
- 1MIPS指令集 指令的格式_mips指令格式
- 2C# List<T>的 Find方法、FindLast方法、FindAll方法、FindIndex方法_list findlast
- 3HormonyOS-DevEco Studio新建空项目ERROR解决_\node_modules\@ohos\hvigor\bin\hvigor.js
- 4jieba库中基于 TextRank 算法的关键词抽取——源代码分析(七)_jieba使用textrank
- 5产品经理必备软件,工作游刃有余_产品经理必备软件 csdn
- 6Kaggle 新手入门必看,手把手教学_kaggle amp
- 7华为新版ENSP PRO模拟器测评:性能表现与功能扩展一览_华为模拟器
- 8Android studio下载、安装及新建一个简单的安卓项目并在手机模拟器里运行_android studio下载手机模拟器
- 9【计算机组成原理】强制类型转换_signed short 强制转换为signed long
- 10wpf柱状图等相关技术_wpf charting 柱状图
NLP-分词、词性标注及命名实体识别(二):TextRank原理及应用_关键词 textrank 专业名词
赞
踩
一、TextRank原理
TextRank不需要大量标注样本,就可提取出文本相关词,其类似于PageRank思想,将文本的语法单元视作图中节点,如果两个语法单元存在一定语法关系(例如共现),其论文为:Rada Mihalcea的《TextRank:Bring Order into texts》。若将文本中语法单元视作图的节点,如果两个语法单元存在一定的语法关系(例如共现),则这两个语法单元在途中就会有一条边相互连接,通过一定的迭代次数,最终不同节点就会有不同的权重,权重高的语法单元就可以视为关键词。
节点的权重不仅依赖于其入度节点(百度之于好123),还依赖于度节点的权重,入度节点越多,入度的权重就越大,说明这个节点的权重越高:途中任意两点Vi,Vj之间的边权重为Wji,对于一个给定的点Vi,In(Vi)为指向该点的集合,Out(Vi)为点Vi指向点的集合。
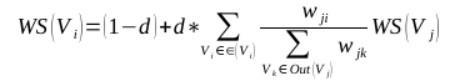
其中,d为阻尼系数,取值范围为0到1,代表从途中某一特定点指向其他任意点的概率,一般取值为0.85。使用TextRank算法计算图中各点的得分时,需要给图中的点指定任意的初值,并递归计算直到收敛,即图中任意点的误差率小于给定的极限值就可以达到收敛,一般该极限值取0.0001,算法通用流程:
1. 预处理,首先进行分词和词性标注,将单个word作为结点添加到图中;
2.设置语法过滤器,将通过语法过滤器的词汇添加到图中,出现在一个窗口中的词汇之间相互形成一条边;
3.基于上述公式,迭代直至收敛,一般迭代20-30次,迭代阈值设置为0.0001;
4.根据顶点的分数降序排列,并输出指定个数的词汇作为可能的关键词;
5.后处理,如果两个词汇在文本前后链接,

