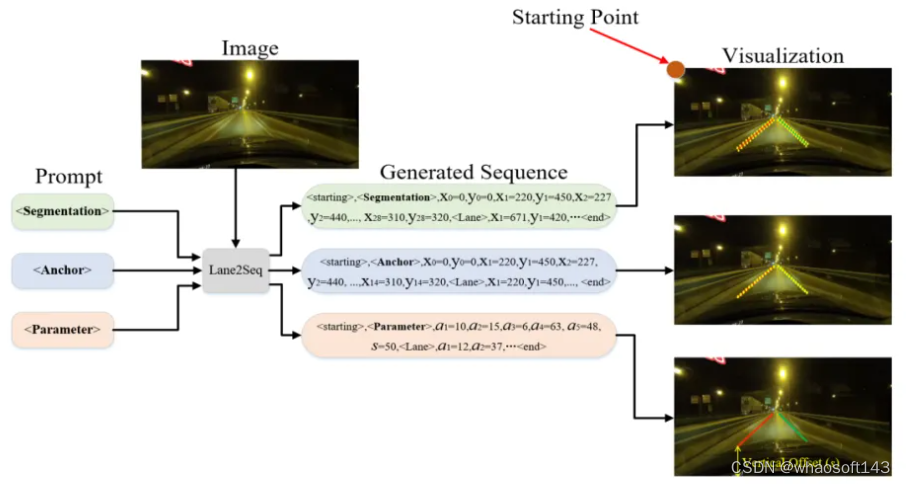
上面提到的多个车道线检测的方法类别:segmentation-based, anchor-based, parameter-based, 但是Lane2Seq的作者,觉得这太麻烦了,要精心设计的特定于任务的头部网络和相应的损失函数。基于此,他把通过将车道检测作为序列生成任务来统一各种车道检测格式 Lane2Seq仅采用简单的基于Encoder-Decoder的Transformer架构,具有简单的交叉熵损失。
对于Segmentation序列,并不是作pixel-wise的学习,而是作为多边形(polygon)来学习,一个polygon的序列可以被表示成 [x1, y1, x2, y2, ..., x28, y28,<Lane>], 这里的 <Lane> 是一个类别的token;对于Anchor序列,会作为关键点(keypoint)的学习,一个keypoint序列可以表达成[x1, y1, x2, y2, ..., x14, y14,<Lane>];而对于Paramter序列,比如一个parameter序列可以被表示成 [a1, a2, a3, a4, a5, s, <Lane>], 这里的s是一个纵向的offset。
虽然说, Lane2Seq 不包含特定于任务的组件(指的是segmentation, anchor, parameter),但这些组件中包含的特定于任务的知识可以帮助模型更好地学习车道的特征。所以,作者提出了一种基于强化学习 (MFRL) 的多格式模型调整方法,将特定于任务的知识融入模型中,而无需改变模型的架构。受到 Task-Reward 的启发,MFRL 将整合特定于任务的知识的评估指标作为奖励,并使用 REINFORCE 算法来调整 Lane2Seq。作者也根据任务特定知识,为分割、锚点和参数格式提出了三种新的基于评估指标的奖励。
# 国内首套全栈端到端自动驾驶系统开放道路测试
近日,清华大学车辆与运载学院李克强院士、李升波教授领导的研究团队,完成了国内首套全栈式端到端自动驾驶系统的开放道路测试。依托车路云一体化智能网联驾驶架构,该团队研发的端到端自动驾驶系统,涵盖了“感知-预测-决策-规划-控制”等全链路环节,从今年1月份率先启动了城市工况的开放道路验证,经过近4个月的内部测试,完成了各项性能的综合评估。这一工作为L3级及以上高级别自动驾驶系统的落地应用奠定了坚实的基础。
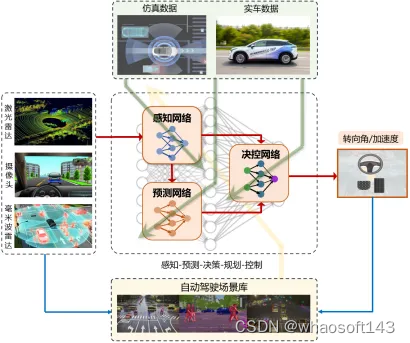
从感知到控制的全链路端到端自动驾驶系统(原理图)
目前,处于L1、L2级智能驾驶系统主要依赖“模块分解”的设计思路,尽管部分模块(如感知、预测等)已经初步神经网络化,但是决策、规划、控制等模块仍然严重依赖人工规则和在线优化,缺乏利用数据进行闭环迭代的能力,这导致行车过程的智能性仍然不足。同时,模块间不可避免地存在较大信息损失,且各模块的优化目标存在一定冲突,不利于自动驾驶过程的综合性能提升。与之相比,以全模块神经网络化为特征的“端到端”自动驾驶系统,因模块与模块之间的信息传递可依赖高维度特征向量,且神经网络具有充分的训练自由度,最大程度地减少了传感器到执行器之间的信息损失,使得全栈模块具备利用数据闭环进行快速更新的能力,这为高级别自动驾驶的智能性提升提供一条全新的技术路径。
面向这一技术发展趋势,李克强院士、李升波教授领导的研究团队自2018年开始瞄准端到端自动驾驶领域进行深耕,重点突破决策、规划与控制领域的神经网络设计与训练难题。团队先后提出了面向高级别自动驾驶的集成式决控(IDC)开发框架,研发了综合性能国际领先的数据驱动强化学习算法(DSAC),首创了时空分离的交通参与者行为预测模型(SEPT),设计了具有动作平滑特性的控制型神经网络架构(LipsNet),开发了自主知识产权的最优控制策略近似求解器(GOPS),以蚂蚁搬家的精神逐一解决了端到端自动驾驶面临的一系列核心难题。以此为基础,今年年初团队成功研制了首个从传感器原始数据到执行器控制指令的全栈神经网络化自动驾驶系统,并率先完成了城市工况开放道路的实车测试验证。
这一研究工作同时得到智行者、昇启科技两家高科技企业的全力支持,形成了校企之间紧密配合、通力协作的联合攻关团队。智行者团队主要工作在于环境感知模型的构建与预训练,昇启科技团队主要工作在于自动驾驶仿真平台的开发,三家单位共同完成了系统功能集成、性能评估迭代等后期任务。该研究获得国家“十四五”重点研发计划、国家自然科学基金以及清华大学自主科研计划支持。

