
热门标签
热门文章
- 1一、教程 3. 高级功能 3.5. 窗口函数 3.6. 继承(Inheritance)
- 2signature=4e911ba6fe674e62558b0550dae858e4,diacritice-js/yarn.lock at master · mitica/diacritice-js ...
- 3Golang---TCP_golang io.copy tcp连接
- 4训练Stable Diffusion(XL) Lora的图片是否需要caption?_lora 训练图片的caption
- 52019前端最全面试题一(基础)_丨′77、卩’p∴11。99丨γ丨戈ⅸ↑x1719刂’′ⅰ1↑7|7<{|↖ 8f
- 6资深猎头解密:什么样的简历一投就中?_猎头提供简历爬虫
- 7在MySQL中数据库分为哪几种_数据库可分为哪几种类型?( ABC ) 数据库可分为哪几种类型?( ABC ) 数据库可以分为哪几种...
- 8探索PyTorch的自然语言处理的高级特技
- 9使用paddleocr进行文字识别_paddleocr实现文字识别
- 10刚刚!Stable diffusion 2024升级版终于来了!(无需安装,解压即用)
当前位置: article > 正文
自然语言处理学习 nltk----分词_分词 nltk 符号
作者:我家小花儿 | 2024-06-17 04:13:37
赞
踩
分词 nltk 符号
1. nltk.word_tokenize ( text ) : 直接的分词,比如:“ isn't ” 被分割为 " is " 和 “ n't ”

2. WordPunctTokenizer ( ) : 单词标点分割,比如:“ isn't ”被分割为" isn ", " ' " 和 " t "
注意WordPunctTokenizer ( )的用法。

3. TreebankWordTokenizer ( 宾夕法尼亚州立大学 Treebank 单词分割器):比如:" isn't "被分割为" is " 和 " n't "

4. WhitespaceTokenizer() : 空格符号分割,就是split(' ')最简单的一个整体,没有被分割

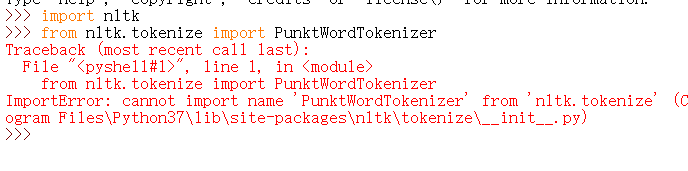
5. PunktWordTokenizer() :
这个有问题,emmmm,还没解决,先留个坑吧

本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

