
- 1Scrcpy:使用PC操控手机教程_scrcpy不能用鼠标控制
- 2智慧仓库:EasyCVR视频监控汇聚+AI视频分析技术在仓库安全管理中的应用
- 3使用PyTorch实现的DeepSpeech模型: 强大的语音识别利器
- 4地铁框架保护的原理_地铁施工方法汇总
- 5嫁给年薪百万的程序员,结婚 6 年后的我竟然还是处女
- 6【云原生监控】Prometheus 普罗米修斯从搭建到使用详解_prometheus2.53部署
- 7基于术语词典干预的机器翻译挑战赛算法 --task01 #Datawhale AI夏令营
- 8CV技术指南 | 其实Mamba是一种线性注意力?清华大学黄高团队揭秘开视觉Mamba的真实面目!_mamba论文精度
- 9Hive 查看和修改 tez 容器的资源_tez怎么查看任务读取的数据量·
- 10【消息队列】03 消息队列是如何确保消息不丢失的_消息队列如何保证消息不丢失
python机器学习 | 朴素贝叶斯算法介绍及实现_本章实验主要包含基于python的朴素贝叶斯算法及调用。实验当中除了使用朴素贝叶斯
赞
踩
周末去长沙玩了一趟,在长沙呆了四年,然后就像真游客一样去爬了岳麓山和逛了橘子洲头,哈哈,和亲近的人一起玩闹的体验很舒服,很庆幸和感恩有那么一群人宠着你~~
当然,游乐之余,我也不忘学习的,在回来的高铁上,学了一下朴素贝叶斯算法,这是机器学习里面的经典的分类算法,也是为数不多的基于概率论的分类算法。
学习:
1 贝叶斯定理介绍
1.1 贝叶斯介绍
- 贝叶斯介绍: 托马斯·贝叶斯Thomas Bayes(1702-1763)在世时,并不为当时的人们所熟知,很少发表论文或出版著作,与当时学术界的人沟通交流也很少,应该算是一名业余的数学家,但研究出了贝叶斯统计学,发表出了An essay towards solving a problem in the doctrine of chances(机遇理论中一个问题的解)。在发表之际,并没有受到诸多关注,但到20世纪中叶,经典统计遭遇了一些困难,而使得贝叶斯统计得以广泛使用。

那么经典统计学遇到什么困难呢,而贝叶斯统计学又能够广泛应用呢。我们先整体了解一下经典统计学的思想和贝叶斯统计学的思想。
1.2 经典统计学和贝叶斯统计学简单介绍
- 经典统计学:基于抽样信息(抽样信息 = 总体信息 + 样本信息)进行统计推断的理论与方法称为经典统计学。
其中,总体信息为当前总体样本符合某种分布。比如抛硬币符合二项分布,学生身高符合正态分布。样本信息为通过抽样得到的部分样本的某种分布。
总结:经典统计学(频率派)把需要推断的参数θ看做是固定的未知常数,即概率θ虽然是未知的,但最起码是确定的一个值,同时,样本X 是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X 的分布;
- 贝叶斯统计学:基于总体信息+样本信息+先验信息进行统计推断的方法和理论,称为贝叶斯统计学。
其中,先验信息为抽样之前,有关推断问题中未知参数的一些信息,通常来自于经验或历史资料。
总结:贝叶斯派认为参数θ是随机变量,而样本X 是固定的,由于样本是固定的,所以他们重点研究的是参数θ的分布。
举个例子:

现在有一杯啤的、一杯白的,让10位同学蒙着眼睛去品酒,那大家实际上都能分辨出来。如果每位同学都是猜测结果,那最终的概率应该为0.5**10,这个结果非常小。
但实际上,基本上每位同学都可以进行分辨,所以不能认为这个结果是猜测而来。而应该是根据往常的经验来得出的结果。而这个经验本身,实际上就是我们的先验信息。
这种思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对的认知是先验分布 π(θ),在得到新的样本信息后χ,人们对θ的认知为π(θ|x)。基于这种思维模式,贝叶斯定理也就容易理解了。
1.3 贝叶斯定理
先学习或者复习几个定义,在概率论学习中,应该有过接触:
- 先验概率:prior probability,是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现的概率。某个事件发生的概率。
来源于: 百度百科-先验概率 - 条件概率(又称后验概率):事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”。
来源于:百度百科-条件概率 - 联合概率:表示两个事件共同发生的概率。A与B的联合概率表示为 P(AB) 或者P(A,B),或者P(A∩B)。
来源于:百度百科-联合概率
4.全概率公式:若事件A1,A2,…构成一个完备事件组且都有正概率,则对任意一个事件B,有如下公式成立:
P(B)=P(BA1)+P(BA2)+…+P(BAn)=P(B|A1)P(A1) + P(B|A2)P(A2) + … + P(B|An)P(An).此公式即为全概率公式。
来源于:百度百科-全概率公式

