
热门标签
热门文章
- 1ICRA 2021 Paper List_icra2021
- 22023年网络安全HW攻防技术总结(珍藏版)_hw攻击队
- 36-闭包和装饰器_带参数的装饰器。定义一个没有参数的函数foo,用于输出语句;定义一个装饰器函
- 4Oracle的rollup、cube、grouping sets函数
- 5使用 Python 指纹识别远程操作系统_python 通过ip地址获取指纹打卡机的数据的方法
- 6PyTorch源码解读之torchvision.transforms_pytorch_android_torchvision源码
- 7SylixOS动态加载器系列文章(6) C++支持_exidx段
- 8在主引导程序中打印字符串,读取软盘数据_可引导asm程序读取软盘
- 9python正则表达式
- 10Arduino ESP32 flash数据存储结构_esp32使用flash存储
当前位置: article > 正文
【论文精读-代码生成】Structured Chain-of-Thought Prompting for Code Generation
作者:我家小花儿 | 2024-04-05 04:22:33
赞
踩
【论文精读-代码生成】Structured Chain-of-Thought Prompting for Code Generation
动机
(思维链在大模型自动生成代码领域的扩展应用)
源代码包含丰富的结构信息,任何代码都可以由三种程序结构(即序列、分支和循环结构)组成。直观地说,结构化的中间推理步骤造就了结构化的源代码。因此,我们要求 LLM 使用程序结构构建 CoT,得到 SCoT。然后,LLMs 根据 SCoT 生成最终代码。与 CoT prompting 相比,SCoT prompting 明确约束 LLMs 从源代码的角度思考如何解决需求,进一步提高了 LLMs 在代码生成中的性能。
做了什么
- 本文提出一种结构化思维链(SCoT),利用程序结构来构建中间推理步骤。
- 提出了一种用于代码生成的SCoT提示技术。它提示大型语言模型首先生成一个SCoT,然后实现代码。
- 在三个基准上进行了广泛的实验。定性和定量实验表明,SCoT prompting明显优于SOTA基线(e.g.,思维链提示)。
- 讨论了不同程序结构的贡献和SCoT prompting的健壮性。
怎么做的
- SCoT提示流程:
- 编写示例二元组–<requirement, SCoT> ,要求这些例子涵盖了三个基本的程序结构和输入输出结构。再提出一个新需求,送入llm。我们希望llm从示例中学习并为新需求生成一个SCoT。

- 生成一个SCoT后,设计第二个用于生成最终代码的prompt:需求和对应的SCoT。提示以三个示例<requirement, SCoT, code>开始,要求LLM从示例中学习,并根据需求和SCoT生成一个新程序。
- 相关工作[25]发现生成模型可能会受到误差累积的负面影响。类似地,在SCoT prompting中,生成的SCoT可能包含噪声(e.g., 错误或遗漏步骤)。这些噪声将进一步对代码实现产生负面影响。本文利用两种方法来缓解误差累积:
- 要求llm再次检查SCoT并修复可能的噪音,允许llm自适应地引用SCoT并滤除噪声。

- 人类开发人员可以首先检查生成的SCoT并修复可能的错误。然后,使用SCoT生成代码。(人机交互)
- 要求llm再次检查SCoT并修复可能的噪音,允许llm自适应地引用SCoT并滤除噪声。
实验设计
评价方法
- 实验数据集:
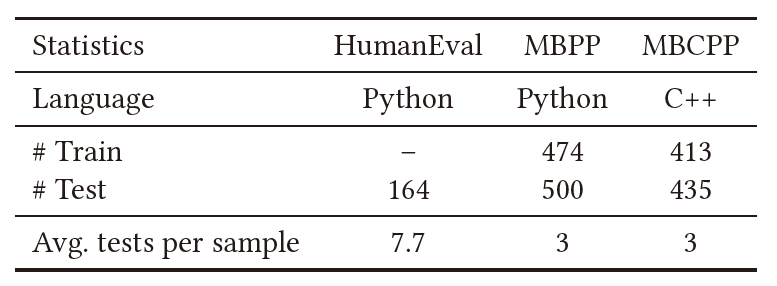
- HumanEval[7]是一个Python函数级代码生成基准测试,包含164个手写编程问题。每个编程问题由一个英语要求、一个函数签名和几个测试用例组成,平均每个问题有7.7个测试用例。由于HumanEval不包含训练数据,因此在HumanEval中重用了MBPP的示例。
- MBPP[2]是一个Python函数级代码生成基准测试。它包含974个编程问题,涉及简单的数值操作或标准库的基本使用。每个问题包含一个英语要求、一个函数签名和三个用于检查函数的手动编写的测试用例。
- MBCPP[1]是一个c++函数级代码生成基准测试。它由848个通过众包收集的编程问题组成。每个问题包含一个英文描述、一个函数签名和三个用于检查函数正确性的测试用例。
- 评价指标:无偏Pass@k
- Pass@k:给定一个需求,允许代码生成模型生成k个程序。如果生成的程序中任意一个通过了所有测试用例,那么这个需求就得到了解决。我们通过Pass@k计算已解决需求在总需求中的百分比。对于Pass@k,值越高越好。在我们的实验中,k被设置为1、3和5,因为我们认为开发人员在现实场景中主要使用Top-5输出。
- 无偏Pass@k:之前的工作发现标准通过@声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/363308
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