那么有了上述概念后,我们就来介绍贝叶斯定理吧。贝叶斯定理告诉我们如何交换条件概率中的条件与结果。比如,我们已知P(B|A),需要求解P(A|B)。

由此得到公式:
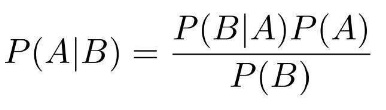
这里有个最经典的例子,n个箱子,去进行摸球。求B的概率则用全概,求A则用贝叶斯。

由此,我们可以发现贝叶斯就是为了解决“逆概率”而提出的,逆概率的意思就如同:我们从袋子里摸球,然后事先并不知道袋子里面黑白球的比例,我们需要知道这个袋子里的黑白球比例。那么我们只能通过摸出一个或者好几个球,观察这些取出来的球的颜色之后,然后反推判断袋子里的的黑白球的比例。
为了便于记住公式,我们也可以把摸出的球作为现象,需要了解里面的球的比例作为规律,把贝叶斯公式简单记为:

- 公式如何使用,举个栗子:
总共100封邮件,其中正常的邮件有70封,而垃圾邮件有30封。“兼职”这个词在正常邮件中出现共10次,在垃圾邮件中出现了共20次。
那我们现在需要求解:包含“兼职”这个词的邮件属于垃圾邮件的概率是多少?
包含“兼职”这个词的邮件是现象(P(现象)的概率为3/10),属于垃圾邮件是规律(P(规律)的概率为3/10),p(现象/规律)= 2/3
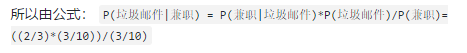
2 朴素贝叶斯算法介绍
2.1 基本介绍
然而贝叶斯定理也存在一些小问题,如承接上面邮件,我们要选出带有房地产、产权和贷款词眼的邮件

假设统计结果如下:
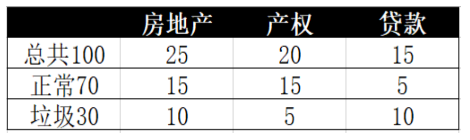
此时,每个特征之间是有关联的,那我们需要来计算如下:
- 房地产对垃圾邮件的影响程度。
- 房地产+产权对垃圾邮件的影响程度。
- 房地产+产权+贷款对垃圾邮件的影响程度。
公式演变如下:
P(房地产|垃圾邮件)
P(房地产,产权|垃圾邮件)
P(房地产,产权,贷款|垃圾邮件)
...
- 1
- 2
- 3
- 4
- 此时计算量就会变得很大,这种情况下,朴素贝叶斯算法就出现了,它假设每个特征都是独立的。那么,上述表达式就能表达为:
P(房地产|垃圾邮件)
P(产权|垃圾邮件)
P(贷款|垃圾邮件)
- 1
- 2
- 3
- 贝叶斯原理、贝叶斯分类模型、朴素贝叶斯的联系

2.2 基于特征概率化的分类思想
先简单回顾一下之前学过的可用于分类的算法,有逻辑回归、决策树,还有支持向量机。整体而言,它们实现的原理是存在差异的。
- 逻辑回归通过拟合曲线(或者学习超平面)实现分类;
- 决策树通过寻找最佳划分特征进而学习样本路径实现分类;
- 支持向量机通过寻找分类超平面进而最大化类别间隔实现分类;
- 朴素贝叶斯是通过特征概率来预测分类。
简单举个区分好人和坏人的例子。假设我们现在不知道他们之前的履历,只能根据他们的样貌特征来判断他们是好人还是坏人。如特征有:笑容、纹身、性别等。
那么对于决策树算法进行的好人和坏人分类的话,可能先看性别,因为它发现给定的带标签人群里面男的坏蛋特别多,这个特征眼下最能区分坏蛋和好人,然后按性别把一拨人分成两拨;接着看“笑”这个特征,因为它是接下来最有区分度的特征,然后把两拨人分成四拨;接下来看纹身,以此类推。最后发现好人要么在田里种地,要么在山上砍柴,要么在学堂读书。而坏人呢,要么在大街上溜达,要么在地下买卖白粉,要么在海里当海盗。这些个有次序的特征就像路上的一个个垫脚石(树的节点)一样,构成通往不同地方的路径(树的枝丫),这些不同路径的目的地(叶子)就是一个类别容器,包含了一类人。一个品行未知的人来了,按照其样貌特征顺序及其对应的特征值,不断走啊走,最后走到了农田或山上,那就是好人;走到了地下或大海,
而对于朴素贝叶斯算法而言,它是将特征概率化。举例来说,笑的特征可以区分为好人的笑和坏人的笑,如“甜美的笑”、“儒雅的笑”、“憨厚的笑”、“没心没肺的笑”、“微微一笑”是好人的笑的概率更大,而“阴险的笑”、“不屑的笑”、“色眯眯的笑”、“任我行似的笑”、“冷笑”、“皮笑肉不笑”是坏人的笑概率更大。基于此,朴素贝叶斯就是将特征进行概率化来进行好人和坏人分类的,如果“坏人模型”输出的概率值大一些,那这个人很有可能就是个大坏蛋了。
此处学习自:深入理解朴素贝叶斯(Naive Bayes)
2.3 朴素贝叶斯分类案例
2.3.1 离散数据案例
基于上述思想,下面以一个简单的案例,介绍朴素贝叶斯分类的工作原理。
数据如下:

确定特征如下:身高、体重、鞋码
确定目标如下:性别(C1:男、C2:女)
需求:求解以下特征数据的性别是男性还是女性
• A1:身高=高
• A2:体重=中
• A3:鞋码=中
实现:简单来说,我们仅需求解在该特征下是男性的概率,再求解在该特征下是女性的概率。然后进行比较,选择可能性大的作为结果。
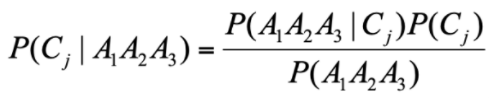
首先计算男性概率:
P(A1|C1) = 1/2
p(A2|C1) = 1/2
p(A3|C1) = 1/4
P(A1A2A3|Cj) = 1/16
- 1
- 2
- 3
- 4
- 5
同理计算女性概率。
2.3.2 连续数据案例
数据如下:

需求:求解以下特征数据的性别是男性还是女性
• 身高:180
• 体重:120
• 鞋码:41
实现:
• 假设男性和女性的身高、体重、鞋码都是正态分布
• 通过样本计算出均值和方差,也就是得到正态分布的密度函数
• 有了密度函数,就可以把值代入,算出某一点的密度函数的值
import numpy as np
import pandas as pd
df = pd.read_excel('table_data.xlsx',sheet_name="Sheet3",index_col=0)
df
- 1
- 2
- 3
- 4
"""
x 与 均值 与 方差
"""
df2 = df.groupby("性别").agg([np.mean,np.var])
df2
- 1
- 2
- 3
- 4
- 5
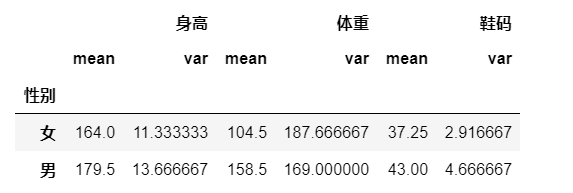
""" 男性 各个特征的 均值 与 方差 """ male_high_mean = df2.loc["男","身高"]["mean"] male_high_var = df2.loc["男","身高"]["var"] male_weight_mean = df2.loc["男","体重"]["mean"] male_weight_var = df2.loc["男","体重"]["var"] male_code_mean = df2.loc["男","鞋码"]["mean"] male_code_var = df2.loc["男","鞋码"]["var"] """ 构建男性特征的正态分布曲线,输入特征值下是男性的概率 """ from scipy import stats male_high_p = stats.norm.pdf(180,male_high_mean,male_high_var) male_weight_p = stats.norm.pdf(120,male_weight_mean,male_weight_var) male_code_p = stats.norm.pdf(41,male_code_mean,male_code_var)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
""" 女性 各个特征的 均值 与 方差 """ female_high_mean = df2.loc["女","身高"]["mean"] female_high_var = df2.loc["女","身高"]["var"] female_weight_mean = df2.loc["女","体重"]["mean"] female_weight_var = df2.loc["女","体重"]["var"] female_code_mean = df2.loc["女","鞋码"]["mean"] female_code_var = df2.loc["女","鞋码"]["var"] """ 构建女性特征的正态分布曲线,输入特征值下是女性的概率 """ from scipy import stats female_high_p = stats.norm.pdf(180,female_high_mean,female_high_var) female_weight_p = stats.norm.pdf(120,female_weight_mean,female_weight_var) female_code_p = stats.norm.pdf(41,female_code_mean,female_code_var)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
# 比较是男性概率高还是女性的概率高
male_high_p*male_weight_p*male_code_p > female_high_p*female_weight_p*female_code_p # True
- 1
- 2
3 朴素贝叶斯分类应用
朴素贝叶斯分类最适合的场景就是文本分类、情感分析和垃圾邮件识别。其中情感分析和垃圾邮件识别都是通过文本来进行判断。从这里你能看出来,这三个场景本质上都是文本分类,这也是朴素贝叶斯最擅长的地方。所以朴素贝叶斯也常用于自然语言处理 NLP 的工具。
3.1 sklearn 机器学习包
sklearn 的全称叫 Scikit-learn,它给我们提供了 3 个朴素贝叶斯分类算法,分别是高斯朴素贝叶斯(GaussianNB)、多项式朴素贝叶斯(MultinomialNB)和伯努利朴素贝叶斯(BernoulliNB)。
这三种算法适合应用在不同的场景下,我们应该根据特征变量的不同选择不同的算法:
- 高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
- 多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
- 伯努利朴素贝叶斯:特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现。
3.2 朴素贝叶斯算法实现新闻分类
import pandas as pd import numpy as np """ 1 数据描述性统计 """ """ - 样本数据:5000条 5000则新闻 - 字段:4个 - 标签:category-->分类 - 特征:content-->特征。将content进行分词统计出高频词汇再来预测新闻类别。 - 特征:每个高频词汇 - theme-->主题 - URL-->链接 - 有无缺失值:无。 """ df_news = pd.read_table('data.txt',names=['category','theme','URL','content'],encoding='utf-8') df_news.info() df_news.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

"""
标签分类共多少: 科技、健康、文化、汽车等
"""
df_news.category.value_counts()
- 1
- 2
- 3
- 4
""" 2.提取有价值的词汇——特征 """ import jieba """ 需求: jieba.cut(sentence)-->参数需为字符串 问题:df的content列,每一条新闻取出 """ # 取出content-->list content_list = df_news.content.values.tolist() # content_list[1000] # 二维的列表 [[每一条新闻分词后的列表数据],[第二条...]] content_seg = [] # 循环遍历每条content内容 进行分词 for line in content_list: # 分词 seg_line = list(jieba.cut(line)) if len(seg_line)>1: content_seg.append(seg_line) # print(content_seg[1000])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
"""
构建df数组
"""
df_content = pd.DataFrame({"content_seg":content_seg})
df_content
- 1
- 2
- 3
- 4
- 5

""" 3 数据清洗——停用词 每一条分词后的新闻词汇中,每个词汇都对文件分类有意义嘛? 比如常用词"真正"、"意义"、"等下"...这些常用词,可能会大量的出现在你的新闻当中,但是他对你进行文件分类无意义。可能还会干扰你的文件分类。 这些就是停用词!!!所以,接下来就需要清洗停用词。 """ """ 如果新闻当中的词汇在停用词文件中出现-->是否是停用词 - 是:则跳过 - 不是:添加 """ # 注意:加上quoting # 原因:当你用read_csv读文件的时候,如果文本里包含英文双引号,直接读取会导致行数变少或是直接如下报错停止,因此要加入quoting=3 stopwords = pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'],encoding='utf8') stopwords.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
# 取出 分词后 的新闻内容数据 [["词1","词2"],[...]...] # df_content.content_seg.values.tolist()[1000] # 停用词的提取 一维 # stopwords.stopword.values.tolist()[5] # 去除停用词 def drop_stopwords(contents,stopwords): contents_clean = [] # 循环取出每一条新闻内容 for line in contents: line_clean = [] # 取出每一条新闻中 每个词汇 for word in line: # 判断 word是否在停用词列表中 if word in stopwords: # 在,则跳过 continue line_clean.append(word) contents_clean.append(line_clean) return contents_clean
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
contents = df_content.content_seg.values.tolist() # 二维
stopwords = stopwords.stopword.values.tolist() # 一维
contents_clean = drop_stopwords(contents,stopwords)
contents_clean[1000]
- 1
- 2
- 3
- 4
"""
4 构建 特征 与 标签 数据
"""
df_train = pd.DataFrame({"content_clean":contents_clean,"label":df_news["category"]})
df_train.head()
- 1
- 2
- 3
- 4
- 5
""" 问题:标签还是字符串,做映射为数值。比如:汽车替换为1 财经替换为2... 实现:pandas中的map方法可以实现 - 构建映射字典 {"汽车":1} - 实现映射 """ # 获取唯一的类别列表 df_category = df_train.label.unique() # df_category # {"汽车":1} # dict-->映射 [(汽车,1),(财经,2)] label_mapping = dict(list(zip(df_category,list(range(1,len(df_category)+1))))) # label_mapping df_train["label_d"] = df_train["label"].map(label_mapping) df_train.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
"""
5 数据分割
"""
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(df_train["content_clean"].values,df_train["label_d"].values,random_state=1)
- 1
- 2
- 3
- 4
- 5
"""
问题:特征词汇仍然为字符串,并没有转为频次。怎么实现?
CountVectorizer,就是统计词频。 中文特征提取就需要使用空格分割 如["1文章第1词 1文章第2词","2文章..."]
"""
words = []
for line_index in range(len(x_train)):
# print(x_train[line_index]) # []
words.append(" ".join(x_train[line_index]))
words[0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer(analyzer='word',max_features=4000,lowercase=False) # analyzer : 一般使用默认,可设置为string类型,如’word’, ‘char’, ‘char_wb’,还可设置为callable类型,比如函数是一个callable类型 # lowercase: 将所有字符变成小写 # max_features:默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集 # 更多的参数详解可以学习:sklearn——CountVectorizer详解 https://blog.csdn.net/liuerin/article/details/91492708 vec_fit = vec.fit_transform(words) print(vec.get_feature_names()) # 列表形式呈现文章生成的词典 print(vec.vocabulary_) # 字典形式呈现,key:词,value:词频 print(vec_fit.toarray()) # 是将结果转化为稀疏矩阵矩阵的表示方式; print(vec_fit.toarray().sum(axis=0)) #每个词在所有文档中的词频
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
""" 6 模型训练 """ from sklearn.naive_bayes import MultinomialNB # 朴素贝叶斯算法中的多项式朴素贝叶斯(MultinomialNB # 训练 bys_class = MultinomialNB() bys_class.fit(vec_fit,y_train) # 训练集特征词汇,训练集目标 # 测试 test_words = [] for line_index in range(len(x_test)): # print(x_train[line_index]) # [] test_words.append(" ".join(x_test[line_index])) bys_class.predict(vec.transform(test_words)) # 评分 bys_class.score(vec.transform(test_words),y_test) #0.804
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
"""
7 基于TF-IDF的特征词频计算: geng hao de ci pin te zheng ji suan
"""
from sklearn.feature_extraction.text import TfidfVectorizer
tf_vec = TfidfVectorizer(analyzer='word',max_features=4000,lowercase=False)
tf_vec.fit(words)
bys_class2 = MultinomialNB()
bys_class2.fit(tf_vec.transform(words),y_train)
bys_class2.score(tf_vec.transform(test_words),y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

